Responsibility & Safety

How can we build human values into AI?
Iason Gabriel and Kevin McKee
- Copy link ×

Drawing from philosophy to identify fair principles for ethical AI
As artificial intelligence (AI) becomes more powerful and more deeply integrated into our lives, the questions of how it is used and deployed are all the more important. What values guide AI? Whose values are they? And how are they selected?
These questions shed light on the role played by principles – the foundational values that drive decisions big and small in AI. For humans, principles help shape the way we live our lives and our sense of right and wrong. For AI, they shape its approach to a range of decisions involving trade-offs, such as the choice between prioritising productivity or helping those most in need.
In a paper published today in the Proceedings of the National Academy of Sciences , we draw inspiration from philosophy to find ways to better identify principles to guide AI behaviour. Specifically, we explore how a concept known as the “veil of ignorance” – a thought experiment intended to help identify fair principles for group decisions – can be applied to AI.
In our experiments, we found that this approach encouraged people to make decisions based on what they thought was fair, whether or not it benefited them directly. We also discovered that participants were more likely to select an AI that helped those who were most disadvantaged when they reasoned behind the veil of ignorance. These insights could help researchers and policymakers select principles for an AI assistant in a way that is fair to all parties.

The veil of ignorance (right) is a method of finding consensus on a decision when there are diverse opinions in a group (left).
A tool for fairer decision-making
A key goal for AI researchers has been to align AI systems with human values. However, there is no consensus on a single set of human values or preferences to govern AI – we live in a world where people have diverse backgrounds, resources and beliefs. How should we select principles for this technology, given such diverse opinions?
While this challenge emerged for AI over the past decade, the broad question of how to make fair decisions has a long philosophical lineage. In the 1970s, political philosopher John Rawls proposed the concept of the veil of ignorance as a solution to this problem. Rawls argued that when people select principles of justice for a society, they should imagine that they are doing so without knowledge of their own particular position in that society, including, for example, their social status or level of wealth. Without this information, people can’t make decisions in a self-interested way, and should instead choose principles that are fair to everyone involved.
As an example, think about asking a friend to cut the cake at your birthday party. One way of ensuring that the slice sizes are fairly proportioned is not to tell them which slice will be theirs. This approach of withholding information is seemingly simple, but has wide applications across fields from psychology and politics to help people to reflect on their decisions from a less self-interested perspective. It has been used as a method to reach group agreement on contentious issues, ranging from sentencing to taxation.
Building on this foundation, previous DeepMind research proposed that the impartial nature of the veil of ignorance may help promote fairness in the process of aligning AI systems with human values. We designed a series of experiments to test the effects of the veil of ignorance on the principles that people choose to guide an AI system.
Maximise productivity or help the most disadvantaged?
In an online ‘harvesting game’, we asked participants to play a group game with three computer players, where each player’s goal was to gather wood by harvesting trees in separate territories. In each group, some players were lucky, and were assigned to an advantaged position: trees densely populated their field, allowing them to efficiently gather wood. Other group members were disadvantaged: their fields were sparse, requiring more effort to collect trees.
Each group was assisted by a single AI system that could spend time helping individual group members harvest trees. We asked participants to choose between two principles to guide the AI assistant’s behaviour. Under the “maximising principle” the AI assistant would aim to increase the harvest yield of the group by focusing predominantly on the denser fields. While under the “prioritising principle”the AI assistant would focus on helping disadvantaged group members.

An illustration of the ‘harvesting game’ where players (shown in red) either occupy a dense field that is easier to harvest (top two quadrants) or a sparse field that requires more effort to collect trees.
We placed half of the participants behind the veil of ignorance: they faced the choice between different ethical principles without knowing which field would be theirs – so they didn’t know how advantaged or disadvantaged they were. The remaining participants made the choice knowing whether they were better or worse off.
Encouraging fairness in decision making
We found that if participants did not know their position, they consistently preferred the prioritising principle, where the AI assistant helped the disadvantaged group members. This pattern emerged consistently across all five different variations of the game, and crossed social and political boundaries: participants showed this tendency to choose the prioritising principle regardless of their appetite for risk or their political orientation. In contrast, participants who knew their own position were more likely to choose whichever principle benefitted them the most, whether that was the prioritising principle or the maximising principle.

A chart showing the effect of the veil of ignorance on the likelihood of choosing the prioritising principle, where the AI assistant would help those worse off. Participants who did not know their position were much more likely to support this principle to govern AI behaviour.
When we asked participants why they made their choice, those who did not know their position were especially likely to voice concerns about fairness. They frequently explained that it was right for the AI system to focus on helping people who were worse off in the group. In contrast, participants who knew their position much more frequently discussed their choice in terms of personal benefits.
Lastly, after the harvesting game was over, we posed a hypothetical situation to participants: if they were to play the game again, this time knowing that they would be in a different field, would they choose the same principle as they did the first time? We were especially interested in individuals who previously benefited directly from their choice, but who would not benefit from the same choice in a new game.
We found that people who had previously made choices without knowing their position were more likely to continue to endorse their principle – even when they knew it would no longer favour them in their new field. This provides additional evidence that the veil of ignorance encourages fairness in participants’ decision making, leading them to principles that they were willing to stand by even when they no longer benefitted from them directly.
Fairer principles for AI
AI technology is already having a profound effect on our lives. The principles that govern AI shape its impact and how these potential benefits will be distributed.
Our research looked at a case where the effects of different principles were relatively clear. This will not always be the case: AI is deployed across a range of domains which often rely upon a large number of rules to guide them , potentially with complex side effects. Nonetheless, the veil of ignorance can still potentially inform principle selection, helping to ensure that the rules we choose are fair to all parties.
To ensure we build AI systems that benefit everyone, we need extensive research with a wide range of inputs, approaches, and feedback from across disciplines and society. The veil of ignorance may provide a starting point for the selection of principles with which to align AI. It has been effectively deployed in other domains to bring out more impartial preferences . We hope that with further investigation and attention to context, it may help serve the same role for AI systems being built and deployed across society today and in the future.
Read more about DeepMind’s approach to safety and ethics .
- Join our email list
- Add to Calendar

Whitney Humanities Center
What we see and what we value: ai with a human perspective.
2022 Tanner Lecture on Artificial Intelligence and Human Values
Fei-Fei Li of Stanford University will deliver the 2022 Tanner Lecture on Human Values and Artificial Intelligence this fall at the Whitney Humanities Center. The lecture, “What We See and What We Value: AI with a Human Perspective,” presents a series of AI projects—from work on ambient intelligence in healthcare to household robots—to examine the relationship between visual and artificial intelligence. Visual intelligence has been a cornerstone of animal intelligence; enabling machines to see is hence a critical step toward building intelligent machines. Yet developing algorithms that allow computers to see what humans see—and what they don’t see—raises important social and ethical questions.
Dr. Fei-Fei Li is the Sequoia Professor of Computer Science at Stanford University and Denning Co-Director of the Stanford Institute for Human-Centered AI (HAI). During her 2017–2018 sabbatical, Dr. Li was a vice president at Google and chief scientist of Artificial Intelligence/Machine Learning at Google Cloud. She co-founded the national nonprofit AI4ALL, which trains K-12 students from underprivileged communities to become future leaders in AI. Dr. Li also serves on the National AI Research Resource Task Force commissioned by Congress and the White House and is an elected member of the National Academy of Engineering, the National Academy of Medicine, and the American Academy of Arts and Sciences.
Dr. Fei-Fei Li’s talk is one of seven Tanner Lectures on Artificial Intelligence and Human Values, which is a special series of the Tanner Lectures on Human Values. The Tanner Lectures on Human Values are funded by an endowment received by the University of Utah from Obert Clark Tanner and Grace Adams Tanner. Established in 1976, the Tanner Lectures seek to advance and reflect upon scholarly and scientific learning relating to human values. The lectures, which are permanently sponsored at nine institutions, including Yale, are free and open to the public.
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
AI Should Augment Human Intelligence, Not Replace It
- David De Cremer
- Garry Kasparov

Artificial intelligence isn’t coming for your job, but it will be your new coworker. Here’s how to get along.
Will smart machines really replace human workers? Probably not. People and AI both bring different abilities and strengths to the table. The real question is: how can human intelligence work with artificial intelligence to produce augmented intelligence. Chess Grandmaster Garry Kasparov offers some unique insight here. After losing to IBM’s Deep Blue, he began to experiment how a computer helper changed players’ competitive advantage in high-level chess games. What he discovered was that having the best players and the best program was less a predictor of success than having a really good process. Put simply, “Weak human + machine + better process was superior to a strong computer alone and, more remarkably, superior to a strong human + machine + inferior process.” As leaders look at how to incorporate AI into their organizations, they’ll have to manage expectations as AI is introduced, invest in bringing teams together and perfecting processes, and refine their own leadership abilities.
In an economy where data is changing how companies create value — and compete — experts predict that using artificial intelligence (AI) at a larger scale will add as much as $15.7 trillion to the global economy by 2030 . As AI is changing how companies work, many believe that who does this work will change, too — and that organizations will begin to replace human employees with intelligent machines . This is already happening: intelligent systems are displacing humans in manufacturing, service delivery, recruitment, and the financial industry, consequently moving human workers towards lower-paid jobs or making them unemployed. This trend has led some to conclude that in 2040 our workforce may be totally unrecognizable .
- David De Cremer is a professor of management and technology at Northeastern University and the Dunton Family Dean of its D’Amore-McKim School of Business. His website is daviddecremer.com .
- Garry Kasparov is the chairman of the Human Rights Foundation and founder of the Renew Democracy Initiative. He writes and speaks frequently on politics, decision-making, and human-machine collaboration. Kasparov became the youngest world chess champion in history at 22 in 1985 and retained the top rating in the world for 20 years. His famous matches against the IBM super-computer Deep Blue in 1996 and 1997 were key to bringing artificial intelligence, and chess, into the mainstream. His latest book on artificial intelligence and the future of human-plus-machine is Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins (2017).
Partner Center
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 23 February 2022
Human autonomy in the age of artificial intelligence
- Carina Prunkl ORCID: orcid.org/0000-0002-0123-9561 1
Nature Machine Intelligence volume 4 , pages 99–101 ( 2022 ) Cite this article
1867 Accesses
18 Citations
23 Altmetric
Metrics details
- Science, technology and society
Current AI policy recommendations differ on what the risks to human autonomy are. To systematically address risks to autonomy, we need to confront the complexity of the concept itself and adapt governance solutions accordingly.
This is a preview of subscription content, access via your institution
Relevant articles
Open Access articles citing this article.
Human Autonomy at Risk? An Analysis of the Challenges from AI
- Carina Prunkl
Minds and Machines Open Access 24 June 2024
Rethinking Health Recommender Systems for Active Aging: An Autonomy-Based Ethical Analysis
- Simona Tiribelli
- & Davide Calvaresi
Science and Engineering Ethics Open Access 27 May 2024
Artificial intelligence and human autonomy: the case of driving automation
- Fabio Fossa
AI & SOCIETY Open Access 16 May 2024
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
111,21 € per year
only 9,27 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Raz, J. The Morality of Freedom (Clarendon Press, 1986).
Korsgaard, C. M., Cohen, G. A., Geuss, R., Nagel, T. Williams, T. & O’Neilk, O. The Sources of Normativity (Cambridge Univ. Press, 1996).
Christman, J. in The Stanford Encyclopedia of Philosophy (ed. Zalta, E. N.) (Metaphysics Research Lab, Stanford Univ., 2020); https://plato.stanford.edu/entries/autonomy-moral/
Roessler, B. Autonomy: An Essay on the Life Well-Lived (John Wiley, 2021).
Susser, D., Roessler, B. & Nissenbaum, H. Technology, Autonomy, and Manipulation (Technical Report) (Social Science Research Network, Rochester, NY, 2019).
Kramer, A. D. I., Guillory, J. E. & Hancock, J. T. Proc. Natl Acad. Sci. USA 111 , 8788–8790 (2014).
Article Google Scholar
European Commission High-Level Experts Group (HLEG). Ethics Guidelines for Trustworthy AI (Technical Report B-1049) (EC, Brussels, 2019).
Association for Computing Machinery (ACM). ACM Code of Ethics and Professional Conduct (ACM, 2018).
Université de Montréal. Montreal Declaration for a Responsible Development of AI (Forum on the Socially Responsible Development of AI (Université de Montréal, 2017).
European Committee of the Regions. White Paper on Artificial Intelligence - A European approach to excellence and trust (EC, 2020).
Organisation for Economic Co-operation and Development. Recommendation of the Council on Artificial Intelligence (Technical Report OECD/LEGAL/0449) (OECD 2019); https://oecd.ai/en/ai-principles
European Commission, Directorate-General for Research and Innovation, European Group on Ethics in Science and New Technologies. Statement on artificial intelligence, robotics and ‘autonomous’ systems (EC, 2018).
Floridi, L. & Cowls, J. Harvard Data Sci. Rev 1 , 1–13 (2019).
Google Scholar
Fjeld, J., Achten, N., Hilligoss, H., Nagy, A. & Srikumar, M. Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-Based Approaches to Principles for AI (SSRN Scholarly Paper ID 3518482) (Social Science Research Network, Rochester, NY, 2020); https://papers.ssrn.com/abstract=3518482
Milano, S., Taddeo, M. & Floridi, L. Recommender Systems and their Ethical Challenges (SSRN Scholarly Paper ID 3378581) (Social Science Research Network, Rochester, NY, 2019).
Calvo, R. A., Peters, D. & D’Mello, S. Commun. ACM 58 , 41–42 (2015).
Mik, E. Law Innov. Technol. 8 , 1–38 (2016).
Helberger, N. Profiling and Targeting Consumers in the Internet of Things – A New Challenge for Consumer Law (Technical Report) (Social Science Research Network, Rochester, NY, 2016).
Burr, C., Morley, J., Taddeo, M. & Floridi, L. IEEE Trans. Technol. Soc. 1 , 21–33 (2020).
Morley, J. & Floridi, L. Sci. Eng. Ethics 26 , 1159–1183 (2020).
Brownsword, R. in Law, Human Agency and Autonomic Computing (eds Hildebrandt., M. & Rouvroy, A.) 80–100 (Routledge, 2011).
Calvo, R., Peters, D., Vold, K. V. & Ryan, R. in Ethics of Digital Well-Being (Philosophical Studies Series, vol. 140) (eds Burr, C. & Floridi, L.) 31–54 (Springer, 2020).
Rubel, A., Castro, C. & Pham, A. Algorithms and Autonomy: The Ethics of Automated Decision Systems (Cambridge Univ. Press, 2021).
Dworkin, G. The Theory and Practice of Autonomy (Cambridge Univ. Press. 1988).
Mackenzie, C. Three Dimensions of Autonomy: A Relational Analysis (Oxford Univ. Press, 2014).
Noggle, R. Am. Philos. Q. 33 , 43–55 (1996).
Elster, J. Sour Grapes: Studies in the Subversion of Rationality (Cambridge Univ. Press, 1985).
Adomavicius, G., Bockstedt, J. C., Curley, S. P. & Zhang, J. Info. Syst. Res 24 , 956–975 (2013).
Ledford, H. Nature 574 , 608–609 (2019).
Dworkin, G. in The Stanford Encyclopedia of Philosophy (ed. Zalta, E. N.) (Metaphysics Research Lab, Stanford Univ. Press, 2020; https://plato.stanford.edu/archives/fall2020/entries/paternalism/
Kühler, M. Bioethics 36 , 194–200 (2021).
Christman, J. The Politics of Persons: Individual Autonomy and Socio-Historical Selves (Cambridge Univ. Press, 2009.)
Download references
Acknowledgements
The author thanks J. Tasioulas, M. Philipps-Brown, C. Veliz, T. Lechterman, A. Dafoe and B. Garfinkel for their helpful comments. Funding: No external funding sources.
Author information
Authors and affiliations.
Institute for Ethics in AI, University of Oxford, Oxford, UK
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Carina Prunkl .
Ethics declarations
Competing interests.
The author declares no competing interests.
Peer review
Peer review information.
Nature Machine Intelligence thanks the anonymous reviewers for their contribution to the peer review of this work.
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Prunkl, C. Human autonomy in the age of artificial intelligence. Nat Mach Intell 4 , 99–101 (2022). https://doi.org/10.1038/s42256-022-00449-9
Download citation
Published : 23 February 2022
Issue Date : February 2022
DOI : https://doi.org/10.1038/s42256-022-00449-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
AI & SOCIETY (2024)
- Davide Calvaresi
Science and Engineering Ethics (2024)
Minds and Machines (2024)
A principles-based ethics assurance argument pattern for AI and autonomous systems
- Ibrahim Habli
- Marten Kaas
AI and Ethics (2024)
Assessing deep learning: a work program for the humanities in the age of artificial intelligence
- Jan Segessenmann
- Thilo Stadelmann
- Oliver Dürr
AI and Ethics (2023)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.


