82 Data Mining Essay Topic Ideas & Examples
🏆 best data mining topic ideas & essay examples, 💡 good essay topics on data mining, ✅ most interesting data mining topics to write about.
- Disadvantages of Using Web 2.0 for Data Mining Applications This data can be confusing to the readers and may not be reliable. Lastly, with the use of Web 2.
- Data Mining and Its Major Advantages Thus, it is possible to conclude that data mining is a convenient and effective way of processing information, which has many advantages.
- The Data Mining Method in Healthcare and Education Thus, I would use data mining in both cases; however, before that, I would discover a way to improve the algorithms used for it.
- Data Mining Tools and Data Mining Myths The first problem is correlated with keeping the identity of the person evolved in data mining secret. One of the major myths regarding data mining is that it can replace domain knowledge.
- Hybrid Data Mining Approach in Healthcare One of the healthcare projects that will call for the use of data mining is treatment evaluation. In this case, it is essential to realize that the main aim of health data mining is to […]
- Terrorism and Data Mining Algorithms However, this is a necessary evil as the nation’s security has to be prioritized since these attacks lead to harm to a larger population compared to the infringements.
- Transforming Coded and Text Data Before Data Mining However, to complete data mining, it is necessary to transform the data according to the techniques that are to be used in the process.
- Data Mining and Machine Learning Algorithms The shortest distance of string between two instances defines the distance of measure. However, this is also not very clear as to which transformations are summed, and thus it aims to a probability with the […]
- Summary of C4.5 Algorithm: Data Mining 5 algorism: Each record from set of data should be associated with one of the offered classes, it means that one of the attributes of the class should be considered as a class mark.
- Data Mining in Social Networks: Linkedin.com One of the ways to achieve the aim is to understand how users view data mining of their data on LinkedIn.
- Ethnography and Data Mining in Anthropology The study of cultures is of great importance under normal circumstances to enhance the understanding of the same. Data mining is the success secret of ethnography.
- Issues With Data Mining It is necessary to note that the usage of data mining helps FBI to have access to the necessary information for terrorism and crime tracking.
- Large Volume Data Handling: An Efficient Data Mining Solution Data mining is the process of sorting huge amount of data and finding out the relevant data. Data mining is widely used for the maintenance of data which helps a lot to an organization in […]
- Data Mining and Analytical Developments In this era where there is a lot of information to be handled at ago and actually with little available time, it is necessarily useful and wise to analyze data from different viewpoints and summarize […]
- Levi’s Company’s Data Mining & Customer Analytics Levi, the renowned name in jeans is feeling the heat of competition from a number of other brands, which have come upon the scene well after Levi’s but today appear to be approaching Levi’s market […]
- Cryptocurrency Exchange Market Prediction and Analysis Using Data Mining and Artificial Intelligence This paper aims to review the application of A.I.in the context of blockchain finance by examining scholarly articles to determine whether the A.I.algorithm can be used to analyze this financial market.
- “Data Mining and Customer Relationship Marketing in the Banking Industry“ by Chye & Gerry First of all, the article generally elaborates on the notion of customer relationship management, which is defined as “the process of predicting customer behavior and selecting actions to influence that behavior to benefit the company”.
- Data Mining Techniques and Applications The use of data mining to detect disturbances in the ecosystem can help to avert problems that are destructive to the environment and to society.
- Ethical Data Mining in the UAE Traffic Department The research question identified in the assignment two is considered to be the following, namely whether the implementation of the business intelligence into the working process will beneficially influence the work of the Traffic Department […]
- Canadian University Dubai and Data Mining The aim of mining data in the education environment is to enhance the quality of education for the mass through proactive and knowledge-based decision-making approaches.
- Data Mining and Customer Relationship Management As such, CRM not only entails the integration of marketing, sales, customer service, and supply chain capabilities of the firm to attain elevated efficiencies and effectiveness in conveying customer value, but it obliges the organization […]
- E-Commerce: Mining Data for Better Business Intelligence The method allowed the use of Intel and an example to build the study and the literature on data mining for business intelligence to analyze the findings.
- Ethical Implications of Data Mining by Government Institutions Critics of personal data mining insist that it infringes on the rights of an individual and result to the loss of sensitive information.
- Data Mining Role in Companies The increasing adoption of data mining in various sectors illustrates the potential of the technology regarding the analysis of data by entities that seek information crucial to their operations.
- Data Warehouse and Data Mining in Business The circumstances leading to the establishment and development of the concept of data warehousing was attributed to the fact that failure to have a data warehouse led to the need of putting in place large […]
- Data Mining: Concepts and Methods Speed of data mining process is important as it has a role to play in the relevance of the data mined. The accuracy of data is also another factor that can be used to measure […]
- Data Mining Technologies According to Han & Kamber, data mining is the process of discovering correlations, patterns, trends or relationships by searching through a large amount of data that in most circumstances is stored in repositories, business databases […]
- Data Mining: A Critical Discussion In recent times, the relatively new discipline of data mining has been a subject of widely published debate in mainstream forums and academic discourses, not only due to the fact that it forms a critical […]
- Commercial Uses of Data Mining Data mining process entails the use of large relational database to identify the correlation that exists in a given data. The principal role of the applications is to sift the data to identify correlations.
- A Discussion on the Acceptability of Data Mining Today, more than ever before, individuals, organizations and governments have access to seemingly endless amounts of data that has been stored electronically on the World Wide Web and the Internet, and thus it makes much […]
- Applying Data Mining Technology for Insurance Rate Making: Automobile Insurance Example
- Applebee’s, Travelocity and Others: Data Mining for Business Decisions
- Applying Data Mining Procedures to a Customer Relationship
- Business Intelligence as Competitive Tool of Data Mining
- Overview of Accounting Information System Data Mining
- Applying Data Mining Technique to Disassembly Sequence Planning
- Approach for Image Data Mining Cultural Studies
- Apriori Algorithm for the Data Mining of Global Cyberspace Security Issues
- Database Data Mining: The Silent Invasion of Privacy
- Data Management: Data Warehousing and Data Mining
- Constructive Data Mining: Modeling Consumers’ Expenditure in Venezuela
- Data Mining and Its Impact on Healthcare
- Innovations and Perspectives in Data Mining and Knowledge Discovery
- Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection
- Linking Data Mining and Anomaly Detection Techniques
- Data Mining and Pattern Recognition Models for Identifying Inherited Diseases
- Credit Card Fraud Detection Through Data Mining
- Data Mining Approach for Direct Marketing of Banking Products
- Constructive Data Mining: Modeling Argentine Broad Money Demand
- Data Mining-Based Dispatching System for Solving the Pickup and Delivery Problem
- Commercially Available Data Mining Tools Used in the Economic Environment
- Data Mining Climate Variability as an Indicator of U.S. Natural Gas
- Analysis of Data Mining in the Pharmaceutical Industry
- Data Mining-Driven Analysis and Decomposition in Agent Supply Chain Management Networks
- Credit Evaluation Model for Banks Using Data Mining
- Data Mining for Business Intelligence: Multiple Linear Regression
- Cluster Analysis for Diabetic Retinopathy Prediction Using Data Mining Techniques
- Data Mining for Fraud Detection Using Invoicing Data
- Jaeger Uses Data Mining to Reduce Losses From Crime and Waste
- Data Mining for Industrial Engineering and Management
- Business Intelligence and Data Mining – Decision Trees
- Data Mining for Traffic Prediction and Intelligent Traffic Management System
- Building Data Mining Applications for CRM
- Data Mining Optimization Algorithms Based on the Swarm Intelligence
- Big Data Mining: Challenges, Technologies, Tools, and Applications
- Data Mining Solutions for the Business Environment
- Overview of Big Data Mining and Business Intelligence Trends
- Data Mining Techniques for Customer Relationship Management
- Classification-Based Data Mining Approach for Quality Control in Wine Production
- Data Mining With Local Model Specification Uncertainty
- Employing Data Mining Techniques in Testing the Effectiveness of Modernization Theory
- Enhancing Information Management Through Data Mining Analytics
- Evaluating Feature Selection Methods for Learning in Data Mining Applications
- Extracting Formations From Long Financial Time Series Using Data Mining
- Financial and Banking Markets and Data Mining Techniques
- Fraudulent Financial Statements and Detection Through Techniques of Data Mining
- Harmful Impact Internet and Data Mining Have on Society
- Informatics, Data Mining, Econometrics, and Financial Economics: A Connection
- Integrating Data Mining Techniques Into Telemedicine Systems
- Investigating Tobacco Usage Habits Using Data Mining Approach
- Electronics Engineering Paper Topics
- Cyber Security Topics
- Google Paper Topics
- Hacking Essay Topics
- Identity Theft Essay Ideas
- Internet Research Ideas
- Microsoft Topics
- Chicago (A-D)
- Chicago (N-B)
IvyPanda. (2024, March 2). 82 Data Mining Essay Topic Ideas & Examples. https://ivypanda.com/essays/topic/data-mining-essay-topics/
"82 Data Mining Essay Topic Ideas & Examples." IvyPanda , 2 Mar. 2024, ivypanda.com/essays/topic/data-mining-essay-topics/.
IvyPanda . (2024) '82 Data Mining Essay Topic Ideas & Examples'. 2 March.
IvyPanda . 2024. "82 Data Mining Essay Topic Ideas & Examples." March 2, 2024. https://ivypanda.com/essays/topic/data-mining-essay-topics/.
1. IvyPanda . "82 Data Mining Essay Topic Ideas & Examples." March 2, 2024. https://ivypanda.com/essays/topic/data-mining-essay-topics/.
Bibliography
IvyPanda . "82 Data Mining Essay Topic Ideas & Examples." March 2, 2024. https://ivypanda.com/essays/topic/data-mining-essay-topics/.

data mining Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Distance Based Pattern Driven Mining for Outlier Detection in High Dimensional Big Dataset
Detection of outliers or anomalies is one of the vital issues in pattern-driven data mining. Outlier detection detects the inconsistent behavior of individual objects. It is an important sector in the data mining field with several different applications such as detecting credit card fraud, hacking discovery and discovering criminal activities. It is necessary to develop tools used to uncover the critical information established in the extensive data. This paper investigated a novel method for detecting cluster outliers in a multidimensional dataset, capable of identifying the clusters and outliers for datasets containing noise. The proposed method can detect the groups and outliers left by the clustering process, like instant irregular sets of clusters (C) and outliers (O), to boost the results. The results obtained after applying the algorithm to the dataset improved in terms of several parameters. For the comparative analysis, the accurate average value and the recall value parameters are computed. The accurate average value is 74.05% of the existing COID algorithm, and our proposed algorithm has 77.21%. The average recall value is 81.19% and 89.51% of the existing and proposed algorithm, which shows that the proposed work efficiency is better than the existing COID algorithm.
Implementation of Data Mining Technology in Bonded Warehouse Inbound and Outbound Goods Trade
For the taxed goods, the actual freight is generally determined by multiplying the allocated freight for each KG and actual outgoing weight based on the outgoing order number on the outgoing bill. Considering the conventional logistics is insufficient to cope with the rapid response of e-commerce orders to logistics requirements, this work discussed the implementation of data mining technology in bonded warehouse inbound and outbound goods trade. Specifically, a bonded warehouse decision-making system with data warehouse, conceptual model, online analytical processing system, human-computer interaction module and WEB data sharing platform was developed. The statistical query module can be used to perform statistics and queries on warehousing operations. After the optimization of the whole warehousing business process, it only takes 19.1 hours to get the actual freight, which is nearly one third less than the time before optimization. This study could create a better environment for the development of China's processing trade.
Multi-objective economic load dispatch method based on data mining technology for large coal-fired power plants
User activity classification and domain-wise ranking through social interactions.
Twitter has gained a significant prevalence among the users across the numerous domains, in the majority of the countries, and among different age groups. It servers a real-time micro-blogging service for communication and opinion sharing. Twitter is sharing its data for research and study purposes by exposing open APIs that make it the most suitable source of data for social media analytics. Applying data mining and machine learning techniques on tweets is gaining more and more interest. The most prominent enigma in social media analytics is to automatically identify and rank influencers. This research is aimed to detect the user's topics of interest in social media and rank them based on specific topics, domains, etc. Few hybrid parameters are also distinguished in this research based on the post's content, post’s metadata, user’s profile, and user's network feature to capture different aspects of being influential and used in the ranking algorithm. Results concluded that the proposed approach is well effective in both the classification and ranking of individuals in a cluster.
A data mining analysis of COVID-19 cases in states of United States of America
Epidemic diseases can be extremely dangerous with its hazarding influences. They may have negative effects on economies, businesses, environment, humans, and workforce. In this paper, some of the factors that are interrelated with COVID-19 pandemic have been examined using data mining methodologies and approaches. As a result of the analysis some rules and insights have been discovered and performances of the data mining algorithms have been evaluated. According to the analysis results, JRip algorithmic technique had the most correct classification rate and the lowest root mean squared error (RMSE). Considering classification rate and RMSE measure, JRip can be considered as an effective method in understanding factors that are related with corona virus caused deaths.
Exploring distributed energy generation for sustainable development: A data mining approach
A comprehensive guideline for bengali sentiment annotation.
Sentiment Analysis (SA) is a Natural Language Processing (NLP) and an Information Extraction (IE) task that primarily aims to obtain the writer’s feelings expressed in positive or negative by analyzing a large number of documents. SA is also widely studied in the fields of data mining, web mining, text mining, and information retrieval. The fundamental task in sentiment analysis is to classify the polarity of a given content as Positive, Negative, or Neutral . Although extensive research has been conducted in this area of computational linguistics, most of the research work has been carried out in the context of English language. However, Bengali sentiment expression has varying degree of sentiment labels, which can be plausibly distinct from English language. Therefore, sentiment assessment of Bengali language is undeniably important to be developed and executed properly. In sentiment analysis, the prediction potential of an automatic modeling is completely dependent on the quality of dataset annotation. Bengali sentiment annotation is a challenging task due to diversified structures (syntax) of the language and its different degrees of innate sentiments (i.e., weakly and strongly positive/negative sentiments). Thus, in this article, we propose a novel and precise guideline for the researchers, linguistic experts, and referees to annotate Bengali sentences immaculately with a view to building effective datasets for automatic sentiment prediction efficiently.
Capturing Dynamics of Information Diffusion in SNS: A Survey of Methodology and Techniques
Studying information diffusion in SNS (Social Networks Service) has remarkable significance in both academia and industry. Theoretically, it boosts the development of other subjects such as statistics, sociology, and data mining. Practically, diffusion modeling provides fundamental support for many downstream applications (e.g., public opinion monitoring, rumor source identification, and viral marketing). Tremendous efforts have been devoted to this area to understand and quantify information diffusion dynamics. This survey investigates and summarizes the emerging distinguished works in diffusion modeling. We first put forward a unified information diffusion concept in terms of three components: information, user decision, and social vectors, followed by a detailed introduction of the methodologies for diffusion modeling. And then, a new taxonomy adopting hybrid philosophy (i.e., granularity and techniques) is proposed, and we made a series of comparative studies on elementary diffusion models under our taxonomy from the aspects of assumptions, methods, and pros and cons. We further summarized representative diffusion modeling in special scenarios and significant downstream tasks based on these elementary models. Finally, open issues in this field following the methodology of diffusion modeling are discussed.
The Influence of E-book Teaching on the Motivation and Effectiveness of Learning Law by Using Data Mining Analysis
This paper studies the motivation of learning law, compares the teaching effectiveness of two different teaching methods, e-book teaching and traditional teaching, and analyses the influence of e-book teaching on the effectiveness of law by using big data analysis. From the perspective of law student psychology, e-book teaching can attract students' attention, stimulate students' interest in learning, deepen knowledge impression while learning, expand knowledge, and ultimately improve the performance of practical assessment. With a small sample size, there may be some deficiencies in the research results' representativeness. To stimulate the learning motivation of law as well as some other theoretical disciplines in colleges and universities has particular referential significance and provides ideas for the reform of teaching mode at colleges and universities. This paper uses a decision tree algorithm in data mining for the analysis and finds out the influencing factors of law students' learning motivation and effectiveness in the learning process from students' perspective.
Intelligent Data Mining based Method for Efficient English Teaching and Cultural Analysis
The emergence of online education helps improving the traditional English teaching quality greatly. However, it only moves the teaching process from offline to online, which does not really change the essence of traditional English teaching. In this work, we mainly study an intelligent English teaching method to further improve the quality of English teaching. Specifically, the random forest is firstly used to analyze and excavate the grammatical and syntactic features of the English text. Then, the decision tree based method is proposed to make a prediction about the English text in terms of its grammar or syntax issues. The evaluation results indicate that the proposed method can effectively improve the accuracy of English grammar or syntax recognition.
Export Citation Format
Share document.

Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
Data mining articles within Scientific Reports
Article 18 June 2024 | Open Access
Expression characteristics of lipid metabolism-related genes and correlative immune infiltration landscape in acute myocardial infarction
- , Jingyi Luo
- & Xiaorong Hu
Article 17 June 2024 | Open Access
Multi role ChatGPT framework for transforming medical data analysis
- Haoran Chen
- , Shengxiao Zhang
- & Xuechun Lu
A tensor decomposition reveals ageing-induced differences in muscle and grip-load force couplings during object lifting
- , Seyed Saman Saboksayr
- & Ioannis Delis
Article 14 June 2024 | Open Access
Research on coal mine longwall face gas state analysis and safety warning strategy based on multi-sensor forecasting models
- Haoqian Chang
- , Xiangrui Meng
- & Zuxiang Hu
PDE1B, a potential biomarker associated with tumor microenvironment and clinical prognostic significance in osteosarcoma
- Qingzhong Chen
- , Chunmiao Xing
- & Zhongwei Qian
Article 13 June 2024 | Open Access
A real-world pharmacovigilance study on cardiovascular adverse events of tisagenlecleucel using machine learning approach
- Juhong Jung
- , Ju Hwan Kim
- & Ju-Young Shin
Article 12 June 2024 | Open Access
Alteration of circulating ACE2-network related microRNAs in patients with COVID-19
- Zofia Wicik
- , Ceren Eyileten
- & Marek Postula
DCRELM: dual correlation reduction network-based extreme learning machine for single-cell RNA-seq data clustering
- Qingyun Gao
- & Qing Ai
Article 10 June 2024 | Open Access
Multi-cohort analysis reveals immune subtypes and predictive biomarkers in tuberculosis
- & Hong Ding
Article 03 June 2024 | Open Access
Depression recognition using voice-based pre-training model
- Xiangsheng Huang
- , Fang Wang
- & Zhenrong Xu
Article 01 June 2024 | Open Access
Mitochondrial RNA modification-based signature to predict prognosis of lower grade glioma: a multi-omics exploration and verification study
- Xingwang Zhou
- , Yuanguo Ling
- & Liangzhao Chu
Article 31 May 2024 | Open Access
Decoding intelligence via symmetry and asymmetry
- Jianjing Fu
- & Ching-an Hsiao
Article 27 May 2024 | Open Access
Research on domain ontology construction based on the content features of online rumors
- Jianbo Zhao
- , Huailiang Liu
- & Ruiyu Ding
Exploring the pathways of drug repurposing and Panax ginseng treatment mechanisms in chronic heart failure: a disease module analysis perspective
- Chengzhi Xie
- , Ying Zhang
- & Na Lang
Article 22 May 2024 | Open Access
Comprehensive data mining reveals RTK/RAS signaling pathway as a promoter of prostate cancer lineage plasticity through transcription factors and CNV
- Guanyun Wei
- & Zao Dai
Article 21 May 2024 | Open Access
Anoikis-related gene signatures in colorectal cancer: implications for cell differentiation, immune infiltration, and prognostic prediction
- Taohui Ding
- , Zhao Shang
- & Bo Yi
Insights from modelling sixteen years of climatic and fumonisin patterns in maize in South Africa
- Sefater Gbashi
- , Oluwasola Abayomi Adelusi
- & Patrick Berka Njobeh
Article 17 May 2024 | Open Access
Identification of cancer risk groups through multi-omics integration using autoencoder and tensor analysis
- Ali Braytee
- & Ali Anaissi
Article 14 May 2024 | Open Access
Multi-omics integration of scRNA-seq time series data predicts new intervention points for Parkinson’s disease
- Katarina Mihajlović
- , Gaia Ceddia
- & Nataša Pržulj
Stellae-123 gene expression signature improved risk stratification in Taiwanese acute myeloid leukemia patients
- Yu-Hung Wang
- , Adrián Mosquera Orgueira
- & Hwei-Fang Tien
Article 06 May 2024 | Open Access
Joint extraction of wheat germplasm information entity relationship based on deep character and word fusion
- Xiaoxiao Jia
- , Guang Zheng
- & Lei Xi
Article 25 April 2024 | Open Access
Low ACADM expression predicts poor prognosis and suppressive tumor microenvironment in clear cell renal cell carcinoma
- & Huimin Long
Article 19 April 2024 | Open Access
Automatic inference of ICD-10 codes from German ophthalmologic physicians’ letters using natural language processing
- D. Böhringer
- , P. Angelova
- & T. Reinhard
Robust identification of interactions between heat-stress responsive genes in the chicken brain using Bayesian networks and augmented expression data
- E. A. Videla Rodriguez
- , John B. O. Mitchell
- & V. Anne Smith
Article 16 April 2024 | Open Access
Potential routes of plastics biotransformation involving novel plastizymes revealed by global multi-omic analysis of plastic associated microbes
- Rodney S. Ridley Jr
- , Roth E. Conrad
- & Konstantinos T. Konstantinidis
Article 13 April 2024 | Open Access
Identifying and overcoming COVID-19 vaccination impediments using Bayesian data mining techniques
- , Arvind Mahajan
- & Bani Mallick
Article 10 April 2024 | Open Access
A decision support system based on recurrent neural networks to predict medication dosage for patients with Parkinson's disease
- Atiye Riasi
- , Mehdi Delrobaei
- & Mehri Salari
Article 03 April 2024 | Open Access
A distributed feature selection pipeline for survival analysis using radiomics in non-small cell lung cancer patients
- Benedetta Gottardelli
- , Varsha Gouthamchand
- & Andrea Damiani
Article 02 April 2024 | Open Access
Characterization of a putative orexin receptor in Ciona intestinalis sheds light on the evolution of the orexin/hypocretin system in chordates
- Maiju K. Rinne
- , Lauri Urvas
- & Henri Xhaard
Multiomics analysis to explore blood metabolite biomarkers in an Alzheimer’s Disease Neuroimaging Initiative cohort
- , Yuki Matsuzawa
- & Balebail Ashok Raj
Article 01 April 2024 | Open Access
Information heterogeneity between progress notes by physicians and nurses for inpatients with digestive system diseases
- Yukinori Mashima
- , Masatoshi Tanigawa
- & Hideto Yokoi
Article 25 March 2024 | Open Access
Integrated image and location analysis for wound classification: a deep learning approach
- , Tirth Shah
- & Zeyun Yu
Article 19 March 2024 | Open Access
Persistence of collective memory of corporate bankruptcy events discussed on X (Twitter) is influenced by pre-bankruptcy public attention
- Kathleen M. Jagodnik
- , Sharon Dekel
- & Alon Bartal
Article 18 March 2024 | Open Access
Clustering analysis for the evolutionary relationships of SARS-CoV-2 strains
- Xiangzhong Chen
- , Mingzhao Wang
- & Juanying Xie
Article 15 March 2024 | Open Access
Development of phenotyping algorithms for hypertensive disorders of pregnancy (HDP) and their application in more than 22,000 pregnant women
- Satoshi Mizuno
- , Maiko Wagata
- & Soichi Ogishima
Article 13 March 2024 | Open Access
Predicting early Alzheimer’s with blood biomarkers and clinical features
- Muaath Ebrahim AlMansoori
- , Sherlyn Jemimah
- & Aamna AlShehhi
Article 09 March 2024 | Open Access
Sentiment analysis of video danmakus based on MIBE-RoBERTa-FF-BiLSTM
- & Shanzhuang Zhang
Article 05 March 2024 | Open Access
A new R package to parse plant species occurrence records into unique collection events efficiently reduces data redundancy
- Pablo Hendrigo Alves de Melo
- , Nadia Bystriakova
- & Alexandre K. Monro
Article 02 March 2024 | Open Access
Prediction of lncRNA and disease associations based on residual graph convolutional networks with attention mechanism
- Shengchang Wang
- , Jiaqing Qiao
- & Shou Feng
Article 01 March 2024 | Open Access
Analysis and visualisation of electronic health records data to identify undiagnosed patients with rare genetic diseases
- Daniel Moynihan
- , Sean Monaco
- & Saumya Shekhar Jamuar
Article 21 February 2024 | Open Access
Tuning attention based long-short term memory neural networks for Parkinson’s disease detection using modified metaheuristics
- , Timea Bezdan
- & Nebojsa Bacanin
Article 19 February 2024 | Open Access
Effects of different KRAS mutants and Ki67 expression on diagnosis and prognosis in lung adenocarcinoma
- , Liwen Dong
- & Pan Li
Article 15 February 2024 | Open Access
Identification of SLC40A1, LCN2, CREB5, and SLC7A11 as ferroptosis-related biomarkers in alopecia areata through machine learning
- , Dongfan Wei
- & Xiuzu Song
Article 07 February 2024 | Open Access
Unsupervised analysis of whole transcriptome data from human pluripotent stem cells cardiac differentiation
- Sofia P. Agostinho
- , Mariana A. Branco
- & Carlos A. V. Rodrigues
Article 03 February 2024 | Open Access
AI models for automated segmentation of engineered polycystic kidney tubules
- Simone Monaco
- , Nicole Bussola
- & Daniele Apiletti
Article 02 February 2024 | Open Access
Development and validation of a cuproptosis-related prognostic model for acute myeloid leukemia patients using machine learning with stacking
- Xichao Wang
- & Suning Chen
Article 30 January 2024 | Open Access
Assessing the feasibility of applying machine learning to diagnosing non-effusive feline infectious peritonitis
- Dawn Dunbar
- , Simon A. Babayan
- & William Weir
Article 29 January 2024 | Open Access
Survival prediction of glioblastoma patients using modern deep learning and machine learning techniques
- Samin Babaei Rikan
- , Amir Sorayaie Azar
- & Uffe Kock Wiil
Article 25 January 2024 | Open Access
Identification of gene signatures and molecular mechanisms underlying the mutual exclusion between psoriasis and leprosy
- You-Wang Lu
- , Rong-Jing Dong
- & Yu-Ye Li
Article 24 January 2024 | Open Access
Identification of shared pathogenetic mechanisms between COVID-19 and IC through bioinformatics and system biology
- Zhenpeng Sun
- & Jiangang Gao
Browse broader subjects
- Computational biology and bioinformatics
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

Trending Data Mining Thesis Topics
Data mining seems to be the act of analyzing large amounts of data in order to uncover business insights that can assist firms in fixing issues, reducing risks, and embracing new possibilities . This article provides a complete picture on data mining thesis topics where you can get all information regarding data mining research

How does data mining work?
- A standard data mining design begins with the appropriate business statement in the questionnaire, the appropriate data is collected to tackle it, and the data is prepared for the examination.
- What happens in the earlier stages determines how successful the later versions are.
- Data miners should assure the data quality they utilize as input for research because bad data quality results in poor outcomes.
- Establishing a detailed understanding of the design factors, such as the present business scenario, the project’s main business goal, and the performance objectives.
- Identifying the data required to address the problem as well as collecting this from all sorts of sources.
- Addressing any errors and bugs, like incomplete or duplicate data, and processing the data in a suitable format to solve the research questions.
- Algorithms are used to find patterns from data.
- Identifying if or how another model’s output will contribute to the achievement of a business objective.
- In order to acquire the optimum outcome, an iterative process is frequently used to identify the best method.
- Getting the project’s findings suitable for making decisions in real-time
The techniques and actions listed above are repeated until the best outcomes are achieved. Our engineers and developers have extensive knowledge of the tools, techniques, and approaches used in the processes described above. We guarantee that we will provide the best research advice w.r.t to data mining thesis topics and complete your project on schedule. What are the important data mining tasks?
Data Mining Tasks
- Data mining finds application in many ways including description, Analysis, summarization of data, and clarifying the conceptual understanding by data description
- And also prediction, classification, dependency analysis, segmentation, and case-based reasoning are some of the important data mining tasks
- Regression – numerical data prediction (stock prices, temperatures, and total sales)
- Data warehousing – business decision making and large-scale data mining
- Classification – accurate prediction of target classes and their categorization
- Association rule learning – market-based analytical tools that were involved in establishing variable data set relationship
- Machine learning – statistical probability-based decision making method without complicated programming
- Data analytics – digital data evaluation for business purposes
- Clustering – dataset partitioning into clusters and subclasses for analyzing natural data structure and format
- Artificial intelligence – human-based Data analytics for reasoning, solving problems, learning, and planning
- Data preparation and cleansing – conversion of raw data into a processed form for identification and removal of errors
You can look at our website for a more in-depth look at all of these operations. We supply you with the needed data, as well as any additional data you may need for your data mining thesis topics . We supply non-plagiarized data mining thesis assistance in any fresh idea of your choice. Let us now discuss the stages in data mining that are to be included in your thesis topics
How to work on a data mining thesis topic?
The following are the important stages or phases in developing data mining thesis topics.
- First of all, you need to identify the present demand and address the question
- The next step is defining or specifying the problem
- Collection of data is the third step
- Alternative solutions and designs have to be analyzed in the next step
- The proposed methodology has to be designed
- The system is then to be implemented
Usually, our experts help in writing codes and implementing them successfully without hassles . By consistently following the above steps you can develop one of the best data mining thesis topics of recent days. Furthermore, technically it is important for you to have a better idea of all the tasks and techniques involved in data mining about which we have discussed below
- Data visualization
- Neural networks
- Statistical modeling
- Genetic algorithms and neural networks
- Decision trees and induction
- Discriminant analysis
- Induction techniques
- Association rules and data visualization
- Bayesian networks
- Correlation
- Regression analysis
- Regression analysis and regression trees
If you are looking forward to selecting the best tool for your data mining project then evaluating its consistency and efficiency stands first. For this, you need to gain enough technical data from real-time executed projects for which you can directly contact us. Since we have delivered an ample number of data mining thesis topics successfully we can help you in finding better solutions to all your research issues. What are the points to be remembered about the data mining strategy?
- Furthermore, data mining strategies must be picked before instruments in order to prevent using strategies that do not align with the article’s true purposes.
- The typical data mining strategy has always been to evaluate a variety of methodologies in order to select one which best fits the situation.
- As previously said, there are some principles that may be used to choose effective strategies for data mining projects.
- Since they are easy to handle and comprehend
- They could indeed collaborate with definitional and parametric data
- Tare unaffected by critical values, they could perhaps function with incomplete information
- They could also expose various interrelationships and an absence of linear combinations
- They could indeed handle noise in records
- They can process huge amounts of data.
- Decision trees, on the other hand, have significant drawbacks.
- Many rules are frequently necessary for dependent variables or numerous regressions, and tiny changes in the data can result in very different tree architectures.
All such pros and cons of various data mining aspects are discussed on our website. We will provide you with high-quality research assistance and thesis writing assistance . You may see proof of our skill and the unique approach that we generated in the field by looking at the samples of the thesis that we produced on our website. We also offer an internal review to help you feel more confident. Let us now discuss the recent data mining methodologies
Current methods in Data Mining
- Prediction of data (time series data mining)
- Discriminant and cluster analysis
- Logistic regression and segmentation
Our technical specialists and technicians usually give adequate accurate data, a thorough and detailed explanation, and technical notes for all of these processes and algorithms. As a result, you can get all of your questions answered in one spot. Our technical team is also well-versed in current trends, allowing us to provide realistic explanations for all new developments. We will now talk about the latest data mining trends
Latest Trending Data Mining Thesis Topics
- Visual data mining and data mining software engineering
- Interaction and scalability in data mining
- Exploring applications of data mining
- Biological and visual data mining
- Cloud computing and big data integration
- Data security and protecting privacy in data mining
- Novel methodologies in complex data mining
- Data mining in multiple databases and rationalities
- Query language standardization in data mining
- Integration of MapReduce, Amazon EC2, S3, Apache Spark, and Hadoop into data mining
These are the recent trends in data mining. We insist that you choose one of the topics that interest you the most. Having an appropriate content structure or template is essential while writing a thesis . We design the plan in a chronological order relevant to the study assessment with this in mind. The incorporation of citations is one of the most important aspects of the thesis. We focus not only on authoring but also on citing essential sources in the text. Students frequently struggle to deal with appropriate proposals when commencing their thesis. We have years of experience in providing the greatest study and data mining thesis writing services to the scientific community, which are promptly and widely acknowledged. We will now talk about future research directions of research in various data mining thesis topics
Future Research Directions of Data Mining
- The potential of data mining and data science seems promising, as the volume of data continues to grow.
- It is expected that the total amount of data in our digital cosmos will have grown from 4.4 zettabytes to 44 zettabytes.
- We’ll also generate 1.7 gigabytes of new data for every human being on this planet each second.
- Mining algorithms have completely transformed as technology has advanced, and thus have tools for obtaining useful insights from data.
- Only corporations like NASA could utilize their powerful computers to examine data once upon a time because the cost of producing and processing data was simply too high.
- Organizations are now using cloud-based data warehouses to accomplish any kinds of great activities with machine learning, artificial intelligence, and deep learning.
The Internet of Things as well as wearable electronics, for instance, has transformed devices to be connected into data-generating engines which provide limitless perspectives into people and organizations if firms can gather, store, and analyze the data quickly enough. What are the aspects to be remembered for choosing the best data mining thesis topics?
- An excellent thesis topic is a broad concept that has to be developed, verified, or refuted.
- Your thesis topic must capture your curiosity, as well as the involvement of both the supervisor and the academicians.
- Your thesis topic must be relevant to your studies and should be able to withstand examination.
Our engineers and experts can provide you with any type of research assistance on any of these data mining development tools . We satisfy the criteria of your universities by ensuring several revisions, appropriate formatting and editing of your thesis, comprehensive grammar check, and so on . As a result, you can contact us with confidence for complete assistance with your data mining thesis. What are the important data mining thesis topics?

Research Topics in Data Mining
- Handling cost-effective, unbalanced non-static data
- Issues related to data mining and their solutions
- Network settings in data mining and ensuring privacy, security, and integrity of data
- Environmental and biological issues in data mining
- Complex data mining and sequential data mining (time series data)
- Data mining at higher dimensions
- Multi-agent data mining and distributed data mining
- High-speed data mining
- Development of unified data mining theory
We currently provide full support for all parts of research study, development, investigation, including project planning, technical advice, legitimate scientific data, thesis writing, paper publication, assignments and project planning, internal review, and many other services. As a result, you can contact us for any kind of help with your data mining thesis topics.
Why Work With Us ?
Senior research member, research experience, journal member, book publisher, research ethics, business ethics, valid references, explanations, paper publication, 9 big reasons to select us.
Our Editor-in-Chief has Website Ownership who control and deliver all aspects of PhD Direction to scholars and students and also keep the look to fully manage all our clients.
Our world-class certified experts have 18+years of experience in Research & Development programs (Industrial Research) who absolutely immersed as many scholars as possible in developing strong PhD research projects.
We associated with 200+reputed SCI and SCOPUS indexed journals (SJR ranking) for getting research work to be published in standard journals (Your first-choice journal).
PhDdirection.com is world’s largest book publishing platform that predominantly work subject-wise categories for scholars/students to assist their books writing and takes out into the University Library.
Our researchers provide required research ethics such as Confidentiality & Privacy, Novelty (valuable research), Plagiarism-Free, and Timely Delivery. Our customers have freedom to examine their current specific research activities.
Our organization take into consideration of customer satisfaction, online, offline support and professional works deliver since these are the actual inspiring business factors.
Solid works delivering by young qualified global research team. "References" is the key to evaluating works easier because we carefully assess scholars findings.
Detailed Videos, Readme files, Screenshots are provided for all research projects. We provide Teamviewer support and other online channels for project explanation.
Worthy journal publication is our main thing like IEEE, ACM, Springer, IET, Elsevier, etc. We substantially reduces scholars burden in publication side. We carry scholars from initial submission to final acceptance.
Related Pages
Our benefits, throughout reference, confidential agreement, research no way resale, plagiarism-free, publication guarantee, customize support, fair revisions, business professionalism, domains & tools, we generally use, wireless communication (4g lte, and 5g), ad hoc networks (vanet, manet, etc.), wireless sensor networks, software defined networks, network security, internet of things (mqtt, coap), internet of vehicles, cloud computing, fog computing, edge computing, mobile computing, mobile cloud computing, ubiquitous computing, digital image processing, medical image processing, pattern analysis and machine intelligence, geoscience and remote sensing, big data analytics, data mining, power electronics, web of things, digital forensics, natural language processing, automation systems, artificial intelligence, mininet 2.1.0, matlab (r2018b/r2019a), matlab and simulink, apache hadoop, apache spark mlib, apache mahout, apache flink, apache storm, apache cassandra, pig and hive, rapid miner, support 24/7, call us @ any time, +91 9444829042, [email protected].
Questions ?
Click here to chat with us
Advertisement
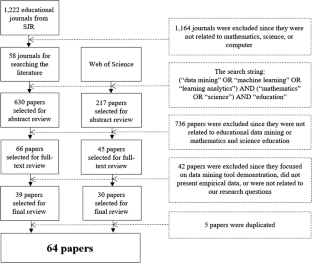
A Systematic Review on Data Mining for Mathematics and Science Education
- Published: 14 May 2020
- Volume 19 , pages 639–659, ( 2021 )
Cite this article

- Dongjo Shin 1 &
- Jaekwoun Shim 1
3422 Accesses
31 Citations
1 Altmetric
Explore all metrics
Educational data mining is used to discover significant phenomena and resolve educational issues occurring in the context of teaching and learning. This study provides a systematic literature review of educational data mining in mathematics and science education. A total of 64 articles were reviewed in terms of the research topics and data mining techniques used. This review revealed that data mining in mathematics and science education has been commonly used to understand students’ behavior and thinking process, identify factors affecting student achievements, and provide automated assessment of students’ written work. Recently, researchers have tended to use such data mining techniques as text mining to develop learning systems for supporting teachers’ instruction and students’ learning. We also found that classification, text mining, and clustering are major data mining techniques researchers have used. Studies using data mining were more likely to be conducted in the field of science education than in the field of mathematics education. We discuss the main results of our review in comparison with the previous reviews of educational data mining (EDM) literature and with EDM studies conducted in the context of science and mathematics education. Finally, we provide implications for research and teaching and learning of science and mathematics and suggest potential research directions.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