Artificial Intelligence and Democratic Values

Press Release
FOR RELEASE
Monday, 21 February 2022
09.00 EST / 15.00 CET
Updated Index Ranks AI Policies and Practices in 50 Countries
Canada, Germany, Italy, and Korea Rank at Top,
US Makes Progress as Concerns about China Remain
AI POLICY HIGHLIGHTS -2021
- UNESCO AI Recommendation banned social scoring and mass surveillance
- EU Introduced comprehensive, risk-based framework
- Council of Europe makes progress on AI convention
- Continued progress on implementation of OECD Principles, first AI policy framework
- G7 leaders endorsed algorithmic transparency to combat AI bias
- US opens-up policy process, embraces “democratic values”
- EU and US move toward alignment on AI policy
- AI regulation in China leaves open questions about independent oversight
- UN fails to reach agreement on lethal autonomous weapons
- Growing global battle over deployment of facial recognition looms ahead
[ PRESS RELEASE ]
In 2020, the Center for AI and Digital Policy published the first worldwide assessment of AI policies and practices. Artificial Intelligence and Democratic Values rated and ranked 30 countries, based on a rigorous methodology and 12 metrics established to assess alignment with democratic values.
The 2021 Report expands the global coverage from 30 countries to 50 countries, acknowledges the significance of the UNESCO Recommendation on AI ethics, and reviews earlier country ratings. The 2021 report is the result of the work of more than 100 AI policy experts in almost 40 countries.

AI Index - Country Ratings

CAIDP AI Index - Score on Metrics
Panel Discussion

Panel discussion with Merve Hickok, Marc Rotenberg, Fanny Hidvegi, Karine Caunes, Eduardo Bertoni, Jibu Elias, Stuart Russell, and Vice President of the European Parliament Eva Kaili. CAIDP, 21 Feb. 21 2022.
- Video of panel discussion
- Audio of panel discussion
- Comments on panel discussion
- Panel discussion report (by Afi Blackshear)

Report release -
ARTIFICIAL INTELLIGENCE AND DEMOCRATIC VALUES INDEX
Monday, 21 February 2022
10.00 EST / 16.00 CET to 11.00 EST / 17.00 CET
- Karine Caunes , CAIDP Global Program Director
Keynote Remarks
- Eva Kaili, Vice President European Parliament
Report Presentation
- Merve Hickok , CAIDP Research Director
- Professor Eduardo Bertoni, Inter American Institute of Human Rights
- Jibu Elias , National AI Portal of India
- Fanny Hidvegi , Access Now, European Policy Manager
- Professor Stuart Russell, University of California Berkeley
Closing Remarks
- Marc Rotenberg, CAIDP President
[ Register ]
AI Index - 2021 v. 2020
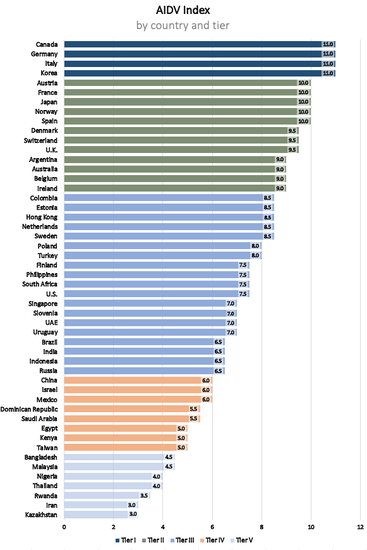
CAIDP AI Index - Country Ratings by Tier

CAIDP AI Index - Country Ratings 2021 v. 2020

ARTIFICIAL INTELLIGENCE AND DEMOCRATIC VALUES - 2021 (CAIPD 2022)
[ PDF Format ]
[ EPUB Format ]

Endorsements

News Reports

The Korea Herald, S. Korea joins top-tier group in democratic AI policy index (Feb. 23, 2022)

AI Decoded (Feb. 23, 2022)

Digital Bridge (Feb. 25, 2022)

Send revisions and updates to [email protected]
- Scroll to top
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Challenges of Aligning Artificial Intelligence with Human Values

2000, Challenges of Aligning AI with Human Values
As artificial intelligence (AI) systems are becoming increasingly autonomous and will soon be able to make decisions on their own about what to do, AI researchers have started to talk about the need to align AI with human values. The AI 'value alignment problem' faces two kinds of challenges-a technical and a normative one-which are interrelated. The technical challenge deals with the question of how to encode human values in artificial intelligence. The normative challenge is associated with two questions: "Which values or whose values should artificial intelligence align with?" My concern is that AI developers underestimate the difficulty of answering the normative question. They hope that we can easily identify the purposes we really desire and that they can focus on the design of those objectives. But how are we to decide which objectives or values to induce in AI, given that there is a plurality of values and moral principles and that our everyday life is full of moral disagreements? In my paper I will show that although it is not realistic to reach an agreement on what we, humans, really want as people value different things and seek different ends, it may be possible to agree on what we do not want to happen, considering the possibility that intelligence, equal to our own, or even exceeding it, can be created. I will argue for pluralism (and not for relativism!) which is compatible with objectivism. In spite of the fact that there is no uniquely best solution to every moral problem, it is still possible to identify which answers are wrong. And this is where we should begin the value alignment of AI.
Related Papers
Minds and Machines
Iason Gabriel
This paper looks at philosophical questions that arise in the context of AI alignment. It defends three propositions. First, normative and technical aspects of the AI alignment problem are interrelated, creating space for productive engagement between people working in both domains. Second, it is important to be clear about the goal of alignment. There are significant differences between AI that aligns with instructions, intentions, revealed preferences, ideal preferences, interests and values. A principle-based approach to AI alignment, which combines these elements in a systematic way, has considerable advantages in this context. Third, the central challenge for theorists is not to identify 'true' moral principles for AI; rather, it is to identify fair principles for alignment, that receive reflective endorsement despite widespread variation in people's moral beliefs. The final part of the paper explores three ways in which fair principles for AI alignment could potentially be identified.
AI & society
Eric-Oluf Svee
European Conference on Information Systems
TalTech Journal of European Studies
Peeter Müürsepp
The problem of value alignment in the context of AI studies is becoming more and more acute. This article deals with the basic questions concerning the system of human values corresponding to what we would like digital minds to be capable of. It has been suggested that as long as humans cannot agree on a universal system of values in the positive sense, we might be able to agree on what has to be avoided. The article argues that while we may follow this suggestion, we still need to keep the positive approach in focus as well. A holistic solution to the value alignment problem is not in sight and there might possibly never be a final solution. Currently, we are facing an era of endless adjustment of digital minds to biological ones. The biggest challenge is to keep humans in control of this adjustment. Here the responsibility lies with the humans. Human minds might not be able to fix the capacity of digital minds. The philosophical analysis shows that the key concept when dealing wit...
Stephen Forshaw
Artificial Intelligence (AI) has seen a massive and rapid development in the past twenty years. With such accelerating advances, concerns around the undesirable and unpredictable impact that AI may have on society are mounting. In response to such concerns, leading AI thinkers and practitioners have drafted a set of principles the Asilomar AI Principles for Beneficial AI, one that would benefit humanity instead of causing it harm. Underpinning these principles is the perceived importance for AI to be aligned to human values and promote the ‘common good’. We argue that efforts from leading AI thinkers must be supported by constructive critique, dialogue and informed scrutiny from different constituencies asking questions such as: what and whose values? What does ‘common good’ mean, and to whom? The aim of this workshop is to take a deep dive into human values, examine how they work, and what structures they may exhibit. Specifically, our twofold objective is to capture the diversity ...
ResearchGate
Artificial Intelligence (AI) has witnessed remarkable advancements in recent years, transforming industries and revolutionizing human experiences. While AI presents vast opportunities for positive change, there are inherent risks if its development does not align with human values and societal needs. This research article delves into the ethical dimensions of AI and explores strategies to ensure AI technology serves humanity responsibly. Through a comprehensive literature review, stakeholder interviews, and surveys, we investigate the current state of AI development, ethical challenges, and potential frameworks for promoting alignment with human values. The findings underscore the importance of proactive measures in shaping AI's impact on society, leading to policy recommendations and guidelines for a future in which AI technology benefits humanity while upholding its core values.
Artificial Intelligence, A Protocol for Setting Moral and Ethical Operational Standars
Daniel Raphael, PhD
This paper (39.39) cuts through the ethics-predicament that is now raging in the Artificial Intelligence industry. Historically, ethics consulting has pointed to “ethical principles” as underlying ethical decision-making. The conundrum in that position is that it cannot point to a set of values that underlie decision-making to express those principles. The fundamental truth is that values always underlie all decision-making. AI’s predicament is resolved in this paper by clearly describing the values that have sustained the survival of the Homo sapiens species for over 200,000 years. The proof of their effectiveness is evident in our own personal lives now. The exciting aspect of these values erupts in the logic-sequences that develop out of those values and their characteristics. When the seven values are combined with their characteristics, their logic-sequences are quickly expressed in a timeless and universally applicable logic and morality, whether applied to the decision-making of individuals, organizations, or AI programs. This paper provides a rational and logical presentation of those values, decision-making, ethics, morality, the primary cause of human motivation. [40 pages, 10k words — enjoy!]
Journal of Artificial Intelligence Research
Tae Wan Kim
An important step in the development of value alignment (VA) systems in artificial intelligence (AI) is understanding how VA can reflect valid ethical principles. We propose that designers of VA systems incorporate ethics by utilizing a hybrid approach in which both ethical reasoning and empirical observation play a role. This, we argue, avoids committing “naturalistic fallacy,” which is an attempt to derive “ought” from “is,” and it provides a more adequate form of ethical reasoning when the fallacy is not committed. Using quantified model logic, we precisely formulate principles derived from deontological ethics and show how they imply particular “test propositions” for any given action plan in an AI rule base. The action plan is ethical only if the test proposition is empirically true, a judgment that is made on the basis of empirical VA. This permits empirical VA to integrate seamlessly with independently justified ethical principles. This article is part of the special track on...
Leon Kester
Being a complex subject of major importance in AI Safety research, value alignment has been studied from various perspectives in the last years. However, no final consensus on the design of ethical utility functions facilitating AI value alignment has been achieved yet. Given the urgency to identify systematic solutions, we postulate that it might be useful to start with the simple fact that for the utility function of an AI not to violate human ethical intuitions, it trivially has to be a model of these intuitions and reflect their variety $ - $ whereby the most accurate models pertaining to human entities being biological organisms equipped with a brain constructing concepts like moral judgements, are scientific models. Thus, in order to better assess the variety of human morality, we perform a transdisciplinary analysis applying a security mindset to the issue and summarizing variety-relevant background knowledge from neuroscience and psychology. We complement this information by...
Frontiers in Psychology
Ana Luize Correa Bertoncini
Artificial intelligence (AI) advancements are changing people's lives in ways never imagined before. We argue that ethics used to be put in perspective by seeing technology as an instrument during the first machine age. However, the second machine age is already a reality, and the changes brought by AI are reshaping how people interact and flourish. That said, ethics must also be analyzed as a requirement in the content. To expose this argument, we bring three critical points-autonomy, right of explanation, and value alignment-to guide the debate of why ethics must be part of the systems, not just in the principles to guide the users. In the end, our discussion leads to a reflection on the redefinition of AI's moral agency. Our distinguishing argument is that ethical questioning must be solved only after giving AI moral agency, even if not at the same human level. For future research, we suggest appreciating new ways of seeing ethics and finding a place for machines, using the inputs of the models we have been using for centuries but adapting to the new reality of the coexistence of artificial intelligence and humans.
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
Advances in Robotics & Mechanical Engineering
Thibault de Swarte
2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Fabrice Muhlenbach
Alice Pavaloiu , Utku Köse
The Oxford Handbook of Digital Ethics (OUP)
Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society
Stephen Cave
Mark R Waser
Digital Society
Rohan Light
Etikk i Prakkis: Nordic Journal for Applied Ethics
Thomas Søbirk Petersen
AI & SOCIETY
Felix S H Yeung
Drew Hemment
Hanyang Law Review
The Academic
Sanghamitra Choudhury
IOSR Journals
Philosophy and Computers - Newsletter, American Philosphical Association
Niklas Toivakainen
Zoya Slavina
Micheal Tamale
2021 IEEE Conference on Norbert Wiener in the 21st Century (21CW)
Theology and Science
Mark Graves , Jane Compson , Cyrus Olsen
Seth D Baum
Journal of Intelligence Studies in Business
Anuradha Kanade
Joanna Bryson
Mrinalini Luthra
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
How Do We Align Artificial Intelligence with Human Values?

A major change is coming, over unknown timescales but across every segment of society, and the people playing a part in that transition have a huge responsibility and opportunity to shape it for the best. What will trigger this change? Artificial Intelligence.
Recently, some of the top minds in Artificial Intelligence (AI) and related fields got together to discuss how we can ensure AI remains beneficial throughout this transition, and the result was the Asilomar AI Principles document. The intent of these 23 principles is to offer a framework to help artificial intelligence benefit as many people as possible. But, as AI expert Toby Walsh said of the Principles, “Of course, it’s just a start…a work in progress.”
The Principles represent the beginning of a conversation, and now that the conversation is underway, we need to follow up with broad discussion about each individual principle. The Principles will mean different things to different people, and in order to benefit as much of society as possible, we need to think about each principle individually.
As part of this effort, I interviewed many of the AI researchers who signed the Principles document to learn their take on why they signed and what issues still confront us.
Value Alignment
Today, we start with the Value Alignment principle.
Value Alignment: Highly autonomous AI systems should be designed so that their goals and behaviors can be assured to align with human values throughout their operation.
Stuart Russell, who helped pioneer the idea of value alignment, likes to compare this to the King Midas story . When King Midas asked for everything he touched to turn to gold, he really just wanted to be rich. He didn’t actually want his food and loved ones to turn to gold. We face a similar situation with artificial intelligence: how do we ensure that an AI will do what we really want, while not harming humans in a misguided attempt to do what its designer requested?
“Robots aren’t going to try to revolt against humanity,” explains Anca Dragan , an assistant professor and colleague of Russell’s at UC Berkeley, “they’ll just try to optimize whatever we tell them to do. So we need to make sure to tell them to optimize for the world we actually want.”
What Do We Want?
Understanding what “we” want is among the biggest challenges facing AI researchers.
“The issue, of course, is to define what exactly these values are, because people might have different cultures, different parts of the world, different socioeconomic backgrounds — I think people will have very different opinions on what those values are. And so that’s really the challenge,” says Stefano Ermon , an assistant professor at Stanford.
Roman Yampolskiy , an associate professor at the University of Louisville, agrees. He explains, “It is very difficult to encode human values in a programming language, but the problem is made more difficult by the fact that we as humanity do not agree on common values, and even parts we do agree on change with time.”
And while some values are hard to gain consensus around, there are also lots of values we all implicitly agree on. As Russell notes , any human understands emotional and sentimental values that they’ve been socialized with, but it’s difficult to guarantee that a robot will be programmed with that same understanding.
But IBM research scientist Francesca Rossi is hopeful. As Rossi points out, “there is scientific research that can be undertaken to actually understand how to go from these values that we all agree on to embedding them into the AI system that’s working with humans.”
Dragan’s research comes at the problem from a different direction. Instead of trying to understand people, she looks at trying to train a robot or AI to be flexible with its goals as it interacts with people. “At Berkeley,” she explains, “we think it’s important for agents to have uncertainty about their objectives, rather than assuming they are perfectly specified, and treat human input as valuable observations about the true underlying desired objective.”
Rewrite the Principle?
While most researchers agree with the underlying idea of the Value Alignment Principle, not everyone agrees with how it’s phrased, let alone how to implement it.
Yoshua Bengio , an AI pioneer and professor at the University of Montreal, suggests “assured” may be too strong. He explains, “It may not be possible to be completely aligned. There are a lot of things that are innate, which we won’t be able to get by machine learning, and that may be difficult to get by philosophy or introspection, so it’s not totally clear we’ll be able to perfectly align. I think the wording should be something along the lines of ‘we’ll do our best.’ Otherwise, I totally agree.”
Walsh, who’s currently a guest professor at the Technical University of Berlin, questions the use of the word “highly.” “I think any autonomous system, even a lowly autonomous system, should be aligned with human values. I’d wordsmith away the ‘high,’” he says.
Walsh also points out that, while value alignment is often considered an issue that will arise in the future, he believes it’s something that needs to be addressed sooner rather than later. “I think that we have to worry about enforcing that principle today,” he explains. “I think that will be helpful in solving the more challenging value alignment problem as systems get more sophisticated.
Rossi, who supports the the Value Alignment Principle as, “the one closest to my heart,” agrees that the principle should apply to current AI systems. “I would be even more general than what you’ve written in this principle,” she says. “Because this principle has to do not only with autonomous AI systems, but … is very important and essential also for systems that work tightly with humans-in-the-loop and where the human is the final decision maker. When you have a human and machine tightly working together, you want this to be a real team.”
But as Dragan explains, “This is one step toward helping AI figure out what it should do, and continuously refining the goals should be an ongoing process between humans and AI.”
Let the Dialogue Begin
And now we turn the conversation over to you. What does it mean to you to have artificial intelligence aligned with your own life goals and aspirations? How can it be aligned with you and everyone else in the world at the same time? How do we ensure that one person’s version of an ideal AI doesn’t make your life more difficult? How do we go about agreeing on human values, and how can we ensure that AI understands these values? If you have a personal AI assistant, how should it be programmed to behave? If we have AI more involved in things like medicine or policing or education, what should that look like? What else should we, as a society, be asking?
About the Future of Life Institute
The Future of Life Institute (FLI) is a global non-profit with a team of 20+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work .
Related content
Other posts about ai , ai safety principles , recent news.

Mary Robinson (Former President of Ireland) on Long-View Leadership

Verifiable Training of AI Models

Poll Shows Broad Popularity of CA SB1047 to Regulate AI

FLI Praises AI Whistleblowers While Calling for Stronger Protections and Regulation
Sign up for the future of life institute newsletter.
Dr. Ian O'Byrne