A Systematic Review of Educational Data Mining

A Study of Different Techniques in Educational Data Mining

Educational Data Mining: A Systematic Review of the Published Literature 2006-2013
Abidi, S., Hussain, M., Xu, Y., & Zhang, W. (2019). Prediction of confusion attempting algebra homework in an intelligent tutoring system through machine learning techniques for educational sustainable development. Sustainability . Advance online publication. https://doi.org/10.3390/su11010105 .
Aiken, J. M., Henderson, R., & Caballero, M. D. (2019). Modeling student pathways in a physics bachelor’s degree program. Physical Review Physics Education Research, Advance online publication . https://doi.org/10.1103/PhysRevPhysEducRes.15.010128 .
Akgün, E., & Demir, M. (2018). Modeling course achievements of elementary education teacher candidates with artificial neural networks. International Journal of Assessment Tools in Education, 5 (3), 491–509.
Article Google Scholar
Aksoy, E., Narli, S., & Idil, F. H. (2016). Using data mining techniques examination of the middle school students’ attitude towards mathematics in the context of some variables. International Journal of Education in Mathematics Science and Technology, 4 (3), 210–228.
Aldowah, H., Al-Samarraie, H., & Fauzy, W. M. (2019). Educational data mining and learning analytics for 21stcentury higher education: A review and synthesis. Telematics and Informatics, 37 , 13–46.
Araya, R., Jiménez, A., Bahamondez, M., Calfucura, P., Dartnell, P., & Soto-Andrade, J. (2014). Teaching modeling skills using a massively multiplayer online mathematics game. World Wide Web, 17 (2), 213–227.
Bağ, H., & Çalık, M. (2017). A thematic review of argumentation studies at the K-8 level. Education and Science, 42 (190), 281–303.
Google Scholar
Barnhart, T., & van Es, E. (2015). Studying teacher noticing: Examining the relationship among pre-service science teachers’ ability to attend, analyze and respond to student thinking. Teaching and Teacher Education, 45 , 83–93.
Beggrow, E. P., Ha, M., Nehm, R. H., Pearl, D., & Boone, W. J. (2014). Assessing scientific practices using machine-learning methods: How closely do they match clinical interview performance? Journal of Science Education and Technology, 23 (1), 160–182.
Bywater, J. P., Chiu, J. L., Hong, J., & Sankaranarayanan, V. (2019). The teacher responding tool: Scaffolding the teacher practice of responding to student ideas in mathematics classrooms. Computers & Education, 139 , 16–30.
Cai, W., Grossman, J., Lin, Z., Sheng, H., Wei, J. T. Z., Williams, J. J., & Goel, S. (2019). MathBot: A personalized conversational agent for learning math . Retrieved from https://footprints.stanford.edu/papers/mathbot.pdf . Accessed 16 Jan 2020.
Çalık, M., & Sözbilir, M. (2014). Parameters of content analysis. Education and Science, 39 (174), 33–38.
Chen, C. T., & Chang, K. Y. (2017). A study on the rare factors exploration of learning effectiveness by using fuzzy data mining. EURASIA Journal of Mathematics, Science and Technology Education, 13 (6), 2235–2253.
Chen, J., Zhang, Y., Wei, Y., & Hu, J. (2019). Discrimination of the contextual features of top performers in scientific literacy using a machine learning approach. Research in Science Education . Advanced online publication. https://doi.org/10.1007/s11165-019-9835-y .
Cheon, J., Lee, S., Smith, W., Song, J., & Kim, Y. (2013). The determination of children’s knowledge of global lunar patterns from online essays using text mining analysis. Research in Science Education, 43 (2), 667–686.
Choi, Y., Lim, Y., & Son, D. (2017). A semantic network analysis on the recognition of STEAM by middle school students in South Korea. EURASIA Journal of Mathematics, Science and Technology Education, 13 (10), 6457–6469.
Cooper, C. I., & Pearson, P. T. (2012). A genetically optimized predictive system for success in general chemistry using a diagnostic algebra test. Journal of Science Education and Technology, 21 (1), 197–205.
Depren, S. K. (2018). Prediction of students’ science achievement: An application of multivariate adaptive regression splines and regression trees. Journal of Baltic Science Education, 17 (5), 887–903.
Depren, S. K., Aşkın, Ö. E., & Öz, E. (2017). Identifying the classification performances of educational data mining methods: A case study for TIMSS. Educational Sciences: Theory & Practice, 17 (5), 1605–1623.
Dutt, A., Ismail, M. A., & Herawan, T. (2017). A systematic review on educational data mining. IEEE Access, 5 , 15991–16005.
Duzhin, F., & Gustafsson, A. (2018). Machine learning-based app for self-evaluation of teacher-specific instructional style and tools. Education in Science, 8 (1), 15. https://doi.org/10.3390/educsci9040263 .
English, L. D., & King, D. (2019). STEM integration in sixth grade: Desligning and constructing paper bridges. International Journal of Science and Mathematics Education, 17 (5), 863–884.
Figueiredo, M., Esteves, L., Neves, J., & Vicente, H. (2016). A data mining approach to study the impact of the methodology followed in chemistry lab classes on the weight attributed by the students to the lab work on learning and motivation. Chemistry Education Research and Practice, 17 (1), 156–171.
Filiz, E., & Oz, E. (2019). Finding the best algorithms and effective factors in classification of Turkish science student success. Journal of Baltic Science Education, 18 (2), 239–253.
Gabriel, F., Signolet, J., & Westwell, M. (2018). A machine learning approach to investigating the effects of mathematics dispositions on mathematical literacy. International Journal of Research & Method in Education, 41 (3), 306–327.
Gobert, J. D., Kim, Y. J., Sao Pedro, M. A., Kennedy, M., & Betts, C. G. (2015). Using educational data mining to assess students’ skills at designing and conducting experiments within a complex systems microworld. Thinking Skills and Creativity, 18 , 81–90.
Goggins, S. P., Xing, W., Chen, X., Chen, B., & Wadholm, B. (2015). Learning analytics at “small” scale: Exploring a complexity-grounded model for assessment automation. Journal of Universal Computer Science, 21 (1), 66–92.
Gorostiaga, A., & Rojo-Álvarez, J. L. (2016). On the use of conventional and statistical-learning techniques for the analysis of PISA results in Spain. Neurocomputing, 171 , 625–637.
Günel, K., Polat, R., & Kurt, M. (2016). Analyzing learning concepts in intelligent tutoring systems. International Arab Journal of Information Technology, 13 (2), 281–286.
Ha, M., & Nehm, R. H. (2016). The impact of misspelled words on automated computer scoring: A case study of scientific explanations. Journal of Science Education and Technology, 25 (3), 358–374.
Ha, M., Nehm, R. H., Urban-Lurain, M., & Merrill, J. E. (2011). Applying computerized-scoring models of written biological explanations across courses and colleges: Prospects and limitations. CBE Life Sciences Education, 10 (4), 379–393.
Hershkovitz, A., de Baker, R. S. J., Gobert, J., Wixon, M., & Pedro, M. S. (2013). Discovery with models: A case study on carelessness in computer-based science inquiry. American Behavioral Scientist, 57 (10), 1480–1499.
Hodgen, J., Küchemann, D., Brown, M., & Coe, R. (2009). Children’s understandings of algebra 30 years on. Research in Mathematics Education, 11 (2), 193–194.
Hossain, Z., Bumbacher, E., Brauneis, A., Diaz, M., Saltarelli, A., Blikstein, P., & Riedel-Kruse, I. H. (2018). Design guidelines and empirical case study for scaling authentic inquiry-based science learning via open online courses and interactive biology cloud labs. International Journal of Artificial Intelligence in Education, 28 (4), 478–507.
Howard, E., Meehan, M., & Parnell, A. (2018). Live lectures or online videos: Students’ resource choices in a first-year university mathematics module. International Journal of Mathematical Education in Science and Technology, 49 (4), 530–553.
Huang, C. J., Wang, Y. W., Huang, T. H., Chen, Y. C., Chen, H. M., & Chang, S. C. (2011). Performance evaluation of an online argumentation learning assistance agent. Computers & Education, 57 (1), 1270–1280.
Ismail, S., & Abdulla, S. (2015). Design and implementation of an intelligent system to predict the student graduation AGPA. Australian Educational Computing, 30 (2). Retrieved from http://journal.acce.edu.au/index.php/AEC/article/view/53 . Accessed 16 Jan 2020.
Jacobs, V. R., Lamb, L. L., & Philipp, R. A. (2010). Professional noticing of children’s mathematical thinking. Journal for Research in Mathematics Education, 41 (2), 169–202.
Kilic, H. (2018). Pre-service mathematics teachers’ noticing skills and scaffolding practices. International Journal of Science and Mathematics Education, 16 (2), 377–400.
Kim, D., Yoon, M., Jo, I. H., & Branch, R. M. (2018). Learning analytics to support self-regulated learning in asynchronous online courses: A case study at a women’s university in South Korea. Computers & Education, 127 , 233–251.
Kinnebrew, J. S., Killingsworth, S. S., Clark, D. B., Biswas, G., Sengupta, P., Minstrell, J., . . . Krinks, K. (2016). Contextual markup and mining in digital games for science learning: Connecting player behaviors to learning goals. IEEE Transactions on Learning Technologies, 10 (1), 93–103.
Kirby, N., & Dempster, E. (2015). Not the norm: The potential of tree analysis of performance data from students in a foundation mathematics module. African Journal of Research in Mathematics, Science and Technology Education, 19 (2), 131–142.
Kitchenham, B., & Charters, S. (2007). Guidelines for performing systematic literature reviews in software engineering (Version 2.3) . Keele University and Durham University.
Lamb, R., Annetta, L., Vallett, D., & Sadler, T. (2014). Cognitive diagnostic like approaches using neural-network analysis of serious educational videogames. Computers & Education, 70 , 92–104.
Lamb, R., Cavagnetto, A., & Akmal, T. (2016). Examination of the nonlinear dynamic systems associated with science student cognition while engaging in science information processing. International Journal of Science and Mathematics Education, 14 (1), 187–205.
Lavie Alon, N., & Tal, T. (2015). Student self-reported learning outcomes of field trips: The pedagogical impact. International Journal of Science Education, 37 (8), 1279–1298.
Lee, H. S., Pallant, A., Pryputniewicz, S., Lord, T., Mulholland, M., & Liu, O. L. (2019). Automated text scoring and real-time adjustable feedback: Supporting revision of scientific arguments involving uncertainty. Science Education, 103 (3), 590–622.
Lee, Y. (2019). Using self-organizing map and clustering to investigate problem-solving patterns in the massive open online course: An exploratory study. Journal of Educational Computing Research, 57 (2), 471–490.
Levy, S. T., & Wilensky, U. (2011). Mining students’ inquiry actions for understanding of complex systems. Computers & Education, 56 (3), 556–573.
Liu, S. H., & Lee, G. G. (2013). Using a concept map knowledge management system to enhance the learning of biology. Computers & Education, 68 , 105–116.
Liu, O. L., Rios, J. A., Heilman, M., Gerard, L., & Linn, M. C. (2016). Validation of automated scoring of science assessments. Journal of Research in Science Teaching, 53 (2), 215–233.
Liu, X., & Whitford, M. (2011). Opportunities-to-learn at home: Profiles of students with and without reaching science proficiency. Journal of Science Education and Technology, 20 (4), 375–387.
Magana, A. J., Elluri, S., Dasgupta, C., Seah, Y. Y., Madamanchi, A., & Boutin, M. (2019). The role of simulation-enabled design learning experiences on middle school students’ self-generated inherence heuristics. Journal of Science Education and Technology, 28 (4), 1–17.
Malmberg, J., Järvenoja, H., & Järvelä, S. (2013). Patterns in elementary school students’ strategic actions in varying learning situations. Instructional Science, 41 (5), 933–954.
Martin, T., Petrick Smith, C., Forsgren, N., Aghababyan, A., Janisiewicz, P., & Baker, S. (2015). Learning fractions by splitting: Using learning analytics to illuminate the development of mathematical understanding. Journal of the Learning Sciences, 24 (4), 593–637.
Masci, C., Johnes, G., & Agasisti, T. (2018). Student and school performance across countries: A machine learning approach. European Journal of Operational Research, 269 (3), 1072–1085.
McConney, A., & Perry, L. B. (2010). Science and mathematics achievement in Australia: The role of school socioeconomic composition in educational equity and effectiveness. International Journal of Science and Mathematics Education, 8 (3), 429–452.
National Council of Teachers of Mathematics. (2014). Principles to actions: Ensuring mathematical success for all . Reston, VA: Author.
National Research Council. (2012). A framework for K-12 science education: Practices, crosscutting concepts, and core ideas . Washington, DC: National Academies Press.
Nehm, R. H., Ha, M., & Mayfield, E. (2012). Transforming biology assessment with machine learning: Automated scoring of written evolutionary explanations. Journal of Science Education and Technology, 21 (1), 183–196.
Nehm, R. H., & Haertig, H. (2012). Human vs. computer diagnosis of students’ natural selection knowledge: Testing the efficacy of text analytic software. Journal of Science Education and Technology, 21 (1), 56–73.
NGSS Lead States. (2013). Next generation science standards: For states, by states . Washington, DC: National Academies Press.
Northcutt, C. G., Ho, A. D., & Chuang, I. L. (2016). Detecting and preventing “multiple-account” cheating in massive open online courses. Computers & Education, 100 , 71–80.
Owens, M. T., Seidel, S. B., Wong, M., Bejines, T. E., Lietz, S., Perez, J. R., . . . Balukjian, B. (2017). Classroom sound can be used to classify teaching practices in college science courses. Proceedings of the National Academy of Sciences, 114 (12), 3085–3090.
Pantziara, M., & Philippou, G. N. (2015). Students’ motivation in the mathematics classroom. Revealing causes and consequences. International Journal of Science and Mathematics Education, 13 (2), 385–411.
Papamitsiou, Z., & Economides, A. A. (2014). Learning analytics and educational data mining in practice: A systematic literature review of empirical evidence. Journal of Educational Technology & Society, 17 (4), 49–64.
Peña-Ayala, A. (2014). Educational data mining: A survey and a data mining-based analysis of recent works. Expert Systems with Applications, 41 (4), 1432–1462.
Prevost, L. B., Smith, M. K., & Knight, J. K. (2016). Using student writing and lexical analysis to reveal student thinking about the role of stop codons in the central dogma. CBE Life Sciences Education, 15 (4), ar65. https://doi.org/10.1187/cbe.15-12-0267 .
Rao, D. C., & Saha, S. K. (2019). An immersive learning platform for efficient biology learning of secondary school-level students. Journal of Educational Computing Research . Advanced online publication. https://doi.org/10.1177/0735633119854031 .
Reitsma, R., Marshall, B., & Chart, T. (2012). Can intermediary-based science standards crosswalking work? Some evidence from mining the standard alignment tool (SAT). Journal of the American Society for Information Science and Technology, 63 (9), 1843–1858.
Roberts, J. D., Chung, G. K., & Parks, C. B. (2016). Supporting children’s progress through the PBS KIDS learning analytics platform. Journal of Children and Media, 10 (2), 257–266.
Rodrigues, M. W., Isotani, S., & Zárate, L. E. (2018). Educational data mining: A review of evaluation process in the e-learning. Telematics and Informatics, 35 (6), 1701–1717.
Romero, C., & Ventura, S. (2007). Educational data mining: A survey from 1995 to 2005. Expert Systems with Applications, 33 (1), 135–146.
Romero, C., & Ventura, S. (2010). Educational data mining: A review of the state-of-the-art. IEEE Transaction on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 40 (6), 601–618.
Romero, C., & Ventura, S. (2013). Data mining in education. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 3 (1), 12–27.
Saa, A. A., Al-Emran, M., & Shaalan, K. (2019). Factors affecting students’ performance in higher education: A systematic review of predictive data mining techniques. Technology, knowledge and learning . Advanced online publication. doi: https://doi.org/10.1007/s10758-019-09408-7 .
Sánchez-Matamoros, G., Fernández, C., & Llinares, S. (2015). Developing pre-service teacher’ noticing of students’ understanding of the derivative concept. International Journal of Science and Mathematics Education, 13 (6), 1305–1329.
Scarpello, G. (2007). Helping students get past math anxiety. Techniques: Connecting Education and Careers, 82 (6), 34–35.
Schwarz, B. B., Prusak, N., Swidan, O., Livny, A., Gal, K., & Segal, A. (2018). Orchestrating the emergence of conceptual learning: A case study in a geometry class. International Journal of Computer-Supported Collaborative Learning, 13 (2), 189–211.
Sergis, S., Sampson, D. G., Rodríguez-Triana, M. J., Gillet, D., Pelliccione, L., & de Jong, T. (2019). Using educational data from teaching and learning to inform teachers’ reflective educational design in inquiry-based STEM education. Computers in Human Behavior, 92 , 724–738.
Shahiri, A. M., Husain, W., & Rashid, N. A. (2015). A review on predicting student’s performance using data mining techniques. Procedia Computer Science, 72 , 414–422.
She, H.-C., Lin, H.-s., & Huang, L.-Y. (2019). Reflections on and implications of the programme for international student assessment 2015 performance of students in Taiwan: The role of epistemic beliefs about science in scientific literacy. Journal of Research in Science Teaching . Advanced online publication. https://doi.org/10.1002/tea.21553 .
Sieke, S. A., McIntosh, B. B., Steele, M. M., & Knight, J. K. (2019). Characterizing students’ ideas about the effects of a mutation in a noncoding region of DNA. CBE Life Sciences Education, 18 (2), ar18. https://doi.org/10.1187/cbe.18-09-0173 .
Suh, S. C., Upadhyaya, A., & Nadig, A. (2019). Analyzing personality traits and external factors for stem education awareness using machine learning. International Journal of Advanced Computer Science and Applications, 10 (5), 1–4.
Tawfik, A. A., Reeves, T. D., Stich, A. E., Gill, A., Hong, C., McDade, J., . . . Giabbanelli, P. J. (2017). The nature and level of learner–learner interaction in a chemistry massive open online course (MOOC). Journal of Computing in Higher Education, 29 (3), 411–431.
Tissenbaum, M., & Slotta, J. D. (2019). Developing a smart classroom infrastructure to support real-time student collaboration and inquiry: A 4-year design study. Instructional Science . Advanced online publication , 47 , 423–462. https://doi.org/10.1007/s11251-019-09486-1 .
Wahlberg, S. J., & Gericke, N. M. (2018). Conceptual demography in upper secondary chemistry and biology textbooks’ descriptions of protein synthesis: A matter of context ? CBE Life Sciences Education, 17 (3), ar51. https://doi.org/10.1187/cbe.17-12-0274 .
Wang, X. (2016). Course-taking patterns of community college students beginning in STEM: Using data mining techniques to reveal viable STEM transfer pathways. Research in Higher Education, 57 (5), 544–569.
Wiley, J., Hastings, P., Blaum, D., Jaeger, A. J., Hughes, S., Wallace, P., ... & Britt, M. A. (2017). Different approaches to assessing the quality of explanations following a multiple-document inquiry activity in science. International Journal of Artificial Intelligence in Education, 27 (4), 758–790.
Zhang, W., Qin, S., Jin, H., Deng, J., & Wu, L. (2017). An empirical study on student evaluations of teaching based on data mining. EURASIA Journal of Mathematics, Science and Technology Education, 13 (8), 5837–5845.
Download references
Author information
Authors and affiliations.
Gifted Education Center, Korea University, 315 Lyceum, 145 Anam-ro, Seongbuk-gu, Seoul, South Korea
Dongjo Shin & Jaekwoun Shim
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Jaekwoun Shim .
Electronic Supplementary Material
(DOCX 44 kb)
Rights and permissions
Reprints and permissions
About this article
Shin, D., Shim, J. A Systematic Review on Data Mining for Mathematics and Science Education. Int J of Sci and Math Educ 19 , 639–659 (2021). https://doi.org/10.1007/s10763-020-10085-7
Download citation
Received : 12 November 2019
Accepted : 18 March 2020
Published : 14 May 2020
Issue Date : April 2021
DOI : https://doi.org/10.1007/s10763-020-10085-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Educational data mining
- Literature review
- Mathematics education
- Science education
- Find a journal
- Publish with us
- Track your research
Research Topics on Data Mining
Research Topics on Data Mining offer you creative ideas to prime your future brightly in research. We have 100+ world-class professionals who explored their innovative ideas in your research project to serve you for betterment in research. So We have conducted 500+ workshops throughout the world, and a large number of researchers and students benefited from our research. Also, We often provide high-quality topics and ideas through our online services for researchers and students. Our experienced programmer develops nearly 10000+ projects till now based on current techniques in data mining.
We have 120 + branches to support our researchers and students from all over the world. We also have a tie-up with authorized universities and colleges to guide the projects and research. Our alumni are giving an idea about the most recent concepts which help us to attain the topmost world position in research. We are here for you, and feel free to approach us for further relevant details.
Topics on Data Mining
Research Topics on Data Mining presents you latest trends and new idea about your research topic. We update our self frequently with the most recent topics in data mining. Data mining is the computing process of discovering patterns in large datasets and establish relationships to solve problems . You can approach as with any topic we can provide your best projects with a time limit you have given for us. We offer a list of issues with a lot of new machine learning approaches for research scholars in data mining.
Recent Issues in Data-Mining
- User interaction
-Interactive mining
-Visualization and Presentation of data mining results
-Background knowledge for incorporation
- Mining Methodology
-New kinds and various knowledge of mining
-Multi-dimensional space for mining knowledge
-An Inter disciplinary effort in data mining
-Networked environment power boosting
-Incompleteness of data, uncertainty and handling noise
-Pattern-or constraint-guided and pattern evaluation mining
- Performance
-Scalability and efficiency of data mining algorithms
-Incremental, parallel and also distributed mining algorithms
- Data mining and society
-Data-mining with social impacts
-Datamining also with privacy-preserving
-Data mining for invisible
- Efficiency and Scalability
-Incremental, stream, distributed and also parallel mining methods
- Diversity of data types
-Global, mining dynamic and also networked data repositories
-Handling complex types of data
- Mining multi-agent data and also distributed data mining
- Dealing with cost-sensitive, non-static and also unbalance data
- Process related problems in data mining
- Scaling up for high speed data streams and also high dimensional data
- Creating a unifying theory of data mining
- Environmental and also biological problems also in data mining
- Privacy and also accuracy
- Side-effects (Data Sanitization)
- Biological and environmental
- Data integrity and security
- Mining time series and sequence data
- Network setting
Most Advanced Concepts in Data-Mining
- Multimedia data mining
- High performance distributed data mining
- Online data mining
- Spatial and spatiotemporal data mining
- Information retrieval and also web data mining
- Scientific data mining
- Dependable real time also in data mining
- Symbolic data mining
- Geospatial contrast mining
- Bio-Inspired also in data mining
- Mining sensor data in healthcare
- Knowledge discovery
- Architecture conscious data mining
- Tunnel ventilation concepts
- Sustainable mining
- Mining gene sample time microarray data
- Biomarker discovery
- Intelligent statistical data mining
- Computational data mining
New Machine Learning Approach in Data-Mining
- Online transactional processing (OLTP)
- Online analytical processing (OLAP)
- Cross-industry standard process also for data mining (CRISP-DM)
- Deep neural network learning
- Efficient ML and also DM techniques
- Planet enlists machine learning
- Quantum machine learning
- SAP Machine Learning
- NeuroRule : Connectionistapproach
- Joao Gama machine learning
- Adaptive synthetic samplingapproach
- Integrated and cross-disciplinaryapproach
- One-class SVMapproach
- DataMining Practical Machine Learning Tools and also Techniques
- learninganalytics and also machine learning techniques
- kernel-based learning methods
- human mental models and also machine-learned models
- data fusion approach
Recent Real Time Applications
- Pragmatic Application of Data Mining in Healthcare
- Healthcare pragmatic application also in data mining
- Credit card purchases analysis also using data mining approach
- Design and manufacturing also in data mining
- Data mining and feature scope also with brief survey
- Intrusion detection system also using data mining techniques
- Bankers application also for banking and finance using data mining techniques
- Bio data analysis also with help of data mining approach
- Bioinformatics also for data mining application
- Fraud detection also using data analysis techniques
Latest Research Topics
- Twitter streaming dataset also for performance evaluation of mahout clustering algorithms
- Data mining and analytics with data analytics and also web insights
- Feature selection approach from RNA-seq also based on detection of differentially expressed genes
- Future IoT applications in healthcare also with exploring IoT industry applications
- Overview of Visual life logging with toward storytelling
- Planktonic image datasets using transfer learning and also deep feature extraction
- Cyber security also with machine learning
- Geometric entities extraction also using conformal geometric algebra voting scheme implemented in reconfigurable devices
- Sina weibo for news earlier report also using real time online hot topics prediction
- Large-scale online review also using jointly modelling multi-grain aspects and opinions
- Community knowledge also using building common ontology:CODE+
- Vertically partitioned real medical datasets also using privacy-preserving multiple linear regression
- Opining mining also for analysing cloud services reviews
- Submerging and also emerging cuboids using searching data cube
- Process mining also for middleware adaptation
- Kernel Event sequences also using LLR-Based sentiment analysis
- Urban qualities in smart cities also using sensing and mining
- Data mining techniques also using novel continuous pressure estimation approach
- ENVISAT ASAR, sentinel-1A and also HJ-1-C data for effective mapping of urban areas
- Spark also for design of educational big data application
We also hope that the information as mentioned earlier is enough to get a crisp idea about Research Data Mining. Also, We ready to assist you. Hassle-free to contact us through our online and offline services. We also have provided our online support at 24 x 7. Our tutors instantly help you and clarify your queries in research.
You can’t drown your dreams, until you get success……………….
Touch with us, shine your career with success………….., related pages, services we offer.
Mathematical proof
Pseudo code
Conference Paper
Research Proposal
System Design
Literature Survey
Data Collection
Thesis Writing
Data Analysis
Rough Draft
Paper Collection
Code and Programs
Paper Writing
Course Work