Leave A Comment Cancel reply
Your email address will not be published. Required fields are marked *
This site uses Akismet to reduce spam. Learn how your comment data is processed .
To respond on your own website, enter the URL of your response which should contain a link to this post's permalink URL. Your response will then appear (possibly after moderation) on this page. Want to update or remove your response? Update or delete your post and re-enter your post's URL again. ( Learn More )
More From Forbes
The Dangers Of Not Aligning Artificial Intelligence With Human Values
- Share to Facebook
- Share to Twitter
- Share to Linkedin
In artificial intelligence (AI), the “alignment problem” refers to the challenges caused by the fact that machines simply do not have the same values as us. In fact, when it comes to values, then at a fundamental level, machines don't really get much more sophisticated than understanding that 1 is different from 0.
As a society, we are now at a point where we are starting to allow machines to make decisions for us. So how can we expect them to understand that, for example, they should do this in a way that doesn’t involve prejudice towards people of a certain race, gender, or sexuality? Or that the pursuit of speed, or efficiency, or profit, has to be done in a way that respects the ultimate sanctity of human life?
Theoretically, if you tell a self-driving car to navigate from point A to point B, it could just smash its way to its destination, regardless of the cars, pedestrians, or buildings it destroys on its way.
Similarly, as Oxford philosopher Nick Bostrom outlined, if you tell an intelligent machine to make paperclips, it might eventually destroy the whole world in its quest for raw materials to turn into paperclips. The principle is that it simply has no concept of the value of human life or materials or that some things are too valuable to be turned into paperclips unless it is specifically taught it.
This forms the basis of the latest book by Brian Christian, The Alignment Problem – How AI Learns Human Values . It’s his third book on the subject of AI following his earlier works, The Most Human Human and Algorithms to Live By . I have always found Christian’s writing enjoyable to read but also highly illuminating, as he doesn’t worry about getting bogged down with computer code or mathematics. But that’s certainly not to say it is in any way lightweight or not intellectual.
Best Travel Insurance Companies
Best covid-19 travel insurance plans.
Rather, his focus is on the societal, philosophical, and psychological implications of our ever-increasing ability to create thinking, learning machines. If anything, this is the aspect of AI where we need our best thinkers to be concentrating their efforts. The technology, after all, is already here – and it’s only going to get better. What’s far less certain is whether society itself is mature enough and has sufficient safeguards in place to make the most of the amazing opportunities it offers - while preventing the serious problems it could bring with it from becoming a reality.
I recently sat down with Christian to discuss some of the topics. Christian’s work is particularly concerned with the encroachment of computer-aided decision-making into fields such as healthcare, criminal justice, and lending, where there is clearly potential for them to cause problems that could end up affecting people’s lives in very real ways.
“There is this fundamental problem … that has a history that goes back to the 1960s, and MIT cyberneticist Norbert Wiener , who likened these systems to the story of the Sorcerer’s Apprentice,” Christian tells me.
Most people reading this will probably be familiar with the Disney cartoon in which Mickey Mouse attempts to save himself the effort of doing his master’s chores by using a magic spell to imbue a broom with intelligence and autonomy. The story serves as a good example of the dangers of these qualities when they aren't accompanied by human values like common sense and judgment.
“Wiener argued that this isn’t the stuff of fairytales. This is the sort of thing that’s waiting for us if we develop these systems that are sufficiently general and powerful … I think we are at a moment in the real world where we are filling the world with these brooms, and this is going to become a real issue.”
One incident that Christian uses to illustrate how this misalignment can play out in the real world is the first recorded killing of a pedestrian in a collision involving an autonomous car. This was the death of Elaine Herzberg in Arizona, US, in 2018.
When the National Transportation Safety Board investigated what had caused the collision between the Uber test vehicle and Herzberg, who was pushing a bicycle across a road, they found that the AI controlling the car had no awareness of the concept of jaywalking. It was totally unprepared to deal with a person being in the middle of the road, where they should not have been.
On top of this, the system was trained to rigidly segment objects in the road into a number of categories – such as other cars, trucks, cyclists, and pedestrians. A human being pushing a bicycle did not fit any of those categories and did not behave in a way that would be expected of any of them.
“That’s a useful way for thinking about how real-world systems can go wrong,” says Christian, “It’s a function of two things – the first is the quality of the training data. Does the data fundamentally represent reality? And it turns out, no – there’s this key concept called jaywalking that was not present.”
The second factor is our own ability to mathematically define what a system such as an autonomous car should do when it encounters a problem that requires a response.
“In the real world, it doesn't matter if something is a cyclist or a pedestrian because you want to avoid them either way. It's an example of how a fairly intuitive system design can go wrong."
Christian’s book goes on to explore these issues as they relate to many of the different paradigms that are currently popular in the field of machine learning, such as unsupervised learning, reinforcement learning, and imitation learning. It turns out that each of them presents its own challenges when it comes to aligning the values and behaviors of machines with the humans who are using them to solve problems.
Sometimes the fact that machine learning attempts to replicate human learning is the cause of problems. This might be the case when errors in data mean the AI is confronted with situations or behaviors that would never be encountered in real life, by a human brain. This means there is no reference point, and the machine is likely to continue making more and more mistakes in a series of "cascading failures."
In reinforcement learning – which involves training machines to maximize their chances of achieving rewards for making the right decision – machines can quickly learn to “game” the system, leading to outcomes that are unrelated to those that are desired. Here Christian uses the example of Google X head Astro Teller's attempt to incentivize soccer-playing robots to win matches. He devised a system that rewarded the robots every time they took possession of the ball – on the face of it, an action that seems conducive to match-winning. However, the machines quickly learned to simply approach the ball and repeatedly touch it. As this meant they were effectively taking possession of the ball over and over, they earned multiple rewards – although it did little good when it came to winning the match!
Christian’s book is packed with other examples of this alignment problem – as well as a thorough exploration of where we are when it comes to solving it. It also clearly demonstrates how many of the concerns of the earliest pioneers in the field of AI and ML are still yet to be resolved and touches on fascinating subjects such as attempts to imbue machines with other characteristics of human intelligence such as curiosity.
You can watch my full conversation with Brian Christian, author of The Alignment Problem – How AI Learns Human Values, on my YouTube channel:
- Editorial Standards
- Reprints & Permissions
Committed to connecting the world
- Media Centre
- Publications
- Areas of Action
- Regional Presence
- General Secretariat
- Radiocommunication
- Standardization
- Development
- Members' Zone
Designing AI for Human Values
Responsible Artificial Intelligence: Designing AI for Human Values
Artificial intelligence (AI) is increasingly affecting our lives in smaller or greater ways. In order to ensure that systems will uphold human values, design methods are needed that incorporate ethical principles and address societal concerns. In this paper, we explore the impact of AI in the case of the expected effects on the European labor market, and propose the accountability, responsibility and transparency (ART) design principles for the development of AI systems that are sensitive to human values.
Artificial intelligence, design for values, ethics, societal impact
| , Director of the , Secretary of (IFAAMAS) and was co-chair of (ECAI) in 2016. She has (co-)authored more than 150 peer-reviewed publications, including several books, and has wide experience with obtaining research funding both at national as international level. She is also the program director of the new MSc studies on AI and Robotics at the Delft University of Technology. |
General information
- ITU Journal: ICT Discoveries
- Editorial board
- Issue n.1: call for papers
- Alessia Magliarditi at [email protected]
© ITU All Rights Reserved
- Privacy notice
- Accessibility
- Report misconduct
- Digital Policy Hub
- Freedom of Thought
- Global AI Risks Initiative
- Supporting a Safer Internet
- Global Economic Scenarios
- Waterloo Security Dialogue
- Conference Reports
- Essay Series
- Policy Briefs
- Publication Series
- Special Reports
- Media Relations
- Opinion Series
- Big Tech Podcast
- Annual Report
- CIGI Campus
- Staff Directory
- Strategy and Evaluation
- The CIGI Rule
- Privacy Notice
- Artificial Intelligence
How Authoritarian Value Systems Undermine Global AI Governance
Cigi policy brief no. 187.
Digital authoritarianism is often considered an issue limited to a few illiberal regimes. However, neo-liberal AI technologies can be equally pervasive. It is crucial to treat authoritarianism as a values complex that permeates both autocratic and liberal societies.
Authoritarian values may manifest through transplant of legal practices between states, autocratic homogenization through multilateral mechanisms, and exploitation of geopolitical tensions to adopt protectionist policies. These approaches exacerbate public polarization around AI governance by creating a false dichotomy between innovation and sovereignty on the one hand, and fundamental rights on the other, chipping away at institutional trust.
Sabhanaz Rashid Diya writes that policy solutions to mitigate the erosion of democratic norms and public trust should focus on international mechanisms central to AI governance. These mechanisms need to introduce procedural safeguards that ensure transparency and accountability through equitable multi-stakeholder processes. Additionally, they should encourage regulatory diversity tailored to sociopolitical contexts and aligned with international human rights principles.
About the Author
Sabhanaz Rashid Diya is a CIGI senior fellow and the founder of Tech Global Institute, a global tech policy think tank focused on reducing equity and accountability gaps between technology companies and the global majority.
Recommended

- National Security
- Transformative Technologies
Digital Authoritarianism: The Role of Legislation and Regulation
- Marie Lamensch
- Global Cooperation
Framework Convention on Global AI Challenges
- Duncan Cass-Beggs
- Stephen Clare
- Dawn Dimowo

- Platform Governance
In Brazil, “Techno-Authoritarianism” Rears Its Head
Explainable ai policy: it is time to challenge post hoc explanations.
- Mardi Witzel
- Gaston H. Gonnet
- Geopolitics
Geopolitics, Diplomacy and AI
- Tracey Forrest
Knowledge as Power in Today’s World
- Nikolina Zivkovic
- Reanne Cayenne
- Kailee Hilt
Can There Be a Win-Win in the Era of AI? The Answer Is Yes
- Anthony Ilukwe
China’s Robots Are Coming of Age
- Daniel Araya
Digital Flux Has Coarsened the Mediascape of the World’s Largest Democracy
- Sanjay Ruparelia
Concerns Remain about Transparency in the UK’s Digital Campaign
- Kate Dommett
Digital Regulation May Have Bolstered European Elections — but How Would We Know?
- Heidi Tworek
Will Autonomous AI Bring Increased Productivity, Cognitive Decline, or Both?
- Peter MacKinnon
REVIEW article
From outputs to insights: a survey of rationalization approaches for explainable text classification.

- 1 Department of Computer Science, The University of Manchester, Manchester, United Kingdom
- 2 ASUS Intelligent Cloud Services (AICS), ASUS, Singapore, Singapore
Deep learning models have achieved state-of-the-art performance for text classification in the last two decades. However, this has come at the expense of models becoming less understandable, limiting their application scope in high-stakes domains. The increased interest in explainability has resulted in many proposed forms of explanation. Nevertheless, recent studies have shown that rationales , or language explanations, are more intuitive and human-understandable, especially for non-technical stakeholders. This survey provides an overview of the progress the community has achieved thus far in rationalization approaches for text classification. We first describe and compare techniques for producing extractive and abstractive rationales. Next, we present various rationale-annotated data sets that facilitate the training and evaluation of rationalization models. Then, we detail proxy-based and human-grounded metrics to evaluate machine-generated rationales. Finally, we outline current challenges and encourage directions for future work.
1 Introduction
Text classification is one of the fundamental tasks in Natural Language Processing (NLP) with broad applications such as sentiment analysis and topic labeling, among many others ( Aggarwal and Zhai, 2012 ; Vijayan et al., 2017 ). Over the past two decades, researchers have leveraged the power of deep neural networks to improve model accuracy for text classification ( Kowsari et al., 2019 ; Otter et al., 2020 ). Nonetheless, the performance improvement has come at the cost of models becoming less understandable for developers, end-users, and other relevant stakeholders ( Danilevsky et al., 2020 ). The opaqueness of these models has become a significant obstacle to their development and deployment in high-stake sectors such as the medical ( Tjoa and Guan, 2020 ), legal ( Bibal et al., 2021 ), and humanitarian domains ( Mendez et al., 2022 ).
As a result, Explainable Artificial Intelligence (XAI) has emerged as a relevant research field aiming to develop methods and techniques that allow stakeholders to understand the inner workings and outcome of deep learning-based systems ( Gunning et al., 2019 ; Arrieta et al., 2020 ). Several lines of evidence suggest that providing insights into text classifiers' inner workings might help to foster trust and confidence in these systems, detect potential biases or facilitate their debugging ( Arrieta et al., 2020 ; Belle and Papantonis, 2021 ; Jacovi and Goldberg, 2021 ).
One of the most well-known methods for explaining the outcome of a text classifier is to build reliable associations between the input text and output labels and determine how much each element (e.g., word or token) contributes toward the final prediction ( Hartmann and Sonntag, 2022 ; Atanasova et al., 2024 ). Under this approach, methods can be divided into feature importance score-based explanations ( Simonyan et al., 2014 ; Sundararajan et al., 2017 ), perturbation-based explanations ( Zeiler and Fergus, 2014 ; Chen et al., 2020 ), explanations by simplification ( Ribeiro et al., 2016b ) or language explanations ( Lei et al., 2016 ; Liu et al., 2019a ). It is important to note that the categories cited above are not mutually exclusive, and explainability methods can combine several. This is exemplified in the work undertaken by Ribeiro et al. (2016a) , who developed the Local Interpretable Model-Agnostic Explanations method (LIME) combining perturbation-based and explanations by simplification.
Rationalization methods attempt to explain the outcome of a model by providing a natural language explanation ( rationale ; Lei et al., 2016 ). It has previously been observed that rationales are more straightforward to understand and easier to use since they are verbalized in human-comprehensible natural language ( DeYoung et al., 2020 ; Wang and Dou, 2022 ). It has been shown that for text classification, annotators look for language cues within a text to support their labeling decisions at a class level ( human rationales ; Chang et al., 2019 ; Strout et al., 2019 ; Jain et al., 2020 ).
Rationales for explainable text classification can be categorized into extractive and abstractive rationales ( Figure 1 ). On the one hand, extractive rationales are a subset of the input text that support a model's prediction ( Lei et al., 2016 ; DeYoung et al., 2020 ). On the other hand, abstractive rationales are texts in natural language that are not constrained to be grounded in the input text. Like extractive rationales, they contain information about why an instance is assigned a specific label ( Camburu et al., 2018 ; Liu et al., 2019a ).

Figure 1 . Example of an extractive and abstractive rationale supporting the sentiment classification for a movie review.
This survey refers to approaches where human rationales are not provided during training, as unsupervised rationalization methods ( Lei et al., 2016 ; Yu et al., 2019 ). In contrast, we refer to those for producing rationales where human rationales are available as additional supervision signal during training, as supervised rationalization methods ( Bao et al., 2018 ; DeYoung et al., 2020 ; Arous et al., 2021 ).
Even though XAI is a relatively new research field, several studies have begun to survey explainability methods for NLP. Drawing on an extensive range of sources, Danilevsky et al. (2020) and Zini and Awad (2022) provided a comprehensive review of terminology and fundamental concepts relevant to XAI for different NLP tasks without going into the technical details of any existing method or taking into account peculiarities associated with text classification. As noted by Atanasova et al. (2024) , many explainability techniques are available for text classification. Their survey contributed to the literature by delineating a list of explainability methods used for text classification. Nonetheless, the study did not include rationalization methods and language explanations.
More recently, attention has been focussed on rationalization as a more accessible explainability technique in NLP. Wang and Dou (2022) and Gurrapu et al. (2023) discussed literature around rationalization across various NLP tasks, including challenges and research opportunities in the field. Their work, provides a high-level analysis suitable for a non-technical audience. Similarly, Hartmann and Sonntag (2022) provided a brief overview of methods for learning from human rationales beyond supervised rationalization architectures aiming to inform decision-making for specific use cases. Finally, Wiegreffe and Marasović (2021) identified a list of human-annotated data sets with textual explanations and compared the strengths and shortcomings of existing data collection methodologies. However, it is beyond the scope of this study to examine how these data sets can be used in different rationalization approaches. To the best of our knowledge, no research has been undertaken to survey rationalization methods for text classification.
This survey paper does not attempt to survey all available explainability techniques for text classification comprehensively. Instead, we will compare and contrast state-of-the-art rationalization techniques and their evaluation metrics, providing an easy-to-digest entry point for new researchers in the field. In summary, the objectives of this survey are to:
1. Study and compare different rationalization methods;
2. Compile a list of rationale-annotated data sets for text classification;
3. Describe evaluation metrics for assessing the quality of machine-generated rationales; and
4. Identify knowledge gaps that exist in generating and evaluating rationales.
From January 2007 to December 2023, our survey paper's articles were retrieved from Google Scholar using the keywords “rationales,” “natural language explanations,” and “rationalization.” We have included 88 peer-reviewed publications on NLP and text classification from journals, books, and conference proceedings from venues such as ACL, EMNLP, LREC, COLING, NAACL, AAAI, and NeurIPS.
Figure 2 reveals that there has been a shared increase in the number of research articles on rationalization for explainable text classification since the publication of the first rationalization approach by Lei et al. (2016) . Similarly, the number of research articles on XAI has doubled yearly since 2016. While the number of articles on rationalization peaked in 2021 and has slightly dropped since then to reach 13 articles in 2023, the number of publications on XAI has kept growing steadily. It is important to note that articles published before 2016 focus on presenting rationale-annotated datasets linked to learning with rationales research instead of rationalization approaches within the XAI field.

Figure 2 . Evolution of the number of peer-reviewed publications on rationalization for text classification (bar chart, left y-axis) and XAI (line chart, right y-axis) from 2007 to 2023.
This survey article is organized as follows: Section 2 describes extractive and abstractive rationalization approaches. Section 3 compiles a list of rationale-annotated data sets for text classification. Section 4 outlines evaluation metrics proposed to evaluate and compare rationalization methods. Finally, Section 5 discusses challenges, points out gaps and presents recommendations for future research on rationalization for explainable text classification.
2 Rationalization methods for text classification
We now formalize extractive and abstractive rationalization approaches and compare them in the context of text classification. We define a standard text classification in which we are given an input sequence x = [ x 1 , x 2 , x 3 , …, x l ], where x i is the i -th word of the sequence, and l is the sequence length. The learning problem is to assign the input sequence x to one or multiple labels in y ∈{1, …, c }, where c is the number of classes.
Figure 3 presents an overview of rationalization methods for producing extractive and abstractive rationales. While extractive rationalization models can be categorized into extractive or attention-based methods, abstractive rationalization models can be classified into generative and text-to-text methods. Finally, the component of both extractive and abstractive methods can be trained either using multi-task learning or independently as pipelined architecture.

Figure 3 . Overview of extractive and abstractive rationalization approaches in explainable text classification.
2.1 Extractive rationalization
In extractive rationalization, the goal is to make a text classifier explainable by uncovering parts of the input sequence that the prediction relies on the most ( Lei et al., 2016 ). To date, researchers have proposed two approaches for extractive rationalization for explainable text classification: (i) extractive methods, which first extract evidence from the original text and then make a prediction solely based on the extracted evidence ( Lei et al., 2016 ; Jain et al., 2020 ; Arous et al., 2021 ), and (ii) attention-based methods, which leverage the self-attention mechanism to show the importance of words through their attention weights ( Bao et al., 2018 ; Vashishth et al., 2019 ; Wiegreffe and Pinter, 2019 ).
Table 1 presents an overview of the current techniques for extractive rationalization, where we specify methods, learning approaches taken and their most influential references.

Table 1 . Overview of common approaches for extractive rationalization.
2.1.1 Extractive methods
Most research on extractive methods has been carried out using an encoder-decoder framework ( Lei et al., 2016 ; DeYoung et al., 2020 ; Arous et al., 2021 ). The encoder enc ( x ) works as a tagging model, where each word in the input sequence receives a binary tag indicating whether it is included in the rationales r ( Zaidan et al., 2007 ). The decoder dec ( x, r ) then accepts only the input highlighted as rationales and maps them to one or more target categories ( Bao et al., 2018 ).
The selection of words is performed by an encoder , which is a parameterized mapping enc ( x ) that extracts rationales from input sequences as r = { x i | z i = 1, x i ∈ x }, where z i ∈{0, 1} is a binary tag that indicates whether the word x i is selected or not. In an extractive setting, the rationale r must include only a few words or sentences, and dec ( enc ( x, r )) should result in nearly the same target vector as the original input when passed through the decoder dec ( x ) ( Otter et al., 2020 ; Wang and Dou, 2022 ).
2.1.1.1 Multi-task models
Lei et al. (2016) pioneered the idea of extracting rationales using the encoder-decoder architecture. They proposed utilizing two models and training them jointly to minimize a cost function composed of a classification loss and sparsity-inducing regularization, responsible for keeping the rationales short and coherent. They identified rationales within the input text by assigning a binary Bernoulli variable to each word. Unfortunately, minimizing the expected cost was challenging since it involved summing over all possible choices of rationales in the input sequence. Consequently, they suggested training these models jointly via REINFORCE-based optimization ( Williams, 1992 ). REINFORCE involves sampling rationales from the encoder and training the model to generate explanations using reinforcement learning. As a result, the model is rewarded for producing rationales that align with desiderata defined in its cost function ( Zhang et al., 2021b ).
The key components of the solution proposed by Lei et al. (2016) are binary latent variables and sparsity-inducing regularization. As a result, their solution is marked by non-differentiability. Bastings et al. (2019) proposed to replace the Bernoulli variables with rectified continuous random variables, amenable for reparameterization and for which gradient estimation is possible without REINFORCE. Along the same lines, Madani and Minervini (2023) used Adaptive Implicit Maximum Likelihood ( Minervini et al., 2023 ), a recently proposed low-variance and low-bias gradient estimation method for discrete distribution to back-propagate through the rationale extraction process. Paranjape et al. (2020) emphasized the challenges around the sparsity-accuracy trade-off in norm-minimization methods such as the ones proposed by Lei et al. (2016) and Bastings et al. (2019) . In contrast, they showed that it is possible to better manage this trade-off by optimizing a bound on the Information Bottleneck objective ( Mukherjee, 2019 ) using the divergence between the encoder and a prior distribution with controllable sparsity levels.
Over the last 15 years, research on learning with rationales has established that incorporating human explanations during model training can improve performance and robustness against spurious correlations ( Zaidan et al., 2007 ; Strout et al., 2019 ). Nonetheless, studies on explainability started addressing how human rationales can also help to enhance the quality of explanations for different NLP tasks ( Strout et al., 2019 ; Arous et al., 2021 ) only in the past 4 years.
To determine the impact of a supervised approach for extractive rationalization, DeYoung et al. (2020) adapted the implementation of Lei et al. (2016) , incorporating human rationales during training by modifying the model's cost function. Similarly, Bhat et al. (2021) developed a multi-task teacher-student framework based on self-training language models with limited task-specific labels and rationales. It is important to note that in the variants of the encoder-decoder architecture using human rationales, the final cost function is usually a composite of the classification loss, regularizers on rationale desiderata, and the loss over rationale predictions ( DeYoung et al., 2020 ; Gurrapu et al., 2023 ).
One of the main drawbacks of multi-task learning architectures for extractive rationales is that it is challenging to train the encoder and decoder jointly under instance-level supervision ( Zhang et al., 2016 ; Jiang et al., 2018 ). As described before, these methods sample rationales using regularization to encourage sparsity and contiguity and make it necessary to estimate gradients using either the REINFORCE method ( Lei et al., 2016 ) or reparameterized gradients ( Bastings et al., 2019 ). Both techniques complicate training and require careful hyperparameter tuning, leading to unstable solutions ( Jain et al., 2020 ; Kumar and Talukdar, 2020 ).
Furthermore, recent evidence suggests that multi-task rationalization models may also incur what is called the degeneration problem, where they produce nonsensical rationales due to the encoder overfitting to the noise generated by the decoder ( Madsen et al., 2022 ; Wang and Dou, 2022 ; Liu et al., 2023 ). To tackle this challenge, Liu et al. (2022) introduced a Folded Rationalization approach that folds the two stages of extractive rationalization models into one using a unified text representation mechanism for the encoder and decoder. Using a different approach, Jiang et al. (2023) proposed the YOFO (You Only Forward Once), a simplified single-phase framework with a pre-trained language model to perform prediction and rationalization. It is essential to highlight that rationales extracted using the YOFO framework aim only to support predictions and are not used directly to make model predictions.
2.1.1.2 Pipelined models
Pipelined models are a simplified version of the encoder-decoder architecture in which, first, the encoder is configured to extract the rationales. Then, the decoder is trained separately to perform prediction using only rationales ( Zhang et al., 2016 ; Jain et al., 2020 ). It is important to note that no parameters are shared between the two models and that rationales extracted based on this approach have been learned in an unsupervised manner since the encoder does not have access to human rationales during training.
To avoid the complexity of training a multi-task learning architecture, Jain et al. (2020) introduced FRESH (Faithful Rationale Extraction from Saliency tHresholding). Their scheme proposed using arbitrary feature importance scores to identify the rationales within the input sequence. An independent classifier is then trained exclusively on snippets the encoder provides to predict target labels. Similarly, Chrysostomou and Aletras (2022) proposed a method that also uses gradient-based scores as the encoder. However, their method incorporated additional constraints regarding length and contiguity for selecting rationales. Their work shows that adding these additional constraints can enhance the coherence and relevance of the extracted rationales, ensuring they are concise and contextually connected, thus improving the understanding and usability of the model in real-world applications.
Going beyond feature importance scores, Jiang et al. (2018) suggested using a reinforcement learning method to extract rationales using a reward function based on latent variables to define the extraction of phrases and classification labels. Their work indicates that reinforcement can optimize the rationale selection process, potentially leading to more accurate explanations by adjusting strategies based on feedback to maximize the reward function. Along the same lines, Guerreiro and Martins (2021) developed SPECTRA (SparsE StruCtured Text Rationalization), a framework based on LP-SparseMAP ( Niculae and Martins, 2020 ). Their method provided a flexible, deterministic and modular rationale extraction process based on a constrained structured prediction algorithm. It is important to note that incorporating a deterministic component can eventually boost the consistency and predictability of the extracted rationales, improving the reliability and reproducibility of explanations across different datasets and applications.
Simplifying the encoder-decoder architecture in extractive rationalization models might enhance its use in explainable NLP systems ( Jain et al., 2020 ; Wang and Dou, 2022 ). This simplification can lead to more computationally efficient models, broadening their applicability and accessibility in various real-world scenarios.
Recently, there has been increasing interest in leveraging Large Language Models (LLMs) for extractive rationalization, owing to their ability to efficiently process and distill critical information from large text corpora ( Wang and Dou, 2022 ; Gurrapu et al., 2023 ). The evidence reviewed here suggests that rationalization models might improve performance by prompting language models in a few-shot manner, with rationale-augmented examples. Using this approach, Chen et al. (2023) introduced ZARA, an approach for data augmentation and extractive rationalization using transformer-based models ( Vaswani et al., 2017 ) such as RoBERTa ( Liu et al., 2019b ), DeBERTa ( He et al., 2020 ), and BART ( Lewis et al., 2020 ). Along the same lines, Zhou et al. (2023) presented a two-stage few-shot learning method that first generates rationales using GPT-3 ( Brown et al., 2020 ), and then fine-tunes a smaller rationalization model, RoBERTa, with generated explanations. It is important to consider a few challenges of using LLMs for rationalization models, including high computational demands and the potential for ingrained biases that can skew language explanations ( Zhao et al., 2023 ).
Even though extractive rationalization may be a crucial component of NLP systems as it enhances trust by providing human-understandable explanations, far too little attention has been paid to its use in real-world applications ( Wang and Dou, 2022 ; Kandul et al., 2023 ). ExClaim is a good illustration of using extractive rationalization in a high-stake domain. Gurrapu et al. (2022) introduced ExClaim to provide an explainable claim verification tool for use in the legal sector based on extractive rationales that justify verdicts through natural language explanations. Similarly, Mahoney et al. (2022) presented an explainable architecture based on extractive rationales that explain the results of a machine learning model for classifying legal documents. Finally, Tornqvist et al. (2023) proposed a pipelined approach for extractive rationalization to provide explanations for an automatic grading system based on a transformer-based classifier and post-hoc explanability methods such as SHAP ( Lundberg and Lee, 2017 ) and Integrated Gradients ( Sundararajan et al., 2017 ).
2.1.2 Attention-based methods
Attention models have not only resulted in impressive performance for text classification ( Vaswani et al., 2017 ), but are also suitable as a potential explainability technique ( Vashishth et al., 2019 ; Wiegreffe and Pinter, 2019 ). In particular, the attention mechanism has been previously used to identify influential tokens for the prediction task by providing a soft score over the input units ( Bahdanau et al., 2015 ).
Researchers have drawn inspiration from the model architecture from Jain and Wallace (2019) for text classification. For a given input sequence x , each token is represented by its D -dimensional embedding to obtain x e ∈ ℝ D × d . Next, a bidirectional recurrent neural network (Bi-RNN) encoder is used to obtain an m -dimensional contextualized representation of tokens: h = E n c ( x e ) ∈ ℝ D × m . Finally, the additive formulation of attention proposed by Bahdanau et al. (2015) ( W ∈ ℝ D × D , b, c ∈ ℝ D are parameters of the model) is used for computing weights α i for all tokens defined as in Equation 1 :
The weighted instance representation h α = ∑ i = 1 T α i h i is fed to a dense layer and followed by a softmax function to obtain prediction ỹ = σ ( D e c ( h α ) ) ∈ ℝ | c | where | c | denotes the label set size. Finally, a heuristic strategy must be applied to map attention scores to discrete rationales. Examples include selecting spans within a document based on their total score (sum of their tokens' importance scores) or picking the top-k tokens with the highest attention scores ( Jain et al., 2020 ).
2.1.2.1 Soft-scores models
Some studies have proposed using variants of attention ( Bahdanau et al., 2015 ) to extract rationales in an unsupervised manner. For explainable text classification, Wiegreffe and Pinter (2019) investigated a model that passes tokens through a BERT model ( Devlin et al., 2019 ) to induce contextualized token representations that are then passed to a bidirectional LSTM ( Hochreiter and Schmidhuber, 1997 ). For soft-score features, they focused attention on the contextualized representation. Similarly, Vashishth et al. (2019) analyzed the attention mechanism on a more diverse set of NLP tasks and assessed how attention enables interpretability through manual evaluation.
Bao et al. (2018) extended the unsupervised approach described above by learning a mapping from human rationales to continuous attention. Like the supervised approach for extractive methods, they developed a model to map human rationales onto attention scores to provide richer supervision for low-resource models. Similarly, Strout et al. (2019) showed that supervising attention with human-annotated rationales can improve both the performance and explainability of results of a classifier based on Convolutional Neural Networks (CNNs; Lai et al., 2015 ). In the same vein, Kanchinadam et al. (2020) suggested adding a lightweight attention mechanism to a feed-forward neural network classifier and training them using human-annotated rationales as additional feedback.
Even though these are promising methods for extracting rationales, they require access to a significant number of rationale-annotated instances, which might be impractical for domain-specific applications where expert annotators are rare and constrained for time ( Vashishth et al., 2019 ; Kandul et al., 2023 ). Consequently, Zhang et al. (2021a) proposed HELAS (Human-like Explanation with Limited Attention Supervision). This approach requires a small proportion of documents to train a model that simultaneously solves the text classification task while predicting human-like attention weights. Similarly, Arous et al. (2021) introduced MARTA, a Bayesian framework based on variational inference that jointly learns an attention-based model while injecting human rationales during training. It is important to note that both approaches achieve state-of-the-art results while having access to human rationales for less than 10% of the input documents.
While attention mechanisms have been used for extractive rationalization, their effectiveness as a stand alone explainability method is debated ( Burkart and Huber, 2021 ; Niu et al., 2021 ). Data from several studies suggest that attention weights might misidentify relevant tokens in their explanations, or they are often uncorrelated with the importance score measured by other explainability methods ( Jain and Wallace, 2019 ; Bastings and Filippova, 2020 ). This uncertainty has significantly undermined the use of attention-based methods, as they can provide a false sense of understanding of the model's decision-making process, potentially leading to a misguided trust in the NLP system's capabilities and an underestimation of its limitations ( Kandul et al., 2023 ; Lyu et al., 2024 ).
2.2 Abstractive rationale generation
In abstractive rationalization, the aim is to generate natural language explanations to articulate the model's reasoning process describing why an input sequence was mapped to a particular target vector. Abstractive rationales may involve synthesizing or paraphrasing information rather than directly extracting snippets from the input text ( Liu et al., 2019a ; Narang et al., 2020 ).
Although extractive rationales are very useful to understand the inner workings of a text classifier, there is a limitation when employing them in tasks that should link commonsense knowledge information to decisions, such as natural language inference (NLI), question-answering, and text classification ( Camburu et al., 2018 ; Rajani et al., 2019 ). In such cases, rather than extracting relevant words from the input sequence, it is more desirable to provide a more synthesized and potentially insightful overview of the model's decision-making, often resembling human-like reasoning ( Liu et al., 2019a ; Narang et al., 2020 ).
There are two main approaches currently being adopted in research into abstractive rationalization: (i) text-to-text methods, which rely on sequence-to-sequence translation models such as the Text-to-Text Transfer Transformer (T5) framework proposed by Raffel et al. (2020) including both the label and the explanation at the same time, and (ii) generative methods, which first generate a free-form explanation and then makes a prediction based on the produced abstractive rationale ( Zhou et al., 2020 ). Table 2 presents an overview of the methods used to produce abstractive rationales and their representative references.