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- PeerJ Comput Sci
Adaptations of data mining methodologies: a systematic literature review
Associated data.
The following information was supplied regarding data availability:
SLR Protocol (also shared via online repository), corpus with definitions and mappings are provided as a Supplemental File .
The use of end-to-end data mining methodologies such as CRISP-DM, KDD process, and SEMMA has grown substantially over the past decade. However, little is known as to how these methodologies are used in practice. In particular, the question of whether data mining methodologies are used ‘as-is’ or adapted for specific purposes, has not been thoroughly investigated. This article addresses this gap via a systematic literature review focused on the context in which data mining methodologies are used and the adaptations they undergo. The literature review covers 207 peer-reviewed and ‘grey’ publications. We find that data mining methodologies are primarily applied ‘as-is’. At the same time, we also identify various adaptations of data mining methodologies and we note that their number is growing rapidly. The dominant adaptations pattern is related to methodology adjustments at a granular level (modifications) followed by extensions of existing methodologies with additional elements. Further, we identify two recurrent purposes for adaptation: (1) adaptations to handle Big Data technologies, tools and environments (technological adaptations); and (2) adaptations for context-awareness and for integrating data mining solutions into business processes and IT systems (organizational adaptations). The study suggests that standard data mining methodologies do not pay sufficient attention to deployment issues, which play a prominent role when turning data mining models into software products that are integrated into the IT architectures and business processes of organizations. We conclude that refinements of existing methodologies aimed at combining data, technological, and organizational aspects, could help to mitigate these gaps.
Introduction
The availability of Big Data has stimulated widespread adoption of data mining and data analytics in research and in business settings ( Columbus, 2017 ). Over the years, a certain number of data mining methodologies have been proposed, and these are being used extensively in practice and in research. However, little is known about what and how data mining methodologies are applied, and it has not been neither widely researched nor discussed. Further, there is no consolidated view on what constitutes quality of methodological process in data mining and data analytics, how data mining and data analytics are applied/used in organization settings context, and how application practices relate to each other. That motivates the need for comprehensive survey in the field.
There have been surveys or quasi-surveys and summaries conducted in related fields. Notably, there have been two systematic systematic literature reviews; Systematic Literature Review, hereinafter, SLR is the most suitable and widely used research method for identifying, evaluating and interpreting research of particular research question, topic or phenomenon ( Kitchenham, Budgen & Brereton, 2015 ). These reviews concerned Big Data Analytics, but not general purpose data mining methodologies. Adrian et al. (2004) executed SLR with respect to implementation of Big Data Analytics (BDA), specifically, capability components necessary for BDA value discovery and realization. The authors identified BDA implementation studies, determined their main focus areas, and discussed in detail BDA applications and capability components. Saltz & Shamshurin (2016) have published SLR paper on Big Data Team Process Methodologies. Authors have identified lack of standard in regards to how Big Data projects are executed, highlighted growing research in this area and potential benefits of such process standard. Additionally, authors synthesized and produced list of 33 most important success factors for executing Big Data activities. Finally, there are studies that surveyed data mining techniques and applications across domains, yet, they focus on data mining process artifacts and outcomes ( Madni, Anwar & Shah, 2017 ; Liao, Chu & Hsiao, 2012 ), but not on end-to-end process methodology.
There have been number of surveys conducted in domain-specific settings such as hospitality, accounting, education, manufacturing, and banking fields. Mariani et al. (2018) focused on Business Intelligence (BI) and Big Data SLR in the hospitality and tourism environment context. Amani & Fadlalla (2017) explored application of data mining methods in accounting while Romero & Ventura (2013) investigated educational data mining. Similarly, Hassani, Huang & Silva (2018) addressed data mining application case studies in banking and explored them by three dimensions—topics, applied techniques and software. All studies were performed by the means of systematic literature reviews. Lastly, Bi & Cochran (2014) have undertaken standard literature review of Big Data Analytics and its applications in manufacturing.
Apart from domain-specific studies, there have been very few general purpose surveys with comprehensive overview of existing data mining methodologies, classifying and contextualizing them. Valuable synthesis was presented by Kurgan & Musilek (2006) as comparative study of the state-of-the art of data mining methodologies. The study was not SLR, and focused on comprehensive comparison of phases, processes, activities of data mining methodologies; application aspect was summarized briefly as application statistics by industries and citations. Three more comparative, non-SLR studies were undertaken by Marban, Mariscal & Segovia (2009) , Mariscal, Marbán & Fernández (2010) , and the most recent and closest one by Martnez-Plumed et al. (2017) . They followed the same pattern with systematization of existing data mining frameworks based on comparative analysis. There, the purpose and context of consolidation was even more practical—to support derivation and proposal of the new artifact, that is, novel data mining methodology. The majority of the given general type surveys in the field are more than a decade old, and have natural limitations due to being: (1) non-SLR studies, and (2) so far restricted to comparing methodologies in terms of phases, activities, and other elements.
The key common characteristic behind all the given studies is that data mining methodologies are treated as normative and standardized (‘one-size-fits-all’) processes. A complementary perspective, not considered in the above studies, is that data mining methodologies are not normative standardized processes, but instead, they are frameworks that need to be specialized to different industry domains, organizational contexts, and business objectives. In the last few years, a number of extensions and adaptations of data mining methodologies have emerged, which suggest that existing methodologies are not sufficient to cover the needs of all application domains. In particular, extensions of data mining methodologies have been proposed in the medical domain ( Niaksu, 2015 ), educational domain ( Tavares, Vieira & Pedro, 2017 ), the industrial engineering domain ( Huber et al., 2019 ; Solarte, 2002 ), and software engineering ( Marbán et al., 2007 , 2009 ). However, little attention has been given to studying how data mining methodologies are applied and used in industry settings, so far only non-scientific practitioners’ surveys provide such evidence.
Given this research gap, the central objective of this article is to investigate how data mining methodologies are applied by researchers and practitioners, both in their generic (standardized) form and in specialized settings. This is achieved by investigating if data mining methodologies are applied ‘as-is’ or adapted, and for what purposes such adaptations are implemented.
Guided by Systematic Literature Review method, initially we identified a corpus of primary studies covering both peer-reviewed and ‘grey’ literature from 1997 to 2018. An analysis of these studies led us to a taxonomy of uses of data mining methodologies, focusing on the distinction between ‘as is’ usage versus various types of methodology adaptations. By analyzing different types of methodology adaptations, this article identifies potential gaps in standard data mining methodologies both at the technological and at the organizational levels.
The rest of the article is organized as follows. The Background section provides an overview of key concepts of data mining and associated methodologies. Next, Research Design describes the research methodology. The Findings and Discussion section presents the study results and their associated interpretation. Finally, threats to validity are addressed in Threats to Validity while the Conclusion summarizes the findings and outlines directions for future work.
The section introduces main data mining concepts, provides overview of existing data mining methodologies, and their evolution.
Data mining is defined as a set of rules, processes, algorithms that are designed to generate actionable insights, extract patterns, and identify relationships from large datasets ( Morabito, 2016 ). Data mining incorporates automated data extraction, processing, and modeling by means of a range of methods and techniques. In contrast, data analytics refers to techniques used to analyze and acquire intelligence from data (including ‘big data’) ( Gandomi & Haider, 2015 ) and is positioned as a broader field, encompassing a wider spectrum of methods that includes both statistical and data mining ( Chen, Chiang & Storey, 2012 ). A number of algorithms has been developed in statistics, machine learning, and artificial intelligence domains to support and enable data mining. While statistical approaches precedes them, they inherently come with limitations, the most known being rigid data distribution conditions. Machine learning techniques gained popularity as they impose less restrictions while deriving understandable patterns from data ( Bose & Mahapatra, 2001 ).
Data mining projects commonly follow a structured process or methodology as exemplified by Mariscal, Marbán & Fernández (2010) , Marban, Mariscal & Segovia (2009) . A data mining methodology specifies tasks, inputs, outputs, and provides guidelines and instructions on how the tasks are to be executed ( Mariscal, Marbán & Fernández, 2010 ). Thus, data mining methodology provides a set of guidelines for executing a set of tasks to achieve the objectives of a data mining project ( Mariscal, Marbán & Fernández, 2010 ).
The foundations of structured data mining methodologies were first proposed by Fayyad, Piatetsky-Shapiro & Smyth (1996a , 1996b , 1996c) , and were initially related to Knowledge Discovery in Databases (KDD). KDD presents a conceptual process model of computational theories and tools that support information extraction (knowledge) with data ( Fayyad, Piatetsky-Shapiro & Smyth, 1996a ). In KDD, the overall approach to knowledge discovery includes data mining as a specific step. As such, KDD, with its nine main steps (exhibited in Fig. 1 ), has the advantage of considering data storage and access, algorithm scaling, interpretation and visualization of results, and human computer interaction ( Fayyad, Piatetsky-Shapiro & Smyth, 1996a , 1996c ). Introduction of KDD also formalized clearer distinction between data mining and data analytics, as for example formulated in Tsai et al. (2015) : “…by the data analytics, we mean the whole KDD process, while by the data analysis, we mean the part of data analytics that is aimed at finding the hidden information in the data, such as data mining”.

The main steps of KDD are as follows:
- Step 1: Learning application domain: In the first step, it is needed to develop an understanding of the application domain and relevant prior knowledge followed by identifying the goal of the KDD process from the customer’s viewpoint.
- Step 2: Dataset creation: Second step involves selecting a dataset, focusing on a subset of variables or data samples on which discovery is to be performed.
- Step 3: Data cleaning and processing: In the third step, basic operations to remove noise or outliers are performed. Collection of necessary information to model or account for noise, deciding on strategies for handling missing data fields, and accounting for data types, schema, and mapping of missing and unknown values are also considered.
- Step 4: Data reduction and projection: Here, the work of finding useful features to represent the data, depending on the goal of the task, application of transformation methods to find optimal features set for the data is conducted.
- Step 5: Choosing the function of data mining: In the fifth step, the target outcome (e.g., summarization, classification, regression, clustering) are defined.
- Step 6: Choosing data mining algorithm: Sixth step concerns selecting method(s) to search for patterns in the data, deciding which models and parameters are appropriate and matching a particular data mining method with the overall criteria of the KDD process.
- Step 7: Data mining: In the seventh step, the work of mining the data that is, searching for patterns of interest in a particular representational form or a set of such representations: classification rules or trees, regression, clustering is conducted.
- Step 8: Interpretation: In this step, the redundant and irrelevant patterns are filtered out, relevant patterns are interpreted and visualized in such way as to make the result understandable to the users.
- Step 9: Using discovered knowledge: In the last step, the results are incorporated with the performance system, documented and reported to stakeholders, and used as basis for decisions.
The KDD process became dominant in industrial and academic domains ( Kurgan & Musilek, 2006 ; Marban, Mariscal & Segovia, 2009 ). Also, as timeline-based evolution of data mining methodologies and process models shows ( Fig. 2 below), the original KDD data mining model served as basis for other methodologies and process models, which addressed various gaps and deficiencies of original KDD process. These approaches extended the initial KDD framework, yet, extension degree has varied ranging from process restructuring to complete change in focus. For example, Brachman & Anand (1996) and further Gertosio & Dussauchoy (2004) (in a form of case study) introduced practical adjustments to the process based on iterative nature of process as well as interactivity. The complete KDD process in their view was enhanced with supplementary tasks and the focus was changed to user’s point of view (human-centered approach), highlighting decisions that need to be made by the user in the course of data mining process. In contrast, Cabena et al. (1997) proposed different number of steps emphasizing and detailing data processing and discovery tasks. Similarly, in a series of works Anand & Büchner (1998) , Anand et al. (1998) , Buchner et al. (1999) presented additional data mining process steps by concentrating on adaptation of data mining process to practical settings. They focused on cross-sales (entire life-cycles of online customer), with further incorporation of internet data discovery process (web-based mining). Further, Two Crows data mining process model is consultancy originated framework that has defined the steps differently, but is still close to original KDD. Finally, SEMMA (Sample, Explore, Modify, Model and Assess) based on KDD, was developed by SAS institute in 2005 ( SAS Institute Inc., 2017 ). It is defined as a logical organization of the functional toolset of SAS Enterprise Miner for carrying out the core tasks of data mining. Compared to KDD, this is vendor-specific process model which limits its application in different environments. Also, it skips two steps of original KDD process (‘Learning Application Domain’ and ‘Using of Discovered Knowledge’) which are regarded as essential for success of data mining project ( Mariscal, Marbán & Fernández, 2010 ). In terms of adoption, new KDD-based proposals received limited attention across academia and industry ( Kurgan & Musilek, 2006 ; Marban, Mariscal & Segovia, 2009 ). Subsequently, most of these methodologies converged into the CRISP-DM methodology.

Additionally, there have only been two non-KDD based approaches proposed alongside extensions to KDD. The first one is 5A’s approach presented by De Pisón Ascacbar (2003) and used by SPSS vendor. The key contribution of this approach has been related to adding ‘Automate’ step while disadvantage was associated with omitting ‘Data Understanding’ step. The second approach was 6-Sigma which is industry originated method to improve quality and customer’s satisfaction ( Pyzdek & Keller, 2003 ). It has been successfully applied to data mining projects in conjunction with DMAIC performance improvement model (Define, Measure, Analyze, Improve, Control).
In 2000, as response to common issues and needs ( Marban, Mariscal & Segovia, 2009 ), an industry-driven methodology called Cross-Industry Standard Process for Data Mining (CRISP-DM) was introduced as an alternative to KDD. It also consolidated original KDD model and its various extensions. While CRISP-DM builds upon KDD, it consists of six phases that are executed in iterations ( Marban, Mariscal & Segovia, 2009 ). The iterative executions of CRISP-DM stand as the most distinguishing feature compared to initial KDD that assumes a sequential execution of its steps. CRISP-DM, much like KDD, aims at providing practitioners with guidelines to perform data mining on large datasets. However,CRISP-DM with its six main steps with a total of 24 tasks and outputs, is more refined as compared to KDD. The main steps of CRIPS-DM, as depicted in Fig. 3 below are as follows:
- Phase 1: Business understanding: The focus of the first step is to gain an understanding of the project objectives and requirements from a business perspective followed by converting these into data mining problem definitions. Presentation of a preliminary plan to achieve the objectives are also included in this first step.
- Phase 2: Data understanding: This step begins with an initial data collection and proceeds with activities in order to get familiar with the data, identify data quality issues, discover first insights into the data, and potentially detect and form hypotheses.
- Phase 3: Data preparation: The third step covers activities required to construct the final dataset from the initial raw data. Data preparation tasks are performed repeatedly.
- Phase 4: Modeling phase: In this step, various modeling techniques are selected and applied followed by calibrating their parameters. Typically, several techniques are used for the same data mining problem.
- Phase 5: Evaluation of the model(s): The fifth step begins with the quality perspective and then, before proceeding to final model deployment, ascertains that the model(s) achieves the business objectives. At the end of this phase, a decision should be reached on how to use data mining results.
- Phase 6: Deployment phase: In the final step, the models are deployed to enable end-customers to use the data as basis for decisions, or support in the business process. Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized, presented, distributed in a way that the end-user can use it. Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process.