Table 2 . Overview of common approaches for abstractive rationale generation.
It is important to note that a relatively small body of literature is concerned with abstractive rationalization for explainable text classification. Abstractive rationales are used less frequently than extractive rationales primarily due to the higher complexity and technical challenges in generating coherent, accurate, and relevant synthesized explanations ( Madsen et al., 2022 ; Ji et al., 2023 ). Consequently, most of the studies on abstractive rationalization have been based on supervised methods, where human explanations are provided during the model's training ( Liu et al., 2019a ; Zhou et al., 2020 ).
2.2.1 Text-to-text methods
A text-to-text model follows the sequence-to-sequence (seq2seq) framework ( Sutskever et al., 2014 ), where it is fed a sequence of discrete tokens as input and produces a new sequence of tokens as output. Using this approach, researchers have leveraged the T5 framework to train a joint model designed to generate explanations and labels simultaneously ( Raffel et al., 2020 ). Consequently, a model is fit to maximize the following conditional likelihood of the target label y and explanations e given the input text x as defined in Equation 2 :
2.2.1.1 Multi-task models
Text-to-text methods for generating abstractive rationales leverage the text-to-text framework proposed by Raffel et al. (2020) to train language models to output natural text explanations alongside their predictions. A study by Narang et al. (2020) showed that their WT5 model (T5 models using “base” and “11B” configurations; Raffel et al., 2020 ) achieved state-of-the-art results with respect to the quality of explanations and classification performance, when having access to a relatively large set of labeled examples. Finally, they also claimed that their WT5 model could help transfer a model's explanation capabilities across different data sets.
Similarly, Jang and Lukasiewicz (2021) conducted experiments evaluating abstractive rationales generated by a T5-base model for text classification and NLI. Nevertheless, their work emphasized the need to reduce the volume of rationale-annotated data and the computational requirements required to train these models to produce comprehensive and contextually appropriate rationales.
Text-to-text models have shown promising results for improving the understanding of classification models and increasing the prediction performance using explanations as additional features ( Gilpin et al., 2018 ; Danilevsky et al., 2020 ). However, their training requires a large number of human-annotated rationales. This property precludes the development of free-text explainable models for high-stake domains where rationale-annotated data sets are scarcely available ( Jang and Lukasiewicz, 2021 ).
2.2.2 Generative methods
Researchers investigating generative methods have utilized a generator-decoder framework ( Camburu et al., 2018 ; Rajani et al., 2019 ), which is similar to the encoder-decoder used for extractive rationalization. The generator gen ( x ) works as a seq2seq model where each input sequence is mapped onto a free-form explanation ( Zhou et al., 2020 ). The decoder dec ( x ) then takes the abstractive rationale to predict the target vector ( Jang and Lukasiewicz, 2021 ).
By using the multiplication law of conditional probability, we can decompose Equation (3) and formulate the training of generative methods as Zhou et al. (2020) :
An explanation generator model gen ( x ) that parameterizes p ( e i | x i ) takes an input sequence x and generates a corresponding natural language explanation e . As mentioned, the abstractive rationale might not be found in the input sequence x ( Zhou et al., 2020 ). The decoder dec ( x, e ) is an augmented prediction model, which parameterizes p ( y i | x i , e i ) and takes an input sequence x and an explanation e to assign a target vector y ( Rajani et al., 2019 ; Atanasova et al., 2020 ).
A significant advantage of generative methods for abstractive rationalization is that they require significantly fewer human-annotated examples for training an explainable text classification model than text-to-text methods. Due to their flexibility in creating new content, generative methods allow for a broader range of expressive and contextually relevant rationales that can closely mimic human-like explanations ( Liu et al., 2019a ; Zhou et al., 2020 ).
2.2.2.1 Pipelined models
As with extractive methods, pipelined models for abstractive rationalization simplify the generator-decoder architecture. Both modules are trained independently, with no parameters shared between the two models. Kumar and Talukdar (2020) proposed a framework where a pre-trained language model based on the GPT-2 architecture ( Radford et al., 2019 ) is trained using a causal language modeling loss (CLM). An independent RoBERTa-based ( Liu et al., 2019b ) classifier is then fit on the abstractive rationales to predict target labels. Similarly, Zhao and Vydiswaran (2021) introduced LiREX, a framework also based on a GPT-2-based generator and a decoder leveraging RoBERTa. However, this framework included an additional component at the start of the pipeline that first extracts a label-aware token-level extractive rationale and employs it to generate abstractive explanations. Due to the possibility of generating label-aware explanations, LiREX is especially suitable for multi-label classification problems.
2.2.2.2 Multi-task models
Drawing inspiration from the work of Camburu et al. (2018) on abstractive rationalization for explainable NLI, Zhou et al. (2020) developed the ELV (Explanations as Latent Variables) framework. They used a variational expectation-maximization algorithm ( Palmer et al., 2005 ) for optimization where an explanation generation module and an explanation-augmented BERT module are trained jointly. They considered natural language explanations as latent variables that model the underlying reasoning process of neural classifiers. Since training a seq2seq model to generate explanations from scratch is challenging, they used UniLM ( Dong et al., 2019 ), a pre-trained language generation model, as the generation model in their framework. Similarly, Li et al. (2021) proposed a joint neural predictive approach to predict and generate abstractive rationales and applied it to English and Chinese medical documents. As generators, they used the large version of T5 (T5 large; Raffel et al., 2020 ) and its multilingual version, mT5 ( Xue et al., 2021 ). For classification, they applied ALBERT ( Lan et al., 2019 ) and RoBERTa ( Liu et al., 2019b ) on the English and Chinese data sets, respectively. Even though they found that the multi-task learning approach boosted model explainability, the improvement in their experiments was not statistically significant.
A few studies have shown that generative methods sometimes fail to build reliable connections between abstractive rationales and predicted outcomes ( Carton et al., 2020 ; Wiegreffe et al., 2021 ). Therefore, there is no guarantee that the generated explanations reflect the decision-making process of the prediction model ( Tan, 2022 ). To generate faithful explanations, Liu et al. (2019a) suggested using an explanation factor to help build stronger connections between explanations and predictions. Their Explanation Factor (EF) considers the distance between the generated and the gold standard rationales and the relevance between the abstractive rationales and the original input sequence. Finally, they included EF in the objective function and jointly trained the generator and decoder to achieve state-of-the-art results for predicting and explaining product reviews.
New findings amongst abstractive rationalization provide further evidence that models are prone to hallucination ( Kunz et al., 2022 ; Ji et al., 2023 ). In explainable text classification, hallucination refers to cases where a model produces factually incorrect or irrelevant rationales, thus impacting the reliability and trustworthiness of these explanations ( Zhao et al., 2023 ). Even though most evaluation metrics punish hallucination and try to mitigate it during training, the irrelevant rationales included might add helpful information for the classification step and, therefore, be used regardless. This phenomenon can mislead users about the model's decision-making process, undermining the credibility of NLP systems and posing challenges for its practical application in scenarios requiring high accuracy and dependability ( Wang and Dou, 2022 ; Ji et al., 2023 ).
Zero-shot approaches are increasingly relevant in NLP as they allow models to process language tasks they have not been explicitly trained on, enhancing their adaptability as part of real-world solutions where training data is not necessarily available ( Meng et al., 2022 ). Even though there is a relatively small body of literature that is concerned with zero-shot rationalization approaches for explainable text classification, studies such as that conducted by Kung et al. (2020) and Lakhotia et al. (2021) have shown that zero-shot rationalization models achieve comparable performance without any supervised signal. Nevertheless, a significant challenge is the model's ability to produce relevant rationales for unseen classes, as it must extrapolate from learned concepts without direct prior knowledge ( Lyu et al., 2021 ). This capability requires understanding abstract and transferable features across different contexts, difficulting the training and deployment of these rationalization models ( Wei et al., 2021 ; Meng et al., 2022 ). It is important to note that, if successful, they can enhance the scalability of NLP systems by making them capable of analyzing data from various domains without needing extensive retraining ( Kung et al., 2020 ; Yuan et al., 2024 ).
3 Rationale-annotated datasets
During the last 15 years, there has been an increase in the volume of rationale-annotated data available, boosting progress on designing more explainable classifiers and facilitating the evaluation and benchmarking of rationalization approaches ( DeYoung et al., 2020 ; Wang and Dou, 2022 ).
Table 3 describes each rationale-annotated dataset for text classification in terms of their domain, the annotation procedure used to collect the human explanations (indicated as “author” or “crowd” for crowd-annotated), their number of instances (input-label pairs), their publication year and the original paper where they were presented. Moreover, it includes links to each dataset (when available), providing direct access for further exploration and detailed analysis.