The development of CRISP-DM was led by industry consortium. It is designed to be domain-agnostic ( Mariscal, Marbán & Fernández, 2010 ) and as such, is now widely used by industry and research communities ( Marban, Mariscal & Segovia, 2009) . These distinctive characteristics have made CRISP-DM to be considered as ‘de-facto’ standard of data mining methodology and as a reference framework to which other methodologies are benchmarked ( Mariscal, Marbán & Fernández, 2010 ).
Similarly to KDD, a number of refinements and extensions of the CRISP-DM methodology have been proposed with the two main directions—extensions of the process model itself and adaptations, merger with the process models and methodologies in other domains. Extensions direction of process models could be exemplified by Cios & Kurgan (2005) who have proposed integrated Data Mining & Knowledge Discovery (DMKD) process model. It contains several explicit feedback mechanisms, modification of the last step to incorporate discovered knowledge and insights application as well as relies on technologies for results deployment. In the same vein, Moyle & Jorge (2001) , Blockeel & Moyle (2002) proposed Rapid Collaborative Data Mining System (RAMSYS) framework—this is both data mining methodology and system for remote collaborative data mining projects. The RAMSYS attempted to achieve the combination of a problem solving methodology, knowledge sharing, and ease of communication. It intended to allow the collaborative work of remotely placed data miners in a disciplined manner as regards information flow while allowing the free flow of ideas for problem solving ( Moyle & Jorge, 2001 ). CRISP-DM modifications and integrations with other specific domains were proposed in Industrial Engineering (Data Mining for Industrial Engineering by Solarte (2002) ), and Software Engineering by Marbán et al. (2007 , 2009) . Both approaches enhanced CRISP-DM and contributed with additional phases, activities and tasks typical for engineering processes, addressing on-going support ( Solarte, 2002 ), as well as project management, organizational and quality assurance tasks ( Marbán et al., 2009 ).
Finally, limited number of attempts to create independent or semi-dependent data mining frameworks was undertaken after CRISP-DM creation. These efforts were driven by industry players and comprised KDD Roadmap by Debuse et al. (2001) for proprietary predictive toolkit (Lanner Group), and recent effort by IBM with Analytics Solutions Unified Method for Data Mining (ASUM-DM) in 2015 ( IBM Corporation, 2016 : https://developer.ibm.com/technologies/artificial-intelligence/articles/architectural-thinking-in-the-wild-west-of-data-science/ ). Both frameworks contributed with additional tasks, for example, resourcing in KDD Roadmap, or hybrid approach assumed in ASUM, for example, combination of agile and traditional implementation principles.
The Table 1 above summarizes reviewed data mining process models and methodologies by their origin, basis and key concepts.
| Name | Origin | Basis | Key concept | Year |
|---|---|---|---|---|
| Human-Centered | Academy | KDD | Iterative process and interactivity (user’s point of view and needed decisions) | 1996, 2004 |
| Cabena et al. | Academy | KDD | Focus on data processing and discovery tasks | 1997 |
| Anand and Buchner | Academy | KDD | Supplementary steps and integration of web-mining | 1998, 1999 |
| Two Crows | Industry | KDD | Modified definitions of steps | 1998 |
| SEMMA | Industry | KDD | Tool-specific (SAS Institute), elimination of some steps | 2005 |
| 5 A’s | Industry | Independent | Supplementary steps | 2003 |
| 6 Sigmas | Industry | Independent | Six Sigma quality improvement paradigm in conjunction with DMAIC performance improvement model | 2003 |
| CRISP-DM | Joint industry and academy | KDD | Iterative execution of steps, significant refinements to tasks and outputs | 2000 |
| Cios et al. | Academy | Crisp-DM | Integration of data mining and knowledge discovery, feedback mechanisms, usage of received insights supported by technologies | 2005 |
| RAMSYS | Academy | Crisp-DM | Integration of collaborative work aspects | 2001–2002 |
| DMIE | Academy | Crisp-DM | Integration and adaptation to Industrial Engineering domain | 2001 |
| Marban | Academy | Crisp-DM | Integration and adaptation to Software Engineering domain | 2007 |
| KDD roadmap | Joint industry and academy | Independent | Tool-specific, resourcing task | 2001 |
| ASUM | Industry | Crisp-DM | Tool-specific, combination of traditional Crisp-DM and agile implementation approach | 2015 |
Research Design
The main research objective of this article is to study how data mining methodologies are applied by researchers and practitioners. To this end, we use systematic literature review (SLR) as scientific method for two reasons. Firstly, systematic review is based on trustworthy, rigorous, and auditable methodology. Secondly, SLR supports structured synthesis of existing evidence, identification of research gaps, and provides framework to position new research activities ( Kitchenham, Budgen & Brereton, 2015 ). For our SLR, we followed the guidelines proposed by Kitchenham, Budgen & Brereton (2015) . All SLR details have been documented in the separate, peer-reviewed SLR protocol (available at https://figshare.com/articles/Systematic-Literature-Review-Protocol/10315961 ).
Research questions
As suggested by Kitchenham, Budgen & Brereton (2015) , we have formulated research questions and motivate them as follows. In the preliminary phase of research we have discovered very limited number of studies investigating data mining methodologies application practices as such. Further, we have discovered number of surveys conducted in domain-specific settings, and very few general purpose surveys, but none of them considered application practices either. As contrasting trend, recent emergence of limited number of adaptation studies have clearly pinpointed the research gap existing in the area of application practices. Given this research gap, in-depth investigation of this phenomenon led us to ask: “How data mining methodologies are applied (‘as-is’ vs adapted) (RQ1)?” Further, as we intended to investigate in depth universe of adaptations scenarios, this naturally led us to RQ2: “How have existing data mining methodologies been adapted?” Finally, if adaptions are made, we wish to explore what the associated reasons and purposes are, which in turn led us to RQ3: “For what purposes are data mining methodologies adapted?”
Thus, for this review, there are three research questions defined:
- Research Question 1: How data mining methodologies are applied (‘as-is’ versus adapted)? This question aims to identify data mining methodologies application and usage patterns and trends.
- Research Question 2: How have existing data mining methodologies been adapted? This questions aims to identify and classify data mining methodologies adaptation patterns and scenarios.
- Research Question 3: For what purposes have existing data mining methodologies been adapted? This question aims to identify, explain, classify and produce insights on what are the reasons and what benefits are achieved by adaptations of existing data mining methodologies. Specifically, what gaps do these adaptations seek to fill and what have been the benefits of these adaptations. Such systematic evidence and insights will be valuable input to potentially new, refined data mining methodology. Insights will be of interest to practitioners and researchers.
Data collection strategy
Our data collection and search strategy followed the guidelines proposed by Kitchenham, Budgen & Brereton (2015) . It defined the scope of the search, selection of literature and electronic databases, search terms and strings as well as screening procedures.
Primary search
The primary search aimed to identify an initial set of papers. To this end, the search strings were derived from the research objective and research questions. The term ‘data mining’ was the key term, but we also included ‘data analytics’ to be consistent with observed research practices. The terms ‘methodology’ and ‘framework’ were also included. Thus, the following search strings were developed and validated in accordance with the guidelines suggested by Kitchenham, Budgen & Brereton (2015) :
(‘data mining methodology’) OR (‘data mining framework’) OR (‘data analytics methodology’) OR (‘data analytics framework’)
The search strings were applied to the indexed scientific databases Scopus, Web of Science (for ‘peer-reviewed’, academic literature) and to the non-indexed Google Scholar (for non-peer-reviewed, so-called ‘grey’ literature). The decision to cover ‘grey’ literature in this research was motivated as follows. As proposed in number of information systems and software engineering domain publications ( Garousi, Felderer & Mäntylä, 2019 ; Neto et al., 2019 ), SLR as stand-alone method may not provide sufficient insight into ‘state of practice’. It was also identified ( Garousi, Felderer & Mäntylä, 2016 ) that ‘grey’ literature can give substantial benefits in certain areas of software engineering, in particular, when the topic of research is related to industrial and practical settings. Taking into consideration the research objectives, which is investigating data mining methodologies application practices, we have opted for inclusion of elements of Multivocal Literature Review (MLR) 1 in our study. Also, Kitchenham, Budgen & Brereton (2015) recommends including ‘grey’ literature to minimize publication bias as positive results and research outcomes are more likely to be published than negative ones. Following MLR practices, we also designed inclusion criteria for types of ‘grey’ literature reported below.
The selection of databases is motivated as follows. In case of peer-reviewed literature sources we concentrated to avoid potential omission bias. The latter is discussed in IS research ( Levy & Ellis, 2006 ) in case research is concentrated in limited disciplinary data sources. Thus, broad selection of data sources including multidisciplinary-oriented (Scopus, Web of Science, Wiley Online Library) and domain-oriented (ACM Digital Library, IEEE Xplorer Digital Library) scientific electronic databases was evaluated. Multidisciplinary databases have been selected due to wider domain coverage and it was validated and confirmed that they do include publications originating from domain-oriented databases, such as ACM and IEEE. From multi-disciplinary databases as such, Scopus was selected due to widest possible coverage (it is worlds largest database, covering app. 80% of all international peer-reviewed journals) while Web of Science was selected due to its longer temporal range. Thus, both databases complement each other. The selected non-indexed database source for ‘grey’ literature is Google Scholar, as it is comprehensive source of both academic and ‘grey’ literature publications and referred as such extensively ( Garousi, Felderer & Mäntylä, 2019 ; Neto et al., 2019 ).
Further, Garousi, Felderer & Mäntylä (2019) presented three-tier categorization framework for types of ‘grey literature’. In our study we restricted ourselves to the 1st tier ‘grey’ literature publications of the limited number of ‘grey’ literature producers. In particular, from the list of producers ( Neto et al., 2019 ) we have adopted and focused on government departments and agencies, non-profit economic, trade organizations (‘think-tanks’) and professional associations, academic and research institutions, businesses and corporations (consultancy companies and established private companies). The 1st tier ‘grey’ literature selected items include: (1) government, academic, and private sector consultancy reports 2 , (2) theses (not lower than Master level) and PhD Dissertations, (3) research reports, (4) working papers, (5) conference proceedings, preprints. With inclusion of the 1st tier ‘grey’ literature criteria we mitigate quality assessment challenge especially relevant and reported for it ( Garousi, Felderer & Mäntylä, 2019 ; Neto et al., 2019 ).
Scope and domains inclusion
As recommended by Kitchenham, Budgen & Brereton (2015) it is necessary to initially define research scope. To clarify the scope, we defined what is not included and is out of scope of this research. The following aspects are not included in the scope of our study:
- Context of technology and infrastructure for data mining/data analytics tasks and projects.
- Granular methods application in data mining process itself or their application for data mining tasks, for example, constructing business queries or applying regression or neural networks modeling techniques to solve classification problems. Studies with granular methods are included in primary texts corpus as long as method application is part of overall methodological approach.
- Technological aspects in data mining for example, data engineering, dataflows and workflows.
- Traditional statistical methods not associated with data mining directly including statistical control methods.
Similarly to Budgen et al. (2006) and Levy & Ellis (2006) , initial piloting revealed that search engines retrieved literature available for all major scientific domains including ones outside authors’ area of expertise (e.g., medicine). Even though such studies could be retrieved, it would be impossible for us to analyze and correctly interpret literature published outside the possessed area of expertise. The adjustments toward search strategy were undertaken by retaining domains closely associated with Information Systems, Software Engineering research. Thus, for Scopus database the final set of inclusive domains was limited to nine and included Computer Science, Engineering, Mathematics, Business, Management and Accounting, Decision Science, Economics, Econometrics and Finance, and Multidisciplinary as well as Undefined studies. Excluded domains covered 11.5% or 106 out of 925 publications; it was confirmed in validation process that they primarily focused on specific case studies in fundamental sciences and medicine 3 . The included domains from Scopus database were mapped to Web of Science to ensure consistent approach across databases and the correctness of mapping was validated.
Screening criteria and procedures
Based on the SLR practices (as in Kitchenham, Budgen & Brereton (2015) , Brereton et al. (2007) ) and defined SLR scope, we designed multi-step screening procedures (quality and relevancy) with associated set of Screening Criteria and Scoring System . The purpose of relevancy screening is to find relevant primary studies in an unbiased way ( Vanwersch et al., 2011 ). Quality screening, on the other hand, aims to assess primary relevant studies in terms of quality in unbiased way.
Screening Criteria consisted of two subsets— Exclusion Criteria applied for initial filtering and Relevance Criteria , also known as Inclusion Criteria .
Exclusion Criteria were initial threshold quality controls aiming at eliminating studies with limited or no scientific contribution. The exclusion criteria also address issues of understandability, accessability and availability. The Exclusion Criteria were as follows:
- Quality 1: The publication item is not in English (understandability).
- either the same document retrieved from two or all three databases.
- or different versions of the same publication are retrieved (i.e., the same study published in different sources)—based on best practices, decision rule is that the most recent paper is retained as well as the one with the highest score ( Kofod-Petersen, 2014 ).
- if a publication is published both as conference proceeding and as journal article with the same name and same authors or as an extended version of conference paper, the latter is selected.
- Quality 3: Length of the publication is less than 6 pages—short papers do not have the space to expand and discuss presented ideas in sufficient depth to examine for us.
- Quality 4: The paper is not accessible in full length online through the university subscription of databases and via Google Scholar—not full availability prevents us from assessing and analyzing the text.
The initially retrieved list of papers was filtered based on Exclusion Criteria . Only papers that passed all criteria were retained in the final studies corpus. Mapping of criteria towards screening steps is exhibited in Fig. 4 .

Relevance Criteria were designed to identify relevant publications and are presented in Table 2 below while mapping to respective process steps is presented in Fig. 4 . These criteria were applied iteratively.
| Relevance criteria | Criteria definition | Criteria justification |
|---|---|---|
| Relevance 1 | Is the study about data mining or data analytics approach and is within designated list of domains? | Exclude studies conducted outside the designated domain list. Exclude studies not directly describing and/or discussing data mining and data analytics |
| Relevance 2 | Is the study introducing/describing data mining or data analytics methodology/framework or modifying existing approaches? | Exclude texts considering only specific, granular data mining and data analytics techniques, methods or traditional statistical methods. Exclude publications focusing on specific, granular data mining and data analytics process/sub-process aspects. Exclude texts where description and discussion of data mining methodologies or frameworks is manifestly missing |
As a final SLR step, the full texts quality assessment was performed with constructed Scoring Metrics (in line with Kitchenham & Charters (2007) ). It is presented in the Table 3 below.
| Score | Criteria definition |
|---|---|
| 3 | Data mining methodology or framework is presented in full. All steps described and explained, tests performed, results compared and evaluated. There is clear proposal on usage, application, deployment of solution in organization’s business process(es) and IT/IS system, and/or prototype or full solution implementation is discussed. Success factors described and presented |
| 2 | Data mining methodology or framework is presented, some process steps are missing, but they do not impact the holistic view and understanding of the performed work. Data mining process is clearly presented and described, tests performed, results compared and evaluated. There is proposal on usage, application, deployment of solution in organization’s business process(es) and IT/IS system(s) |
| 1 | Data mining methodology or framework is not presented in full, some key phases and process steps are missing. Publication focuses on one or some aspects (e.g., method, technique) |
| 0 | Data mining methodology or framework not presented as holistic approach, but on fragmented basis, study limited to some aspects (e.g., method or technique discussion, etc.) |
Data extraction and screening process
The conducted data extraction and screening process is presented in Fig. 4 . In Step 1 initial publications list were retrieved from pre-defined databases—Scopus, Web of Science, Google Scholar. The lists were merged and duplicates eliminated in Step 2. Afterwards, texts being less than 6 pages were excluded (Step 3). Steps 1–3 were guided by Exclusion Criteria . In the next stage (Step 4), publications were screened by Title based on pre-defined Relevance Criteria . The ones which passed were evaluated by their availability (Step 5). As long as study was available, it was evaluated again by the same pre-defined Relevance Criteria applied to Abstract, Conclusion and if necessary Introduction (Step 6). The ones which passed this threshold formed primary publications corpus extracted from databases in full. These primary texts were evaluated again based on full text (Step 7) applying Relevance Criteria first and then Scoring Metrics .
Results and quantitative analysis
In Step 1, 1,715 publications were extracted from relevant databases with the following composition—Scopus (819), Web of Science (489), Google Scholar (407). In terms of scientific publication domains, Computer Science (42.4%), Engineering (20.6%), Mathematics (11.1%) accounted for app. 74% of Scopus originated texts. The same applies to Web of Science harvest. Exclusion Criteria application produced the following results. In Step 2, after eliminating duplicates, 1,186 texts were passed for minimum length evaluation, and 767 reached assessment by Relevancy Criteria .
As mentioned Relevance Criteria were applied iteratively (Step 4–6) and in conjunction with availability assessment. As a result, only 298 texts were retained for full evaluation with 241 originating from scientific databases while 57 were ‘grey’. These studies formed primary texts corpus which was extracted, read in full and evaluated by Relevance Criteria combined with Scoring Metrics . The decision rule was set as follows. Studies that scored “1” or “0” were rejected, while texts with “3” and “2” evaluation were admitted as final primary studies corpus. To this end, as an outcome of SLR-based, broad, cross-domain publications collection and screening we identified 207 relevant publications from peer-reviewed (156 texts) and ‘grey’ literature (51 texts). Figure 5 below exhibits yearly published research numbers with the breakdown by ‘peer-reviewed’ and ‘grey’ literature starting from 1997.

In terms of composition, ‘peer-reviewed’ studies corpus is well-balanced with 72 journal articles and 82 conference papers while book chapters account for 4 instances only. In contrast, in ‘grey’ literature subset, articles in moderated and non-peer reviewed journals are dominant ( n = 34) compared to overall number of conference papers ( n = 13), followed by small number of technical reports and pre-prints ( n = 4).
Temporal analysis of texts corpus (as per Fig. 5 below) resulted in two observations. Firstly, we note that stable and significant research interest (in terms of numbers) on data mining methodologies application has started around a decade ago—in 2007. Research efforts made prior to 2007 were relatively limited with number of publications below 10. Secondly, we note that research on data mining methodologies has grown substantially since 2007, an observation supported by the 3-year and 10-year constructed mean trendlines. In particular, the number of publications have roughly tripled over past decade hitting all time high with 24 texts released in 2017.
Further, there are also two distinct spike sub-periods in the years 2007–2009 and 2014–2017 followed by stable pattern with overall higher number of released publications on annual basis. This observation is in line with the trend of increased penetration of methodologies, tools, cross-industry applications and academic research of data mining.
Findings and Discussion
In this section, we address the research questions of the paper. Initially, as part of RQ1, we present overview of data mining methodologies ‘as-is’ and adaptation trends. In addressing RQ2, we further classify the adaptations identified. Then, as part of RQ3 subsection, each category identified under RQ2 is analyzed with particular focus on the goals of adaptations.
RQ1: How data mining methodologies are applied (‘as-is’ vs. adapted)?
The first research question examines the extent to which data mining methodologies are used ‘as-is’ versus adapted. Our review based on 207 publications identified two distinct paradigms on how data mining methodologies are applied. The first is ‘as-is’ where the data mining methodologies are applied as stipulated. The second is with ‘adaptations’; that is, methodologies are modified by introducing various changes to the standard process model when applied.
We have aggregated research by decades to differentiate application pattern between two time periods 1997–2007 with limited vs 2008–2018 with more intensive data mining application. The given cut has not only been guided by extracted publications corpus but also by earlier surveys. In particular, during the pre-2007 research, there where ten new methodologies proposed, but since then, only two new methodologies have been proposed. Thus, there is a distinct trend observed over the last decade of large number of extensions and adaptations proposed vs entirely new methodologies.
We note that during the first decade of our time scope (1997–2007), the ratio of data mining methodologies applied ‘as-is’ was 40% (as presented in Fig. 6A ). However, the same ratio for the following decade is 32% ( Fig. 6B ). Thus, in terms of relative shares we note a clear decrease in using data mining methodologies ‘as-is’ in favor of adapting them to cater to specific needs.The trend is even more pronounced when comparing numbers—adaptations more than tripled (from 30 to 106) while ‘as-is’ scenario has increased modestly (from 20 to 51). Given this finding, we continue with analyzing how data mining methodologies have been adapted under RQ2.