Table 3 . Comparison of rationale-annotated datasets for text classification.
Incorporating human rationales during training of supervised learning models can be traced back to the work of Zaidan et al. (2007) , where a human teacher highlighted text spans in a document to improve model performance. Their MovieReviews(v.1.0) corpus is the first rationale-annotated dataset for text classification, including 1,800 positive/negative sentiment labels on movie reviews.
Table 3 shows that the dominant collection paradigm is via crowd sourcing platforms. A critical bottleneck of rationale generation is the insufficient domain-specific rationale-annotated data ( Lertvittayakumjorn and Toni, 2019 ). Gathering enough (input, label, and human rationales ) triples from potential end-users is essential as it provides rationalization models with a reference for what constitutes a meaningful and understandable explanation from a human perspective ( Strout et al., 2019 ; Carton et al., 2020 ; DeYoung et al., 2020 ). Rationale-annotated data is critical in real-world applications, where the alignment of machine-generated rationales with human reasoning greatly enhances the model's transparency, trustworthiness, and acceptance by users in practical scenarios ( Wang and Dou, 2022 ; Gurrapu et al., 2023 ).
Creating benchmark data sets with human annotations is essential for training and comparing rationalization models, as they provide a standardized resource to evaluate the effectiveness, accuracy, and human-likeness of model-generated explanations ( Jacovi and Goldberg, 2021 ; Wang and Dou, 2022 ). Such benchmarks facilitate consistent, objective comparison across different models, fostering advancements in the field by highlighting areas of strength and opportunities for improvement in aligning machine-generated explanations with human reasoning and understanding ( Kandul et al., 2023 ; Lyu et al., 2024 ). The task of extractive rationalization was surveyed by DeYoung et al. (2020) , who proposed the ERASER (Evaluating Rationales And Simple English Reasoning) benchmark spanning a range of NLP tasks. These data sets, including examples for text classification such as MovieReviews(v.2.0) and FEVER, have been repurposed from pre-existing corpora and augmented with labeled rationales ( Zaidan et al., 2007 ; Thorne et al., 2018 ). More recently, Marasović et al. (2022) introduced the FEB benchmark containing four English data sets for few-shot rationalization models, including the SBIC corpus for offensiveness classification.
Questions have been raised about using human-annotated rationales for training and evaluating rationalization models since they are shown to be quite subjective ( Lertvittayakumjorn and Toni, 2019 ; Carton et al., 2020 ). Most published studies failed to specify information about the annotators, such as gender, age, or ethnicity. Jakobsen et al. (2023) makes an essential contribution by being the first dataset to include annotators' demographics and human rationales for sentiment analysis. Diversity in collecting human rationales is crucial to the development of universally understandable and reliable models, enhancing their applicability and acceptance across a broad spectrum of stakeholders and scenarios ( Tan, 2022 ; Yao et al., 2023 ).
Finally, different methods have been proposed to collect human rationales for explainable text classification. On the one hand, in some studies (e.g., Zaidan et al., 2007 ), annotators were asked to identify the most important phrases and sentences supporting a label. On the other hand, in the work of Sen et al. (2020) , for example, all sentences relevant to decision-making were identified. Even though these approaches seem similar, they might lead to substantially different outcomes ( Hartmann and Sonntag, 2022 ; Tan, 2022 ). Documentation and transparency in the annotation of human rationales are essential as they provide clear insight into the reasoning process and criteria used by human annotators, ensuring replicability and trustworthiness in the model evaluation process ( Carton et al., 2020 ). This detailed documentation is crucial for understanding potential biases and the context under which these rationales were provided, thereby enhancing the credibility and generalizability of the rationalization models.
4 Evaluation metrics
The criteria for evaluating the quality of rationales in explainable text classification are not universally established. Generally, evaluation approaches fall into two categories: (i) proxy-based , where rationales are assessed based on automatic metrics that attempt to measure different desirable properties ( Carton et al., 2020 ; DeYoung et al., 2020 ), and (ii) human-grounded , where humans evaluate rationales in the context of a specific application or a simplified version of it ( Doshi-Velez and Kim, 2017 ; Lertvittayakumjorn and Toni, 2019 ).
Table 4 summarizes the categories for rationale evaluation, including metrics and their most relevant references.

Table 4 . Overview of evaluation metrics for rationale's quality.
4.1 Proxy-based
Plausibility in rationalization for text classification refers to the extent to which explanations provided by a model align with human intuition and understanding ( DeYoung et al., 2020 ; Wiegreffe et al., 2021 ). Plausible explanations enhance the trust and credibility of classifiers, as they are more likely to be understood and accepted by end-users, particularly those without technical expertise ( Doshi-Velez and Kim, 2017 ; Hase and Bansal, 2022 ; Atanasova et al., 2024 ). DeYoung et al. (2020) proposed evaluating plausibility using Intersection-over-Union at the token level to derive token-level precision, recall, and F1 scores. Several studies have followed a similar evaluation approach for extractive rationalization models ( Paranjape et al., 2020 ; Guerreiro and Martins, 2021 ; Chan A. et al., 2022 ), while others have explored using phrase-matching metrics such as SacreBLEU and METEOR ( Jang and Lukasiewicz, 2021 ) for evaluating abstractive rationales. In the case of attention-based methods that perform soft selection, DeYoung et al. (2020) suggested measuring plausibility using the Area Under the Precision-Recall Curve (AUPRC) constructed by sweeping a threshold over token scores ( DeYoung et al., 2020 ; Chan A. et al., 2022 ).
While plausibility is important for rationalization models, much of the literature acknowledges that generating plausible rationales is not enough ( Doshi-Velez and Kim, 2017 ; Arrieta et al., 2020 ; Danilevsky et al., 2020 ). Previous research has established that it is crucial to ensure that the rationales also reflect the actual reasoning processes of the model rather than being superficial or misleading ( Belle and Papantonis, 2021 ; Jacovi and Goldberg, 2021 ). Faithfulness refers to the degree to which the generated rationales accurately represent the internal decision-making process of the model. DeYoung et al. (2020) proposed two automatic metrics for assessing faithfulness by measuring the impact of perturbing or erasing snippets within language explanations. First, comprehensiveness captures the extent to which all relevant features for making a prediction were selected as rationales. Second, sufficiency assesses whether the snippets within rationales are adequate for a model to make a prediction. Using this approach, researchers have established that a faithful rationale should have high comprehensiveness and sufficiency ( Zhang et al., 2021a ; Chan A. et al., 2022 ).
Supporting this view, Carton et al. (2020) introduced the term fidelity to refer jointly to sufficiency and comprehensiveness. According to their findings, a rationale can contain many tokens irrelevant to the prediction while still having high comprehensiveness and low sufficiency. Consequently, they introduced the idea of fidelity curves to assess rationale irrelevancy by looking at how sufficiency and comprehensiveness degrade as tokens are randomly occluded from a language explanation. There is a consensus among researchers and practitioners that this level of authenticity in explanations is crucial for users to scrutinize NLP decisions, particularly in high-stake domains where understanding the model's reasoning is paramount ( Miller, 2019 ; Tjoa and Guan, 2020 ; Bibal et al., 2021 ).
Robustness refers to the model's ability to consistently provide reliable rationales across various inputs and conditions ( Gunning et al., 2019 ; Arrieta et al., 2020 ; Lyu et al., 2024 ). Robustness is crucial for explainable text classification as it ensures dependability and generalizability of the explanations, particularly in real-world applications where data variability and unpredictability are common ( Belle and Papantonis, 2021 ; Hartmann and Sonntag, 2022 ). Most researchers investigating robustness in rationalization models have utilized adversarial examples to evaluate the model's rationales to remain trustworthy and reliable in potentially deceptive environments ( Zhang et al., 2020 ; Liang et al., 2022 ). Using this approach, Chen H. et al. (2022) assessed the model's robustness by measuring performance on challenge datasets where human-annotated edits to inputs that can change classification labels, are available. Similarly, Ross et al. (2022) proposed assessing robustness by testing whether rationalization models are invariant to adding additional sentences and remain consistent with their predictions. Data from both studies suggest that rationalization models can improve robustness. However, leveraging human rationales as extra supervision does not always translate to more robust models.
It is important to note that most rationale evaluation research has focused on extractive rationalization models ( Carton et al., 2020 ; Hase and Bansal, 2020 ). Assessing abstractive rationales for explainable text classification presents several unique challenges. First, the subjective nature of abstractive rationales makes standardization of evaluation metrics, such as plausibility difficult, as these rationales do not necessarily align with references of the original input text ( Camburu et al., 2020 ; Zhao and Vydiswaran, 2021 ). Second, ensuring faithfulness and robustness of abstractive rationales is complex, as they involve generating new text that may not directly correspond to specific input features, making it challenging to determine whether the rationale reflects the model's decision-making reliably ( Dong et al., 2019 ; Zhou et al., 2020 ). These challenges highlight the need for innovative and adaptable evaluation frameworks that can effectively capture the multifaceted nature of abstractive rationales in explainable NLP systems.
4.2 Human-grounded
Even though the vast majority of research on rationale evaluation has been proxy-based, some studies have begun to examine human-grounded evaluations for explainable text classification ( Mohseni et al., 2018 ; Ehsan et al., 2019 ). Nevertheless, to our knowledge, there is no published research on human-grounded methods using domain experts in the same target application. Instead, we have found some studies conducting simpler human-subject experiments that maintain the essence of the target application.
According to Ehsan et al. (2019) , rationale understandability refers to the degree to which a rationale helped an observer understand why a model behaved as it did. They asked participants to rate the understandability of a set of rationales using a 5-point Likert scale. Instead, Lertvittayakumjorn and Toni (2019) used binary forced-choice experiments. As part of their research, humans were presented with pairs of explanations to choose the one they found more understandable.
Finally, researchers have also been interested in measuring simulatability using human-subject simulation experiments. In a qualitative study by Lertvittayakumjorn and Toni (2019) , humans were presented with input-explanation pairs and asked to simulate the model's outcomes correctly. Similarly, Ehsan et al. (2019) assessed simulatability using counterfactual simulation experiments. In this case, observers were presented with input-output-explanation triples and asked to identify what words needed to be modified to change the model's prediction to the desired outcome.
In an investigation into human-grounded metrics for evaluating rationales in text classification, Lertvittayakumjorn and Toni (2019) concluded that experiments and systems utilized to collect feedback on machine-generated rationales lack interactivity. In almost every study, users cannot contest a rationale or ask the system to explain the prediction differently. This view is supported by Ehsan et al. (2019) , who concluded that current human-grounded experiments could only partially assess the potential implications of language explanations in real-world scenarios.
Even though human-grounded evaluation is key in assessing the real-world applicability and effectiveness of rationalization models, it presents several challenges that stem from the inherent subjectivity and variability of human judgment ( Doshi-Velez and Kim, 2017 ; Carton et al., 2020 ). First, the diversity of interpretations among different evaluators can lead to an inconsistent assessment of the quality and relevance of the generated rationales ( Lertvittayakumjorn and Toni, 2019 ; Hase and Bansal, 2020 ). As mentioned before, this diversity is influenced by cultural background, domain expertise, and personal biases, making it difficult to consolidate a standardized evaluation metric ( Mohseni et al., 2018 ; Yao et al., 2023 ). Second, the cognitive load on human evaluators can be significant, especially when dealing with complex classification tasks or lengthy rationales, potentially affecting the consistency and reliability of their judgment ( Tan, 2022 ). Finally, there is the scalability challenge, as human evaluations are time-consuming and resource-intensive, limiting the feasibility of conducting large-scale assessments ( Kandul et al., 2023 ).
5 Challenges and future outlook
In this section, we discuss the current challenges in developing trustworthy rationalization models for explainable text classification and suggest possible approaches to overcome them.
5.1 Rationalization approaches
Extractive and abstractive rationalization approaches have distinct advantages and disadvantages when applied to explainable text classification. Table 5 summarizes the trade-offs of the rationalization methods described in Section 2.