RQ2: How have existing data mining methodologies been adapted?
We identified that data mining methodologies have been adapted to cater to specific needs. In order to categorize adaptations scenarios, we applied a two-level dichotomy, specifically, by applying the following decision tree:
- Level 1 Decision: Has the methodology been combined with another methodology? If yes, the resulting methodology was classified in the ‘integration’ category. Otherwise, we posed the next question.
- Level 2 Decision: Are any new elements (phases, tasks, deliverables) added to the methodology? If yes, we designate the resulting methodology as an ‘extension’ of the original one. Otherwise, we classify the resulting methodology as a modification of the original one.
Thus, when adapted three distinct types of adaptation scenarios can be distinguished:
- Scenario ‘Modification’: introduces specialized sub-tasks and deliverables in order to address specific use cases or business problems. Modifications typically concentrate on granular adjustments to the methodology at the level of sub-phases, tasks or deliverables within the existing reference frameworks (e.g., CRISP-DM or KDD) stages. For example, Chernov et al. (2014) , in the study of mobile network domain, proposed automated decision-making enhancement in the deployment phase. In addition, the evaluation phase was modified by using both conventional and own-developed performance metrics. Further, in a study performed within the financial services domain, Yang et al. (2016) presents feature transformation and feature selection as sub-phases, thereby enhancing the data mining modeling stage.
- Scenario ‘Extension’: primarily proposes significant extensions to reference data mining methodologies. Such extensions result in either integrated data mining solutions, data mining frameworks serving as a component or tool for automated IS systems, or their transformations to fit specialized environments. The main purposes of extensions are to integrate fully-scaled data mining solutions into IS/IT systems and business processes and provide broader context with useful architectures, algorithms, etc. Adaptations, where extensions have been made, elicit and explicitly present various artifacts in the form of system and model architectures, process views, workflows, and implementation aspects. A number of soft goals are also achieved, providing holistic perspective on data mining process, and contextualizing with organizational needs. Also, there are extensions in this scenario where data mining process methodologies are substantially changed and extended in all key phases to enable execution of data mining life-cycle with the new (Big) Data technologies, tools and in new prototyping and deployment environments (e.g., Hadoop platforms or real-time customer interfaces). For example, Kisilevich, Keim & Rokach (2013) presented extensions to traditional CRISP-DM data mining outcomes with fully fledged Decision Support System (DSS) for hotel brokerage business. Authors ( Kisilevich, Keim & Rokach, 2013 ) have introduced spatial/non-spatial data management (extending data preparation), analytical and spatial modeling capabilities (extending modeling phase), provided spatial display and reporting capabilities (enhancing deployment phase). In the same work domain knowledge was introduced in all phases of data mining process, and usability and ease of use were also addressed.
- Scenario ‘Integration’: combines reference methodology, for example, CRISP-DM with: (1) data mining methodologies originated from other domains (e.g., Software engineering development methodologies), (2) organizational frameworks (Balanced Scorecard, Analytics Canvass, etc.), or (3) adjustments to accommodate Big Data technologies and tools. Also, adaptations in the form of ‘Integration’ typically introduce various types of ontologies and ontology-based tools, domain knowledge, software engineering, and BI-driven framework elements. Fundamental data mining process adjustments to new types of data, IS architectures (e.g., real time data, multi-layer IS) are also presented. Key gaps addressed with such adjustments are prescriptive nature and low degree of formalization in CRISP-DM, obsolete nature of CRISP-DM with respect to tools, and lack of CRISP-DM integration with other organizational frameworks. For example, Brisson & Collard (2008) developed KEOPS data mining methodology (CRIPS-DM based) centered on domain knowledge integration. Ontology-driven information system has been proposed with integration and enhancements to all steps of data mining process. Further, an integrated expert knowledge used in all data mining phases was proved to produce value in data mining process.
To examine how the application scenario of each data mining methodology usage has developed over time, we mapped peer-reviewed texts and ‘grey’ literature to respective adaptation scenarios, aggregated by decades (as presented in the Fig. 7 for peer-reviewed and Fig. 8 for ‘grey’).

For peer-reviewed research, such temporal analysis resulted in three observations. Firstly, research efforts in each adaptation scenario has been growing and number of publication more than quadrupled (128 vs. 28). Secondly, as noted above relative proportion of ‘as-is’ studies is diluted (from 39% to 33%) and primarily replaced with ‘Extension’ paradigm (from 25% to 30%). In contrast, in relative terms ‘Modification’ and ‘Integration’ paradigms gains are modest. Further, this finding is reinforced with other observation—most notable gaps in terms of modest number of publications remain in ‘Integration’ category where excluding 2008–2009 spike, research efforts are limited and number of texts is just 13. This is in stark contrast with prolific research in ‘Extension category’ though concentrated in the recent years. We can hypothesize that existing reference methodologies do not accommodate and support increasing complexity of data mining projects and IS/IT infrastructure, as well as certain domains specifics and as such need to be adapted.
In ‘grey’ literature, in contrast to peer-reviewed research, growth in number of publications is less profound—29 vs. 22 publications or 32% comparing across two decade (as per Fig. 8 ). The growth is solely driven by ‘Integration’ scenarios application (13 vs. 4 publications) while both ‘as-is’ and other adaptations scenarios are stagnating or in decline.
RQ3: For what purposes have existing data mining methodologies been adapted?
We address the third research question by analyzing what gaps the data mining methodology adaptations seek to fill and the benefits of such adaptations. We identified three adaptation scenarios, namely ‘Modification’, ‘Extension’, and ‘Integration’. Here, we analyze each of them.
Modification
Modifications of data mining methodologies are present in 30 peer-reviewed and 4 ‘grey’ literature studies. The analysis shows that modifications overwhelmingly consist of specific case studies. However, the major differentiating point compared to ‘as-is’ case studies is clear presence of specific adjustments towards standard data mining process methodologies. Yet, the proposed modifications and their purposes do not go beyond traditional data mining methodologies phases. They are granular, specialized and executed on tasks, sub-tasks, and at deliverables level. With modifications, authors describe potential business applications and deployment scenarios at a conceptual level, but typically do not report or present real implementations in the IS/IT systems and business processes.
Further, this research subcategory can be best classified based on domains where case studies were performed and data mining methodologies modification scenarios executed. We have identified four distinct domain-driven applications presented in the Fig. 9 .

IT, IS domain
The largest number of publications (14 or app. 40%), was performed on IT, IS security, software development, specific data mining and processing topics. Authors address intrusion detection problem in Hossain, Bridges & Vaughn (2003) , Fan, Ye & Chen (2016) , Lee, Stolfo & Mok (1999) , specialized algorithms for variety of data types processing in Yang & Shi (2010) , Chen et al. (2001) , Yi, Teng & Xu (2016) , Pouyanfar & Chen (2016) , effective and efficient computer and mobile networks management in Guan & Fu (2010) , Ertek, Chi & Zhang (2017) , Zaki & Sobh (2005) , Chernov, Petrov & Ristaniemi (2015) , Chernov et al. (2014) .
Manufacturing and engineering
The next most popular research area is manufacturing/engineering with 10 case studies. The central topic here is high-technology manufacturing, for example, semi-conductors associated—study of Chien, Diaz & Lan (2014) , and various complex prognostics case studies in rail, aerospace domains ( Létourneau et al., 2005 ; Zaluski et al., 2011 ) concentrated on failure predictions. These are complemented by studies on equipment fault and failure predictions and maintenance ( Kumar, Shankar & Thakur, 2018 ; Kang et al., 2017 ; Wang, 2017 ) as well as monitoring system ( García et al., 2017 ).
Sales and services, incl. financial industry
The third category is presented by seven business application papers concerning customer service, targeting and advertising ( Karimi-Majd & Mahootchi, 2015 ; Reutterer et al., 2017 ; Wang, 2017 ), financial services credit risk assessments ( Smith, Willis & Brooks, 2000 ), supply chain management ( Nohuddin et al., 2018 ), and property management ( Yu, Fung & Haghighat, 2013 ), and similar.
As a consequence of specialization, these studies concentrate on developing ‘state-of-the art’ solution to the respective domain-specific problem.
‘Extension’ scenario was identified in 46 peer-reviewed and 12 ‘grey’ publications. We noted that ‘Extension’ to existing data mining methodologies were executed with four major purposes:
- Purpose 1: To implement fully scaled, integrated data mining solution and regular, repeatable knowledge discovery process— address model, algorithm deployment, implementation design (including architecture, workflows and corresponding IS integration). Also, complementary goal is to tackle changes to business process to incorporate data mining into organization activities.
- Purpose 2: To implement complex, specifically designed systems and integrated business applications with data mining model/solution as component or tool. Typically, this adaptation is also oriented towards Big Data specifics, and is complemented by proposed artifacts such as Big Data architectures, system models, workflows, and data flows.
- Purpose 3: To implement data mining as part of integrated/combined specialized infrastructure, data environments and types (e.g., IoT, cloud, mobile networks) .
- Purpose 4: To incorporate context-awareness aspects.
The specific list of studies mapped to each of the given purposes presented in the Appendix ( Table A1 ). Main purposes of adaptations, associated gaps and/or benefits along with observations and artifacts are documented in the Fig. 10 below.

| Main adaptation purpose | Publications |
|---|---|
| (1) To implement fully scaled, integrated data mining solution | , , , , , , , , , , , , , , , |
| (2) To implement complex systems and integrated business applications with data mining model/solution as component or tool | , , , , , , , , , , , , , , , , , , , |
| (3) To implement data mining as part of integrated/combined specialized infrastructure,data environments and types (e.g., IoT, cloud, mobile networks) | , , , , , , , , , , , , , , , , , , , , |
| (4) To incorporate context-awareness aspects |
In ‘Extension’ category, studies executed with the Purpose 1 propose fully scaled, integrated data mining solutions of specific data mining models, associated frameworks and processes. The distinctive trait of this research subclass is that it ensures repeatability and reproducibility of delivered data mining solution in different organizational and industry settings. Both the results of data mining use case as well as deployment and integration into IS/IT systems and associated business process(es) are presented explicitly. Thus, ‘Extension’ subclass is geared towards specific solution design, tackling concrete business or industrial setting problem or addressing specific research gaps thus resembling comprehensive case study.
This direction can be well exemplified by expert finder system in research social network services proposed by Sun et al. (2015) , data mining solution for functional test content optimization by Wang (2015) and time-series mining framework to conduct estimation of unobservable time-series by Hu et al. (2010) . Similarly, Du et al. (2017) tackle online log anomalies detection, automated association rule mining is addressed by Çinicioğlu et al. (2011) , software effort estimation by Deng, Purvis & Purvis (2011) , network patterns visual discovery by Simoff & Galloway (2008) . Number of studies address solutions in IS security ( Shin & Jeong, 2005 ), manufacturing ( Güder et al., 2014 ; Chee, Baharudin & Karkonasasi, 2016 ), materials engineering domains ( Doreswamy, 2008 ), and business domains ( Xu & Qiu, 2008 ; Ding & Daniel, 2007 ).
In contrast, ‘Extension’ studies executed for the Purpose 2 concentrate on design of complex, multi-component information systems and architectures. These are holistic, complex systems and integrated business applications with data mining framework serving as component or tool. Moreover, data mining methodology in these studies is extended with systems integration phases.
For example, Mobasher (2007) presents data mining application in Web personalization system and associated process; here, data mining cycle is extended in all phases with utmost goal of leveraging multiple data sources and using discovered models and corresponding algorithms in an automatic personalization system. Authors comprehensively address data processing, algorithm, design adjustments and respective integration into automated system. Similarly, Haruechaiyasak, Shyu & Chen (2004) tackle improvement of Webpage recommender system by presenting extended data mining methodology including design and implementation of data mining model. Holistic view on web-mining with support of all data sources, data warehousing and data mining techniques integration, as well as multiple problem-oriented analytical outcomes with rich business application scenarios (personalization, adaptation, profiling, and recommendations) in e-commerce domain was proposed and discussed by Büchner & Mulvenna (1998) . Further, Singh et al. (2014) tackled scalable implementation of Network Threat Intrusion Detection System. In this study, data mining methodology and resulting model are extended, scaled and deployed as module of quasi-real-time system for capturing Peer-to-Peer Botnet attacks. Similar complex solution was presented in a series of publications by Lee et al. (2000 , 2001) who designed real-time data mining-based Intrusion Detection System (IDS). These works are complemented by comprehensive study of Barbará et al. (2001) who constructed experimental testbed for intrusion detection with data mining methods. Detection model combining data fusion and mining and respective components for Botnets identification was developed by Kiayias et al. (2009) too. Similar approach is presented in Alazab et al. (2011) who proposed and implemented zero-day malware detection system with associated machine-learning based framework. Finally, Ahmed, Rafique & Abulaish (2011) presented multi-layer framework for fuzzy attack in 3G cellular IP networks.
A number of authors have considered data mining methodologies in the context of Decision Support Systems and other systems that generate information for decision-making, across a variety of domains. For example, Kisilevich, Keim & Rokach (2013) executed significant extension of data mining methodology by designing and presenting integrated Decision Support System (DSS) with six components acting as supporting tool for hotel brokerage business to increase deal profitability. Similar approach is undertaken by Capozzoli et al. (2017) focusing on improving energy management of properties by provision of occupancy pattern information and reconfiguration framework. Kabir (2016) presented data mining information service providing improved sales forecasting that supported solution of under/over-stocking problem while Lau, Zhang & Xu (2018) addressed sales forecasting with sentiment analysis on Big Data. Kamrani, Rong & Gonzalez (2001) proposed GA-based Intelligent Diagnosis system for fault diagnostics in manufacturing domain. The latter was tackled further in Shahbaz et al. (2010) with complex, integrated data mining system for diagnosing and solving manufacturing problems in real time.
Lenz, Wuest & Westkämper (2018) propose a framework for capturing data analytics objectives and creating holistic, cross-departmental data mining systems in the manufacturing domain. This work is representative of a cohort of studies that aim at extending data mining methodologies in order to support the design and implementation of enterprise-wide data mining systems. In this same research cohort, we classify Luna, Castro & Romero (2017) , which presents a data mining toolset integrated into the Moodle learning management system, with the aim of supporting university-wide learning analytics.
One study addresses multi-agent based data mining concept. Khan, Mohamudally & Babajee (2013) have developed unified theoretical framework for data mining by formulating a unified data mining theory. The framework is tested by means of agent programing proposing integration into multi-agent system which is useful due to scalability, robustness and simplicity.
The subcategory of ‘Extension’ research executed with Purpose 3 is devoted to data mining methodologies and solutions in specialized IT/IS, data and process environments which emerged recently as consequence of Big Data associated technologies and tools development. Exemplary studies include IoT associated environment research, for example, Smart City application in IoT presented by Strohbach et al. (2015) . In the same domain, Bashir & Gill (2016) addressed IoT-enabled smart buildings with the additional challenge of large amount of high-speed real time data and requirements of real-time analytics. Authors proposed integrated IoT Big Data Analytics framework. This research is complemented by interdisciplinary study of Zhong et al. (2017) where IoT and wireless technologies are used to create RFID-enabled environment producing analysis of KPIs to improve logistics.
Significant number of studies addresses various mobile environments sometimes complemented by cloud-based environments or cloud-based environments as stand-alone. Gomes, Phua & Krishnaswamy (2013) addressed mobile data mining with execution on mobile device itself; the framework proposes innovative approach addressing extensions of all aspects of data mining including contextual data, end-user privacy preservation, data management and scalability. Yuan, Herbert & Emamian (2014) and Yuan & Herbert (2014) introduced cloud-based mobile data analytics framework with application case study for smart home based monitoring system. Cuzzocrea, Psaila & Toccu (2016) have presented innovative FollowMe suite which implements data mining framework for mobile social media analytics with several tools with respective architecture and functionalities. An interesting paper was presented by Torres et al. (2017) who addressed data mining methodology and its implementation for congestion prediction in mobile LTE networks tackling also feedback reaction with network reconfigurations trigger.
Further, Biliri et al. (2014) presented cloud-based Future Internet Enabler—automated social data analytics solution which also addresses Social Network Interoperability aspect supporting enterprises to interconnect and utilize social networks for collaboration. Real-time social media streamed data and resulting data mining methodology and application was extensively discussed by Zhang, Lau & Li (2014) . Authors proposed design of comprehensive ABIGDAD framework with seven main components implementing data mining based deceptive review identification. Interdisciplinary study tackling both these topics was developed by Puthal et al. (2016) who proposed integrated framework and architecture of disaster management system based on streamed data in cloud environment ensuring end-to-end security. Additionally, key extensions to data mining framework have been proposed merging variety of data sources and types, security verification and data flow access controls. Finally, cloud-based manufacturing was addressed in the context of fault diagnostics by Kumar et al. (2016) .
Also, Mahmood et al. (2013) tackled Wireless Sensor Networks and associated data mining framework required extensions. Interesting work is executed by Nestorov & Jukic (2003) addressing rare topic of data mining solutions integration within traditional data warehouses and active mining of data repositories themselves.
Supported by new generation of visualization technologies (including Virtual Reality environments), Wijayasekara, Linda & Manic (2011) proposed and implemented CAVE-SOM (3D visual data mining framework) which offers interactive, immersive visual data mining with multiple visualization modes supported by plethora of methods. Earlier version of visual data mining framework was successfully developed and presented by Ganesh et al. (1996) as early as in 1996.
Large-scale social media data is successfully tackled by Lemieux (2016) with comprehensive framework accompanied by set of data mining tools and interface. Real time data analytics was addressed by Shrivastava & Pal (2017) in the domain of enterprise service ecosystem. Images data was addressed in Huang et al. (2002) by proposing multimedia data mining framework and its implementation with user relevance feedback integration and instance learning. Further, exploded data diversity and associated need to extend standard data mining is addressed by Singh et al. (2016) in the study devoted to object detection in video surveillance systems supporting real time video analysis.
Finally, there is also limited number of studies which addresses context awareness (Purpose 4) and extends data mining methodology with context elements and adjustments. In comparison with ‘Integration’ category research, here, the studies are at lower abstraction level, capturing and presenting list of adjustments. Singh, Vajirkar & Lee (2003) generate taxonomy of context factors, develop extended data mining framework and propose deployment including detailed IS architecture. Context-awareness aspect is also addressed in the papers reviewed above, for example, Lenz, Wuest & Westkämper (2018) , Kisilevich, Keim & Rokach (2013) , Sun et al. (2015) , and other studies.
Integration
‘Integration’ of data mining methodologies scenario was identified in 27 ‘peer-reviewed’ and 17 ‘grey’ studies. Our analysis revealed that this adaptation scenario at a higher abstraction level is typically executed with the five key purposes:
- Purpose 1: to integrate/combine with various ontologies existing in organization .
- Purpose 2: to introduce context-awareness and incorporate domain knowledge .
- Purpose 3: to integrate/combine with other research or industry domains framework, process methodologies and concepts .
- Purpose 4: to integrate/combine with other well-known organizational governance frameworks, process methodologies and concepts .
- Purpose 5: to accommodate and/or leverage upon newly available Big Data technologies, tools and methods.
The specific list of studies mapped to each of the given purposes presented in Appendix ( Table A2 ). Main purposes of adaptations, associated gaps and/or benefits along with observations and artifacts are documented in Fig. 11 below.

| Main adaptation purpose | Publications |
|---|---|
| (1) To integrate/combined with various ontologies existing in organization | , , , , , |
| (2) To introduce context-awareness and incorporate domain knowledge | , , , , , , |
| (3) To integrate/combine with other research/industry domains frameworks, process methodologies, and concepts | , , , , , , , , , , , , , |
| (4) To integrate/combine with other organizational governance frameworks, process methodologies, concepts | , , , , , , , , |
| (5) To accomodate or leverage upon newly available Big Data technologies, tools and methods | , , , , , , |
As mentioned, number of studies concentrates on proposing ontology-based Integrated data mining frameworks accompanies by various types of ontologies (Purpose 1). For example, Sharma & Osei-Bryson (2008) focus on ontology-based organizational view with Actors, Goals and Objectives which supports execution of Business Understanding Phase. Brisson & Collard (2008) propose KEOPS framework which is CRISP-DM compliant and integrates a knowledge base and ontology with the purpose to build ontology-driven information system (OIS) for business and data understanding phases while knowledge base is used for post-processing step of model interpretation. Park et al. (2017) propose and design comprehensive ontology-based data analytics tool IRIS with the purpose to align analytics and business. IRIS is based on concept to connect dots, analytics methods or transforming insights into business value, and supports standardized process for applying ontology to match business problems and solutions.
Further, Ying et al. (2014) propose domain-specific data mining framework oriented to business problem of customer demand discovery. They construct ontology for customer demand and customer demand discovery task which allows to execute structured knowledge extraction in the form of knowledge patterns and rules. Here, the purpose is to facilitate business value realization and support actionability of extracted knowledge via marketing strategies and tactics. In the same vein, Cannataro & Comito (2003) presented ontology for the Data Mining domain which main goal is to simplify the development of distributed knowledge discovery applications. Authors offered to a domain expert a reference model for different kind of data mining tasks, methodologies, and software capable to solve the given business problem and find the most appropriate solution.
Apart from ontologies, Sharma & Osei-Bryson (2009) in another study propose IS inspired, driven by Input-Output model data mining methodology which supports formal implementation of Business Understanding Phase. This research exemplifies studies executed with Purpose 2. The goal of the paper is to tackle prescriptive nature of CRISP-DM and address how the entire process can be implemented. Cao, Schurmann & Zhang (2005) study is also exemplary in terms of aggregating and introducing several fundamental concepts into traditional CRISP-DM data mining cycle—context awareness, in-depth pattern mining, human–machine cooperative knowledge discovery (in essence, following human-centricity paradigm in data mining), loop-closed iterative refinement process (similar to Agile-based methodologies in Software Development). There are also several concepts, like data, domain, interestingness, rules which are proposed to tackle number of fundamental constrains identified in CRISP-DM. They have been discussed and further extended by Cao & Zhang (2007 , 2008) , Cao (2010) into integrated domain driven data mining concept resulting in fully fledged D3M (domain-driven) data mining framework. Interestingly, the same concepts, but on individual basis are investigated and presented by other authors, for example, context-aware data mining methodology is tackled by Xiang (2009a , 2009b) in the context of financial sector. Pournaras et al. (2016) attempted very crucial privacy-preservation topic in the context of achieving effective data analytics methodology. Authors introduced metrics and self-regulatory (reconfigurable) information sharing mechanism providing customers with controls for information disclosure.
A number of studies have proposed CRISP-DM adjustments based on existing frameworks, process models or concepts originating in other domains (Purpose 3), for example, software engineering ( Marbán et al., 2007 , 2009 ; Marban, Mariscal & Segovia, 2009 ) and industrial engineering ( Solarte, 2002 ; Zhao et al., 2005 ).
Meanwhile, Mariscal, Marbán & Fernández (2010) proposed a new refined data mining process based on a global comparative analysis of existing frameworks while Angelov (2014) outlined a data analytics framework based on statistical concepts. Following a similar approach, some researchers suggest explicit integration with other areas and organizational functions, for example, BI-driven Data Mining by Hang & Fong (2009) . Similarly, Chen, Kazman & Haziyev (2016) developed an architecture-centric agile Big Data analytics methodology, and an architecture-centric agile analytics and DevOps model. Alternatively, several authors tackled data mining methodology adaptations in other domains, for example, educational data mining by Tavares, Vieira & Pedro (2017) , decision support in learning management systems ( Murnion & Helfert, 2011 ), and in accounting systems ( Amani & Fadlalla, 2017 ).
Other studies are concerned with actionability of data mining and closer integration with business processes and organizational management frameworks (Purpose 4). In particular, there is a recurrent focus on embedding data mining solutions into knowledge-based decision making processes in organizations, and supporting fast and effective knowledge discovery ( Bohanec, Robnik-Sikonja & Borstnar, 2017 ).
Examples of adaptations made for this purpose include: (1) integration of CRISP-DM with the Balanced Scorecard framework used for strategic performance management in organizations ( Yun, Weihua & Yang, 2014 ); (2) integration with a strategic decision-making framework for revenue management Segarra et al. (2016) ; (3) integration with a strategic analytics methodology Van Rooyen & Simoff (2008) , and (4) integration with a so-called ‘Analytics Canvas’ for management of portfolios of data analytics projects Kühn et al. (2018) . Finally, Ahangama & Poo (2015) explored methodological attributes important for adoption of data mining methodology by novice users. This latter study uncovered factors that could support the reduction of resistance to the use of data mining methodologies. Conversely, Lawler & Joseph (2017) comprehensively evaluated factors that may increase the benefits of Big Data Analytics projects in an organization.
Lastly, a number of studies have proposed data mining frameworks (e.g., CRISP-DM) adaptations to cater for new technological architectures, new types of datasets and applications (Purpose 5). For example, Lu et al. (2017) proposed a data mining system based on a Service-Oriented Architecture (SOA), Zaghloul, Ali-Eldin & Salem (2013) developed a concept of self-service data analytics, Osman, Elragal & Bergvall-Kåreborn (2017) blended CRISP-DM into a Big Data Analytics framework for Smart Cities, and Niesen et al. (2016) proposed a data-driven risk management framework for Industry 4.0 applications.
Our analysis of RQ3, regarding the purposes of existing data mining methodologies adaptations, revealed the following key findings. Firstly, adaptations of type ‘Modification’ are predominantly targeted at addressing problems that are specific to a given case study. The majority of modifications were made within the domain of IS security, followed by case studies in the domains of manufacturing and financial services. This is in clear contrast with adaptations of type ‘Extension’, which are primarily aimed at customizing the methodology to take into account specialized development environments and deployment infrastructures, and to incorporate context-awareness aspects. Thirdly, a recurrent purpose of adaptations of type ‘Integration’ is to combine a data mining methodology with either existing ontologies in an organization or with other domain frameworks, methodologies, and concepts. ‘Integration’ is also used to instill context-awareness and domain knowledge into a data mining methodology, or to adapt it to specialized methods and tools, such as Big Data. The distinctive outcome and value (gaps filled in) of ‘Integrations’ stems from improved knowledge discovery, better actionability of results, improved combination with key organizational processes and domain-specific methodologies, and improved usage of Big Data technologies.
We discovered that the adaptations of existing data mining methodologies found in the literature can be classified into three categories: modification, extension, or integration.
We also noted that adaptations are executed either to address deficiencies and lack of important elements or aspects in the reference methodology (chiefly CRISP-DM). Furthermore, adaptations are also made to improve certain phases, deliverables or process outcomes.
In short, adaptations are made to:
- improve key reference data mining methodologies phases—for example, in case of CRISP-DM these are primarily business understanding and deployment phases.
- support knowledge discovery and actionability.
- introduce context-awareness and higher degree of formalization.
- integrate closer data mining solution with key organizational processes and frameworks.
- significantly update CRISP-DM with respect to Big Data technologies, tools, environments and infrastructure.
- incorporate broader, explicit context of architectures, algorithms and toolsets as integral deliverables or supporting tools to execute data mining process.
- expand and accommodate broader unified perspective for incorporating and implementing data mining solutions in organization, IT infrastructure and business processes.
Threats to Validity
Systematic literature reviews have inherent limitations that must be acknowledged. These threats to validity include subjective bias (internal validity) and incompleteness of search results (external validity).
The internal validity threat stems from the subjective screening and rating of studies, particularly when assessing the studies with respect to relevance and quality criteria. We have mitigated these effects by documenting the survey protocol (SLR Protocol), strictly adhering to the inclusion criteria, and performing significant validation procedures, as documented in the Protocol.
The external validity threat relates to the extent to which the findings of the SLR reflect the actual state of the art in the field of data mining methodologies, given that the SLR only considers published studies that can be retrieved using specific search strings and databases. We have addressed this threat to validity by conducting trial searches to validate our search strings in terms of their ability to identify relevant papers that we knew about beforehand. Also, the fact that the searches led to 1,700 hits overall suggests that a significant portion of the relevant literature has been covered.
In this study, we have examined the use of data mining methodologies by means of a systematic literature review covering both peer-reviewed and ‘grey’ literature. We have found that the use of data mining methodologies, as reported in the literature, has grown substantially since 2007 (four-fold increase relative to the previous decade). Also, we have observed that data mining methodologies were predominantly applied ‘as-is’ from 1997 to 2007. This trend was reversed from 2008 onward, when the use of adapted data mining methodologies gradually started to replace ‘as-is’ usage.
The most frequent adaptations have been in the ‘Extension’ category. This category refers to adaptations that imply significant changes to key phases of the reference methodology (chiefly CRISP-DM). These adaptations particularly target the business understanding, deployment and implementation phases of CRISP-DM (or other methodologies). Moreover, we have found that the most frequent purposes of adaptions are: (1) adaptations to handle Big Data technologies, tools and environments (technological adaptations); and (2) adaptations for context-awareness and for integrating data mining solutions into business processes and IT systems (organizational adaptations). A key finding is that standard data mining methodologies do not pay sufficient attention to deployment aspects required to scale and transform data mining models into software products integrated into large IT/IS systems and business processes.
Apart from the adaptations in the ‘Extension’ category, we have also identified an increasing number of studies focusing on the ‘Integration’ of data mining methodologies with other domain-specific and organizational methodologies, frameworks, and concepts. These adaptions are aimed at embedding the data mining methodology into broader organizational aspects.
Overall, the findings of the study highlight the need to develop refinements of existing data mining methodologies that would allow them to seamlessly interact with IT development platforms and processes (technological adaptation) and with organizational management frameworks (organizational adaptation). In other words, there is a need to frame existing data mining methodologies as being part of a broader ecosystem of methodologies, as opposed to the traditional view where data mining methodologies are defined in isolation from broader IT systems engineering and organizational management methodologies.
Supplemental Information
Supplemental information 1.
Unfortunately, we were not able to upload any graph (original png files). Based on Overleaf placed PeerJ template we constructed graphs files based on the template examples. Unfortunately, we were not able to understand why it did not fit, redoing to new formats will change all texts flow and generated pdf file. We submit graphs in archived file as part of supplementary material. We will do our best to redo the graphs further based on instructions from You.
Supplemental Information 2
File starts with Definitions page—it lists and explains all columns definitions as well as SLR scoring metrics. Second page contains"Peer reviewed" texts while next one "grey" literature corpus.
Funding Statement
The authors received no funding for this work.
Additional Information and Declarations
The authors declare that they have no competing interests.
Veronika Plotnikova conceived and designed the experiments, performed the experiments, analyzed the data, performed the computation work, prepared figures and/or tables, authored or reviewed drafts of the paper, and approved the final draft.
Marlon Dumas conceived and designed the experiments, authored or reviewed drafts of the paper, and approved the final draft.
Fredrik Milani conceived and designed the experiments, authored or reviewed drafts of the paper, and approved the final draft.
Primary Sources
You are using an outdated browser. Please upgrade your browser .
T4Tutorials.com
Data mining research topics for ms phd.

I am sharing with you some of the research topics regarding data mining that you can choose for your research proposal for the thesis work of MS, or Ph.D. Degree.
Categorizing the research into 4 categories in this tutorial
Industry-based research in data mining, problem-based research in data mining, topic-based research in data mining.
- 900+ research ideas in data mining
List of some famous Industries in the world for industry-based research in data mining
- Automobile Wholesaling
- Pharmaceuticals Wholesaling
- Life Insurance & Annuities
- Online Computer Software Sales
- Supermarkets & Grocery Stores
- Electric Power Transmission
- IT Consulting
- Wholesale Trade Agents and Brokers
- Retirement & Pension Plans
- Petroleum Refining
- New Car Dealers
- Drug, Cosmetic & Toiletry Wholesaling
- Pharmacy Benefit Management
- Property, Casualty and Direct Insurance
- Colleges & Universities
- Public Schools
- Warehouse Clubs & Supercenters
- Health & Medical Insurance
- Gasoline & Petroleum Wholesaling
- Gasoline & Petroleum Bulk Stations
- Commercial Banking
- Real Estate Loans & Collateralized Debt
- E-Commerce & Online Auctions
- Electronic Part & Equipment Wholesaling
List of some problems for research in data mining.
- Crime Rate Prediction
- Fraud Detection
- Website Evaluation
- Market Analysis
- Financial Analysis
- Customer trend analysis
- Data Warehouse and DBMS
- Multidimensional data model
- OLAP operations
- Example: loan data set
- Data cleaning
- Data transformation
- Data reduction
- Discretization and generating concept hierarchies
- Installing Weka 3 Data Mining System
- Experiments with Weka – filters, discretization
- Task relevant data
- Background knowledge
- Interestingness measures
- Representing input data and output knowledge
- Visualization techniques
- Experiments with Weka – visualization
- Attribute generalization
- Attribute relevance
- Class comparison
- Statistical measures
- Experiments with Weka – using filters and statistics
- Motivation and terminology
- Example: mining weather data
- Basic idea: item sets
- Generating item sets and rules efficiently
- Correlation analysis
- Experiments with Weka – mining association rules
- Basic learning/mining tasks
- Inferring rudimentary rules: 1R algorithm
- Decision trees
- Covering rules
- Experiments with Weka – decision trees, rules
- The prediction task
- Statistical (Bayesian) classification
- Bayesian networks
- Instance-based methods (nearest neighbor)
- Linear models
- Experiments with Weka – Prediction
- Basic issues in clustering
- First conceptual clustering system: Cluster/2
- Partitioning methods: k-means, expectation-maximization (EM)
- Hierarchical methods: distance-based agglomerative and divisible clustering
- Conceptual clustering: Cobweb
- Experiments with Weka – k-means, EM, Cobweb
- Text mining: extracting attributes (keywords), structural approaches (parsing, soft parsing).
- Bayesian approach to classifying text
- Web mining: classifying web pages, extracting knowledge from the web
- Data Mining software and applications
Research Topics Computer Science
Topic Covered
Top 10 research topics of Data Mining | list of research topics of Data Mining | trending research topics of Data Mining | research topics for dissertation in Data Mining | dissertation topics of Data Mining in pdf | dissertation topics in Data Mining | research area of interest Data Mining | example of research paper topics in Data Mining | top 10 research thesis topics of Data Mining | list of research thesis topics of Data Mining| trending research thesis topics of Data Mining | research thesis topics for dissertation in Data Mining | thesis topics of Data Mining in pdf | thesis topics in Data Mining | examples of thesis topics of Data Mining | PhD research topics examples of Data Mining | PhD research topics in Data Mining | PhD research topics in computer science | PhD research topics in software engineering | PhD research topics in information technology | Masters (MS) research topics in computer science | Masters (MS) research topics in software engineering | Masters (MS) research topics in information technology | Masters (MS) thesis topics in Data Mining.
Related Posts:
- What is data mining? What is not data mining?
- Data Stream Mining - Data Mining
- Data Quality in Data Preprocessing for Data Mining
- Frequent pattern Mining, Closed frequent itemset, max frequent itemset in data mining
- Cloud Computing Research Topics for MS PhD
- Semantic Web Research Topics for MS PhD
M.Tech/Ph.D Thesis Help in Chandigarh | Thesis Guidance in Chandigarh

+91-9465330425
Data Mining

- [email protected]
- +91-97 91 62 64 69
List of Research Topics in Data Mining for PhD
Data mining is denoted as the extraction of beneficial data from a large amount of data based on heterogeneous sources . The techniques based on data mining are used to acquire the data that is used for data analysis and future prediction. If you are looking for list of research topics in data mining for phd.
Introduction to Data Mining
Data mining is considered the logical process that is deployed to find beneficial data . After the determination of patterns and information, data mining is deployed to make the decisions. The data mining process is enabling the following functions such as.
- Simulate the speed of creating the informed decisions
- In data, all the repetitive and chaotic noises are examined
- The relevant data is used for the access
Similarly, the elevation of IoT is to increase the vision of real-time data mining processes with billions of data for instance drug detection in the medical field.
How does it work?
Measure the opinion and sentiment of users, fraud detection, spam email filtering, database marketing, credit risk management and more are the notable uses in the data mining process. It is deployed to analyze and explore large quantities of data for the derivation of adequate patterns.
If you are looking for reliable and trustworthy research guidance in data mining projects in addition to on-time project delivery, then reach us and team up with our research experts for the best results. We provide 24/7 support and in-depth research knowledge for research scholars. The research scholars can contact us for more references in data mining. It’s time to discuss the developments of components in data mining.

Components of Data Mining
- Data has to exist in a beneficial format similar to the table or graph
- Application software is used for the data analysis process
- It is used to regulate and store the data in the multidimensional database system
- Data mining is deployed in the process of extraction, transformation, and load transaction of data toward the data warehouse system
- Data access is provided to business analysts and professionals based on information technology
With the help of all these research components of data mining, you may precede your data mining PhD projects. We have a lot of recent research techniques, tools, and protocols to provide the finest list of research topics in data mining for PhD. In addition, here we offer a list of real-time applications in data mining for your reference. Let us check out the novel applications based on data mining.
Applications in Data Mining
- Predictive agriculture to track the crop’s health
- Sentiment analysis for the intention prevention
- Network intrusion detection and prevention
- Online transaction fraud detection system
- Opinion mining from social network
For add-on information, all the research field has their research issues or challenges. Similarly, the research problems in data mining are highlighted by our research experts with the appropriate analysis in the following.
Challenges in Data Mining
- Information about integration is required from the heterogeneous database and the global information systems
- The result of data mining is not accurate when the data set is not different
- Some modifications are essential in the business practices for the determination to utilize the uncovered data
- Large databases are required for the data mining process and often it is hard to manage
- Overfitting
- The training database is a small size so it won’t fit the future states in the process
- Data mining queries have to be formulated through the skilled experts
Research Solutions in Data Mining
Predictive analytics is denoted as the collection of statistical techniques that are deployed to analyze the existing and historical data that results in the prediction of future events. In the following, we have enlisted the techniques of predictive analysis.
- Data mining
- Predictive modeling
- Machine learning
Oracle data mining is abbreviated as ODM and it is one of the elements in oracle’s advanced analytics database. It is deployed to provide powerful data mining algorithms which are assistive for the data analyst to acquire the treasured insights in data for the prediction process. In addition, it is used to predict the behavior of the customers and that is used to direct the finest customer and cross-selling. The SQL functions are deployed in the algorithm and that is to excavate the data tables.
Types and Taxonomy of Data Mining
The data mining process is using various techniques to determine the type of mining, pattern detection, data recovery operation, and knowledge discovery. The implementation of the data mining thesis is listed as the process in the following along with its specifications.
- Weighted hierarchical clustering
- Hierarchical clustering
- Logistic regression
- K-Nearest neighbor
- Artificial neural network (ANN)
- Support vector machine (SVM)
- Decision tree
- Naive Bayes
We have successfully delivered several project topics based on data mining with the best quality and novelty. Our research team and developers are highly qualified and are intended uniquely to establish effective research ideas with authenticity. So, the research scholars can enthusiastically contact our research experts anytime on the subject of the doubts and requirements related to data mining. Below, we have stated the significant process of data mining.
Process of Data Mining
The process of data mining is to understand the data via the models such as database systems, machine learning, and statistics, finding patterns, and cleaning the raw data. In the following, we have enlisted the data mining research concepts.
- Data warehousing
- Data Analytics
- Artificial intelligence
- Data preparation and cleansing
We have an in-depth vision in all the areas related to this field. We will make your work stress free through preceding your research in the list of research topics in data mining for PhD. As well as, we made all hard topics easy with our smart work. You can find our keen help for your PhD research. Now, the research scholars can refer to the following research areas based on data mining.
Research Areas in Data Mining
- Market basket analysis
- Intrusion detection
- Future healthcare
Although you can find the above information with ease it is hard to choose and find significant research topics in data mining. Thus, we have listed down a vital list of research topics in data mining for PhD and it is beneficial for the research scholars to develop their recent research.
Research Topics in Data Mining
- Research on data mining of physical examination for risk factors of chronic diseases based on classification decision tree
- Empowerment of digital technology to improve the level of agricultural economic development based on data mining
- A quality evaluation scheme for curriculum in ideological and political education based on data mining
- Massive AI-based cloud environment for smart online education with data mining
- In-depth data mining method of network shared resources based on k means clustering
- Data analysis on the performance of students based on health status using genetic algorithm and clustering algorithms
- A Markov chain model to analyze the entry and stay states of frequent visitors to Taiwan
- Optimization of the average travel time of passengers in the Tehran metro using data mining methods
- Collaborative learning for improving the intellectual skills of dropout students using data mining techniques
- Towards a machine learning and data mining approach to identify customer satisfaction factors on Airbnb
If you require more list of research topics in data mining of PhD to discuss and to shape your research knowledge you can approach our research experts. Above we have discussed the major topics in data mining. Our well-experienced research and development experts have listed down some of the research trends to support the innovative research project using bethe low-mentioned trends. To add information, we assist with your ideas to obtain better results.
Research Trends in Data Mining
- Privacy protection and information security in data mining
- Multi-databases data mining
- Biological data mining
- Visual data mining
- Standardization of data mining query language
- Integration of data mining with database systems, data warehouse systems, and web database systems
- Scalable and interactive data mining methods
- Application exploration
So far, we have discussed the up-to-date enhancements in data mining to select novel research projects. All the above-mentioned trends help to select the most appropriate research topic for the research and we do not skip any of them in the list of research topics in data mining for PhD Here, we have listed some of our innovative methods and approaches based on data mining.
Algorithms in Data Mining
- Locally estimated in scatter plot smoothing
- Logistic and stepwise regression
- Multivariate adaptive regression splines
- Ordinary least squares regression
- Generalized linear models
- Computational learning theory
- Grammar induction
- Meta-learning
- Soft computing
- Dynamic programming
- Sparse dictionary learning
- Inductive in logic programming
- Association rule learning
- Genetic algorithm
- Bayesian networks
- Reinforcement learning
- Deep learning
- FCM, FPCM and SPCM
- Possibility C means the algorithm
- Ordering points to identify clustering structure(OPTICS)
- Farthest first algorithm
- Expectation maximization (EM)
- K-Means clustering
- Cobweb clustering algorithm
- Density-based spatial clustering algorithm
- Deep convolutional networks
- Deep belief networks
- Recurrent neural networks
- Feed forward the artificial neural network
- Learning vector quantization
- Self-organizing map
- Clonal selection algorithm
- Artificial immune recognition system
The following is the list of research protocols that are used in the implementation of data mining research projects. More than that there are several protocols are available in this field, so the research scholars can contact us to grab more data about the data mining protocols.
Notable Protocols for Data Mining
- It is deployed for the homomorphic encryption scheme for the ElGamal encryption
- Privacy, effectiveness, and efficiency degree are the three notable parameters that are deployed in the determination performance of the PPDDM protocol
Thus far we have seen the details about the protocols that are used in data mining projects and their most important uses. For more details on the functions of data mining, the research scholars can take a look at our website. The following is the list of simulation tools that are used in the projects based on data mining.
Simulation Tools in Data Mining
- Oracle data mining
Performance Metrics in Data Mining
Above mentioned are notable parameters based on the performance metrics in the data mining process. Along with that, our experienced research professionals in data mining have highlighted the datasets that are essential for the implementation of data mining-based research projects in the following.
Datasets in Data Mining
- Disease diagnosis and recommended remedy
- Annotated Arabic extremism tweets
We hope you receive a clear interpretation of data mining research projects. In addition, our teams of experts are creating more ideas in data mining for your ease. Therefore, we are willing to assist you to produce an excellent research project topic in data mining for your Ph.D. research within a stipulated period. So, the research scholars can contact us for additional data about the topical list of research topics in data mining for phd.

Opening Hours
- Mon-Sat 09.00 am – 6.30 pm
- Lunch Time 12.30 pm – 01.30 pm
- Break Time 04.00 pm – 04.30 pm
- 18 years service excellence
- 40+ country reach
- 36+ university mou
- 194+ college mou
- 6000+ happy customers
- 100+ employees
- 240+ writers
- 60+ developers
- 45+ researchers
- 540+ Journal tieup
Payment Options

Our Clients

Social Links

- Terms of Use

Opening Time

Closing Time
- We follow Indian time zone


An official website of the United States government
Here’s how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
- Organization
- Operational and Support Components
- Countering Weapons of Mass Destruction Office
Work with CWMD
The Department of Homeland Security (DHS) Countering Weapons of Mass Destruction Office (CWMD) relies on private sector partners to help us discover scientific advancements and technological innovations that solve chemical, biological, radiological, and nuclear (CBRN) monitoring and detection challenges.
CWMD researches, develops, acquires, and deploys CBRN detection and monitoring equipment to support our Federal, State, Local, Tribal, and Territorial (FSLTT) partners. Learn more about our research and development (R&D) mission and discover how you can work with CWMD to make the homeland more secure.
Industry Engagement
CWMD is continuously engaging with academia, commercial industry, and government agencies to identify new and innovative methods and equipment that are available for our national response in combating existing and evolving tactics and technologies to counter CBRN threats.
How CWMD Engages with Industry:
- Hosts industry days and outreach events to conduct program-specific interchanges and supports market research. (See SAM.GOV for announcements)
- Welcomes request for 1-hour CWMD Industry Engagement Program (CIEP) briefings from industry, academic, and other community entities to CWMD. (Contact [email protected] to request an opportunity to brief.)*
- Engages with CWMD consortiums and related organizations. (Contact [email protected] to inform CWMD about an event)
- Collect freely offered whitepapers and/or factsheets to add to our market research catalog. (Submit to [email protected] )
*To ensure a level playing field for all vendors, these CIEP meetings are limited to one hour every six months for each vendor.
Industry, academic, and government partners seeking to meet with CWMD are encouraged to contact: [email protected].
Small Business Innovation Research (SBIR)
The Small Business Innovation Research (SBIR) program is one of the largest public-private partnerships in the United States. The SBIR program encourages small businesses with fewer than 500 employees to provide quality research and develop new processes, products, and technologies in support of the missions of the U.S. government.
DHS Program
The DHS SBIR program is focused on near-term commercialization and delivery of operational prototypes to federal, state, and local law enforcement officers; emergency responders; and other public safety officials. SBIR is a three-phased program:
- Phase I: Determine the scientific and technical merit and feasibility of the proposed effort.
- Phase II: Continue the research and development effort if found feasible.
- Phase III: Work toward the commercialization of SBIR research or technology.
Areas of Emphasis
CWMD supports federal, state, and local law enforcement and other public safety officials to prevent chemical, biological, radiological, and nuclear threats and incidents, as well threats associated with food, agriculture, and veterinarian systems. Through SBIR, CWMD works with small business to identify, explore, develop, and demonstrate new technologies and capabilities that these frontline defenders can use to carry out their mission.
CWMD’s SBIR program currently focuses on these critical challenges:
- Network and algorithm development for system integration and deployment to create an advanced information and communication architecture backbone.
- Development of novel approaches to data analysis in conjunction with detection of anomalies supporting decision-making.
- Improved chemical, biological, radiological, and nuclear detection through lower cost approaches to enable widespread deployment.
- Threat detection and reduction for food, agriculture, and veterinarian systems.
For Additional Information
The SBIR program issues solicitations on U.S. General Services SAM website .
For more information about SBIR, please visit the SBIR website .
If you have questions about CWMD’s SBIR program, please contact [email protected] .
Data Mining, Analysis and Modeling Cell (DMAMC)
Federal, state, local, tribal, and territorial (FSLTT) agencies with preventative chemical, biological, and radiological detection programs may require technical support regarding procurement and deployment of detection systems. The Test and Evaluation Division within the CWMD independently tests and evaluates detection equipment and associated systems, and has archived reports, test plans, data sets, and models from more than 150 tests that it has conducted. DMAMC brings together subject matter experts from the CWMD community with the processes and tools necessary to maintain and analyze test data. The data can then be used to respond to technical questions from stakeholders and support future testing activities.
DMAMC Analyzes Test Data
DMAMC provides timely responses to test data inquiries. It has organized existing test data for ease of retrieval, developed an efficient analysis process, implemented standardized data collection for all test activities, and incorporated modeling as a method to address detector performance and use questions. DMAMC comprises a team of subject matter experts with test planning and execution, modeling, analysis, systems engineering, and acquisition experience. Experts from CWMD, the U.S. Department of Energy national laboratories, universities, and non-profit research organizations work on the DMAMC team. They provide technical assistance to stakeholders through the analysis of existing test data generated and archived during the execution of all previous CWMD test campaigns. The DMAMC subject matter experts mine and analyze historical data, then create a customized response to a stakeholder request.
DMAMC's Capabilities
- Access to archived test reports and data.
- Technical comparison of data from across tests, with context from independent analyses.
- Evaluation of detector response based on operational use of instruments.
- Customized analysis and simulation in response to stakeholder technical questions.
- Recommendations of test protocols and practices based on lessons learned.
- Independent third-party review of technical reports or vendor documentation.
- Recommendations on test design and protocols based on instrument data and modeling.
Contact CWMD DMAMC by emailing [email protected] .
Notices of Funding Opportunities (NOFO)
The Grants.gov program management office was established, in 2002, as a part of the President's Management Agenda. Managed by the Department of Health and Human Services, Grants.gov is an E-Government initiative operating under the governance of the Office of Management and Budget.
Under the President's Management Agenda, the office was chartered to deliver a system that provides a centralized location for grant seekers to find and apply for federal funding opportunities. When an agency plans and develops a funding program, they publish a Notice of Funding Opportunity (NOFO) to advertise it to applicant communities and to invite proposals tailored to address the program mission. The grant-making agency will publish details of the funding opportunity on Grants.gov. CWMD participates in this program and has the following NOFO's available:
| Funding Opportunity Number | Funding Opportunity Title | Description |
|---|---|---|
| Fiscal Year 2024 Nuclear Forensics Research Award (NFRA) | The Nuclear Forensics Research Award (NFRA) is designed to develop future technical experts and leaders by funding nuclear forensics related research proposals which establish links among universities, faculty, graduate, and undergraduate students, the Nuclear Forensics Interagency, and staff at the national and defense laboratories. |
For more information on a specific NOFO, please click the link in the table to go to the Grants.gov website.
- Weapons of Mass Destruction
- Countering Weapons of Mass Destruction (CWMD)
- Grant Funding

Videos, Software, Training, etc. Data & Statistics MSHA Data Files NIOSH Mining en Español
Mining Safety and Health Topics News & Articles Mining Links Publications
Projects Contracts Strategic Plan Funding Opportunities
About Us Contact NIOSH Mining Employment Visitor Information Technology Innovations Awards Partnerships
- Workplace Safety & Health Topics
- Publications and Products
Exit Notification / Disclaimer Policy
- The Centers for Disease Control and Prevention (CDC) cannot attest to the accuracy of a non-federal website.
- Linking to a non-federal website does not constitute an endorsement by CDC or any of its employees of the sponsors or the information and products presented on the website.
- You will be subject to the destination website's privacy policy when you follow the link.
- CDC is not responsible for Section 508 compliance (accessibility) on other federal or private website.
- DOI: 10.3390/land13060843
- Corpus ID: 270530830
Deciphering Tourism’s Role in Antarctica’s Geosocial Concerns through Data Mining Techniques
- Víctor Calderón-Fajardo , Miguel Puig-Cabrera , Ignacio Rodríguez-Rodríguez
- Published in Land 13 June 2024
- Environmental Science, Geography
65 References
Understanding tourism consumer behavior using biometric technologies: bibliographic review and research agenda, travel satisfaction and travel well-being: which is more related to travel choice behaviour in the post covid-19 pandemic evidence from public transport travellers in xi’an, china, scoping out urban areas of tourist interest though geolocated social media data: bucharest as a case study, the future of tourism in the anthropocene, how environmental emotions link to responsible consumption behavior: tourism agenda 2030, connection to nature and time spent in gardens predicts social cohesion, analysis of the twitter discourse on sustainability using natural language processing, tourists’ motivations, learning, and trip satisfaction facilitate pro-environmental outcomes of the antarctic tourist experience, community eco-tourism in rural peru: resilience and adaptive capacities to the covid-19 pandemic and climate change, determinants of tourists’ site-specific environmentally responsible behavior: an eco-sensitive zone perspective, related papers.
Showing 1 through 3 of 0 Related Papers
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
Winter wheat aboveground-biomass estimation and its dynamic variation during coal mining—assessing by unmanned aerial vehicle-based remote sensing.

Share and Cite
Lyu, X.; Zhang, H.; Chen, Z.; Jiao, Y.; Du, W.; Zhang, X.; Luo, J.; Zhang, E. Winter Wheat Aboveground-Biomass Estimation and Its Dynamic Variation during Coal Mining—Assessing by Unmanned Aerial Vehicle-Based Remote Sensing. Agronomy 2024 , 14 , 1330. https://doi.org/10.3390/agronomy14061330
Lyu X, Zhang H, Chen Z, Jiao Y, Du W, Zhang X, Luo J, Zhang E. Winter Wheat Aboveground-Biomass Estimation and Its Dynamic Variation during Coal Mining—Assessing by Unmanned Aerial Vehicle-Based Remote Sensing. Agronomy . 2024; 14(6):1330. https://doi.org/10.3390/agronomy14061330
Lyu, Xiaoxuan, Hebing Zhang, Zhichao Chen, Yiheng Jiao, Weibing Du, Xufei Zhang, Jialiang Luo, and Erwei Zhang. 2024. "Winter Wheat Aboveground-Biomass Estimation and Its Dynamic Variation during Coal Mining—Assessing by Unmanned Aerial Vehicle-Based Remote Sensing" Agronomy 14, no. 6: 1330. https://doi.org/10.3390/agronomy14061330
Article Metrics
Article access statistics, further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
IMAGES
VIDEO
COMMENTS
Commercial Uses of Data Mining. Data mining process entails the use of large relational database to identify the correlation that exists in a given data. The principal role of the applications is to sift the data to identify correlations. A Discussion on the Acceptability of Data Mining.
Find the latest published documents for data mining, Related hot topics, top authors, the most cited documents, and related journals. ScienceGate; Advanced Search; Author Search; Journal Finder; Blog; ... This research is aimed to detect the user's topics of interest in social media and rank them based on specific topics, domains, etc. Few ...
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on DATA MINING. Find methods information, sources, references or conduct a literature review on DATA MINING
Data mining is the process of extracting potentially useful information from data sets. It uses a suite of methods to organise, examine and combine large data sets, including machine learning ...
Data mining is the procedure of identifying valid, potentially suitable, and understandable information; detecting patterns; building knowledge graphs; and finding anomalies and relationships in big data with Artificial-Intelligence-enabled IoT (AIoT). This process is essential for advancing knowledge in various fields dealing with raw data ...
Identifying and overcoming COVID-19 vaccination impediments using Bayesian data mining techniques. Bowen Lei. , Arvind Mahajan. & Bani Mallick. Article. 10 April 2024 | Open Access.
Data mining research has been significantly motivated by and benefited from real-world applications in novel domains. This special issue was proposed and edited to draw attention to domain-driven data mining and disseminate research in foundations, frameworks, and applications for data-driven and actionable knowledge discovery. Along with this special issue, we also organized a related ...
The goal of this research topic is to bring together theories and applications of efficient deep learning techniques to big-data mining problems. The proposed research theme will focus on efficient deep learning techniques for big data mining. The topics of interest include but are not limited to the following areas: • Neural Network Pruning.
Address: 20, Myasnitskaya Street, Moscow 101000, Russia. Abstract. This work analyzes the intellectual structure of data mining as a scientific discipline. T o do this, we use. topic analysis ...
AI-driven data mining explores algorithms and techniques that can handle numerous data and extract useful pattern information with little human intervention. This Special Issue seeks new ideas, methods and achievements for the intersection between artificial intelligence and data mining. Topics of interest include, but are not limited to, the ...
The analysis showed that attention to topics such as Pattern Mining and Segmentation is decreasing and the popularity of research related to Recommender Systems, Network Analysis, and Human Behaviour Analysis is growing, which is likely due to the increasing availability of data and the practical value of these topics.
Integration of MapReduce, Amazon EC2, S3, Apache Spark, and Hadoop into data mining. These are the recent trends in data mining. We insist that you choose one of the topics that interest you the most. Having an appropriate content structure or template is essential while writing a thesis.
Data mining is defined as the process of discovering hidden and potentially useful information from very large databases [4].The progress in data mining research has made it possible to implement several data mining operations efficiently on large databases. While this is surely an important contribution, we should not lose sight of the final goal of data mining - it is to enable database ...
John S Kimball. Nitesh V Chawla. Murat Kantarcioglu. Elena Ferrari. Dongwon Lee. Jean-Roch Vlimant. 19,637 views. 4 articles. Part of an innovative multidisciplinary journal, exploring a wide range of topics, such as intelligent data management, information retrieval, privacy-preserving data mining, and data visual analyt...
Educational data mining is used to discover significant phenomena and resolve educational issues occurring in the context of teaching and learning. This study provides a systematic literature review of educational data mining in mathematics and science education. A total of 64 articles were reviewed in terms of the research topics and data mining techniques used. This review revealed that data ...
Top Challenges in Data Mining Research. 1 Muthu Dayalan. 1 Senior Software Developer & Researcher. 1 Chennai & TamilNadu. Abstract — Data mining as a new phenomenon in. business and ...
Research Topics on Data Mining Research Topics on Data Mining offer you creative ideas to prime your future brightly in research. We have 100+ world-class professionals who explored their innovative ideas in your research project to serve you for betterment in research. So We have conducted 500+ workshops throughout the world, and a large ...
The main research objective of this article is to study how data mining methodologies are applied by researchers and practitioners. To this end, we use systematic literature review (SLR) as scientific method for two reasons. Firstly, systematic review is based on trustworthy, rigorous, and auditable methodology.
Applying data mining to telecom churn management. A data mining approach to the prediction of corporate failure. Algorithms and applications for spatial data mining. Mining educational data to analyze students' performance. An attacker's view of distance preserving maps for privacy preserving data mining.
The research on clinical data, theory and medical literature data mining has shifted from only classifying data through clustering analysis, data mining association rules analysis, regression analysis, to a new stage of TCM when machine learning algorithms, such as feature extraction, similarity calculation and semantic fusion, are widely used ...
The Artificial Intelligence and Machine Learning and Data Mining research community expands the state of the art at these, the field's most prestigious and selective conferences: ... Research Topics: Graph mining; social network analysis; network science; temporal network analysis; combinatorial scientific computing; stream processing; ...
Topics to study in data mining. Data mining is a relatively new thing and many are not aware of this technology. This can also be a good topic for M.Tech thesis and for presentations. Following are the topics under data mining to study: Fraud Detection. Crime Rate Prediction.
The process of data mining is to understand the data via the models such as database systems, machine learning, and statistics, finding patterns, and cleaning the raw data. In the following, we have enlisted the data mining research concepts. Regression. Machine learning. Data warehousing.
The Small Business Innovation Research (SBIR) program is one of the largest public-private partnerships in the United States. The SBIR program encourages small businesses with fewer than 500 employees to provide quality research and develop new processes, products, and technologies in support of the missions of the U.S. government.
Use EXAMiner to practice and teach hazard recognition skills for mining operations in any sector. Browse the Mining site by subject. Tools You Can Use. Videos, Software, Training, etc. Data & Statistics MSHA Data Files NIOSH Mining en Español. Information Resources. Mining Safety and Health Topics News & Articles
Through text mining, topic modelling, sentiment analysis, and Natural Language Processing (NLP), it investigates the emotional and perceptual discourse surrounding Antarctic tourism and its alignment with Agenda 2030 and Sustainable Development Goals. ... Social media data has frequently sourced research on topics such as traveller planning or ...
Underground coal mining in coal-grain overlapped areas leads to land subsidence and deformation above the goaf, damaging cultivated land. Understanding the influencing process of coal mining on cultivated land and crops is important for carrying out timely land reclamation and stabilizing crop yield. Research has been carried out by using crop growth parameters to evaluate the damaging degree ...