Table 5 . Main advantages and disadvantages of methods for rationale generation.
Extractive rationalization, which involves selecting parts of the input text as justification for the model's decision, boasts the advantage of being directly linked to the original data, often making these explanations more straightforward and more accessible to validate for accuracy ( Wang and Dou, 2022 ; Gurrapu et al., 2023 ). However, this method can be limited in providing context or explaining decisions requiring synthesizing information not explicitly stated in the text ( Kandul et al., 2023 ; Lyu et al., 2024 ). Abstractive rationalization, which generates new text to explain the model's decision, offers greater flexibility and can provide more holistic and nuanced explanations that synthesize various aspects of the input data. This approach can be more intuitive and human-like, enhancing the comprehensibility for end-users ( Li et al., 2021 ; Zini and Awad, 2022 ). Yet, it faces challenges such as the risk of hallucination—producing explanations that are not grounded in the input data—and the complexity of ensuring that these generated explanations are both accurate and faithful to the model's decision-making process ( Liu et al., 2019a ; Hase and Bansal, 2020 ). Therefore, while extractive methods offer reliability and direct traceability, abstractive methods provide richness and depth, albeit with increased challenges in maintaining fidelity and accuracy ( Wiegreffe et al., 2021 ; Yao et al., 2023 ).
The choice between extractive and abstractive rationalization models for explainable text classification largely depends on the specific requirements and constraints of the application ( Wang and Dou, 2022 ; Gurrapu et al., 2023 ). On the one hand, extractive rationalization models are generally more suitable in scenarios where transparency and direct traceability to the original text are paramount. They are ideal when the rationale for a decision needs to be anchored to specific parts of the input text, such as in legal or compliance-related tasks where every decision must be directly linked to particular evidence or clauses ( Bibal et al., 2021 ; Lyu et al., 2024 ). On the other hand, abstractive rationalization models are better suited for scenarios where a more synthesized understanding or a broader context is necessary ( Miller, 2019 ; Kandul et al., 2023 ). They excel in situations where the rationale might involve drawing inferences or conclusions not explicitly stated in the text. Abstractive models are also preferable when the explanation needs to be more accessible to laypersons, as they can provide more natural, human-like explanations ( Amershi et al., 2014 ; Tjoa and Guan, 2020 ).
Even though the decision to use pipelined or multi-task learning models for rationalization depends on the specific goals and constraints, several studies suggest that multi-task learning models perform better for both extractive and abstractive rationalization ( Dong et al., 2019 ; Zhou et al., 2020 ; Li et al., 2021 ; Wang and Dou, 2022 ). Pipelined models are advantageous when each module, rationalization and classification, require specialized handling or when modularity is needed in the system ( Jain et al., 2020 ; Chrysostomou and Aletras, 2022 ). This approach allows for greater flexibility in updating each component independently. However, they can suffer from error propagation where the rationalization can affect the classification ( Kunz et al., 2022 ). In contrast, multi-task learning models are generally more efficient and can offer performance benefits, enabling sharing of insights between tasks. Nevertheless, they may require more training data, more complex hyperparameter tuning and careful balancing of the learning objectives ( Bastings et al., 2019 ; Chan A. et al., 2022 ). Finally, the choice depends on the specific requirements for model performance, the availability of training data, and the need for flexibility in model deployment and maintenance.
Since approaches have been trained and tested on different datasets using a variety of evaluation metrics, we have ranked them based on their reported performance on the MovieReviews ( Zaidan et al., 2007 ), SST ( Socher et al., 2013 ), and FEVER ( Thorne et al., 2018 ) datasets. Table 6 compares the performance of each rationalization approach in terms of its predictive performance and the quality of its produced rationales using sufficiency and comprehensiveness scores. Based on the results reported by the authors, we have categorized the predictive performance into: ✓✓✓—Very good performance, ✓✓—Good performance, and ✓— Performance has potential for improvement. What stands out in this table is the dominance of multi-task methods over pipelined and soft-score approaches in terms of predictive performance and explainability. Our summary shows that supervised multi-task extractive approaches are state-of-the-art for rationalization in terms of predictive performance and rationales' quality, followed by supervised multi-task text-to-text abstractive methods. We refer the reader to bf for details of each rationalization approach's performance.

Table 6 . Summary of the evaluation of each rationalization approach in terms of its predictive capability and the quality of its generated explanations.
Combining extractive and abstractive rationales for explainable text classification represents an innovative approach that harnesses the strengths of both: the direct, evidence-based clarity of extractive rationales and the comprehensive, context-rich insights of abstractive explanations. A recent study by Majumder et al. (2022) introduced RE x C (Extractive Rationales, Natural Language Explanations, and Commonsense), a rationalization framework that explains its prediction using a combination of extractive and abstractive language explanations. RE x C selects a subset of the input sequence as an extractive rationale using an encoder based on the HardKuma distribution ( Bastings et al., 2019 ), passes the selected snippets to a BART-based generator ( Lewis et al., 2020 ), and inputs the abstractive rationales to a decoder that outputs the final prediction. It is essential to highlight that all models are trained jointly, and the supervision comes from the target vectors and human-annotated explanations.
Beyond unimodal rationalization models for explainable text classification, multimodal explanations, which integrate textual, visual, and sometimes structured information, can provide more comprehensive insights into AI models' decision-making processes ( Park et al., 2018 ). Using this approach, Marasović et al. (2020) have produced abstractive rationales for visual reasoning tasks, such as visual-textual entailment, by combining pre-trained language models with object recognition classifiers to provide image understanding at the semantic and pragmatic levels. Along the same lines, Zhang et al. (2024) developed a vision language model to identify emotions in visual art and explain their prediction through abstractive rationales. Recent evidence suggests that multimodal explanations can allow for a deeper understanding of how different types of data can be analyzed to produce more accessible and intuitive explanations, broadening the scope and applicability of rationalization in real-world scenarios ( Chen and Zhao, 2022 ; Ananthram et al., 2023 ; Zhang et al., 2024 ).
5.2 Rationale-annotated data
Generating more rationale-annotated data is crucial for training and evaluating rationalization models, as it provides a rich, diverse foundation for teaching these models how to produce relevant and human-understandable explanations ( Doshi-Velez and Kim, 2017 ; Hase and Bansal, 2020 ). These data sets enhance the model's ability to generate accurate and more contextually appropriate rationales and facilitate more robust and comprehensive evaluation, improving the model's reliability and effectiveness in real-world applications. Even though there has been vast progress since the publication of ERASER ( DeYoung et al., 2020 ) and FEB ( Marasović et al., 2022 ) benchmarks, there is still a lack of rationale-annotated data for text classification. Considering that highlighting human rationales is not significantly more expensive than traditional labeling ( Zaidan et al., 2007 ), the NLP community could move toward methods for collecting labels by annotating rationales. By doing so, we could boost the results of classification and rationalization models ( Arous et al., 2021 ).
However, it is not enough to have more rationale-annotated data. We also need better human rationales. Standardizing methods for collecting rationale-annotated data is pivotal in the development of rationalization models, as it ensures a uniform approach to gathering and interpreting data, crucial for maintaining the quality and consistency of training and evaluation processes ( Wiegreffe et al., 2021 ; Yao et al., 2023 ). Documenting and reporting these procedures is equally important, providing transparency about how the data was annotated and allowing applicability in future research ( Atanasova et al., 2020 ; Li et al., 2021 ). Moreover, reporting and fostering the diversity of the annotators involved is critical. Diversity in demographics, expertise, and cognitive perspectives significantly shape machine-generated rationales ( Jakobsen et al., 2023 ). A comprehensive approach to data annotation is vital to advancing rationalization models that are reliable, effective and ethically sound in their explanations, catering to a broad spectrum of real-world applications and stakeholders.
Further work is needed to establish whether crafting datasets annotated with multimodal explanations can enrich the training and capabilities of rationalization approaches for explainable NLP. Even though preliminary results seem to indicate those visual and textual rationales can indeed provide explanatory strengths ( Chen and Zhao, 2022 ; Ananthram et al., 2023 ), one of the main challenges is the complexity involved in integrating diverse data types to ensure that annotations reflect the interconnectedness of these modalities ( Marasović et al., 2020 ). Moreover, developing robust annotation guidelines that capture the nuances of multimodal interactions is complex and requires interdisciplinary expertise ( Yuan et al., 2024 ; Zhang et al., 2024 ).
Since the reasoning process needed to infer a label is subjective and unstructured, we must develop dynamic, flexible and iterative strategies to collect human rationales ( Doshi-Velez and Kim, 2017 ). Considering that we aim to describe the decision-making process in real-world applications accurately, we could move toward noisy data labeling processes attempting to reflect the annotator's internal decision procedure. To illustrate, if annotators change their minds while highlighting rationales, dynamic approaches should be able to capture these changes so that we can learn from them ( Ehsan et al., 2019 ). This dynamic approach might allow for a more authentic and comprehensive representation of human cognitive processes, enriching the training and evaluation of rationalization models with insights that mirror the nature of real-world human thought and decision-making.
The use of human rationales has been key to the development of explainable text classification models. However, further research should focus on whether humans can provide explanations that can later be used to train rationalization models ( Miller, 2019 ; Tan, 2022 ). We need to acknowledge that human rationales, while a valid proxy mechanism, can only help us to understand the decision-making process of humans partially ( Amershi et al., 2014 ). Consequently, we encourage the NLP community to stop looking at them as another set of uniform labels and embrace their complexity by working collaboratively with researchers in other domains. For instance, to understand whether data sets of human explanations can serve their intended goals in real-world applications, we must connect the broad range of notions around human rationales in NLP with existing psychology and cognitive science literature. A more holistic understanding of human explanations should allow us to decide what kind of explanations are desired for NLP systems and help clarify how to generate and use them appropriately within their limitations.
5.3 Comprehensive rationale evaluation
While significant progress has been made in evaluating rationalization models, areas require improvement to ensure safer and more sustainable evaluation ( Lertvittayakumjorn and Toni, 2019 ; Carton et al., 2020 ). Even though current approaches offer valuable insights, there is a need for evaluation frameworks that can assess the suitability and usefulness of the rationales in diverse and complex real-world scenarios ( Chen H. et al., 2022 ; Hase and Bansal, 2022 ). Additionally, there is a growing need to focus on the ethical implications of rationale evaluation, particularly in sensitive applications ( Atanasova et al., 2023 ; Joshi et al., 2023 ). As a community of researchers and practitioners, we must ensure that the models do not inadvertently cause harm or perpetuate misinformation. Addressing these challenges requires a concerted effort from the XAI community to innovate and collaborate, paving the way for more reliable, fair, and transparent rationalization models in NLP.
We have provided a list of diagnostic properties for assessing rationales. It is important to note that these evaluation metrics have mainly been generated from a developer-based perspective, which has biased their results toward faithful explanations ( Lertvittayakumjorn and Toni, 2019 ; DeYoung et al., 2020 ). Current evaluation approaches are not designed nor implemented considering the perspective of other relevant stakeholders, such as investors, business executives, end-users, and policymakers, among many others. Further work must be done to evaluate rationale quality from a broader perspective, including practical issues that might arise in their implementation for real-world applications ( Tan, 2022 ).
Considering how important language explanations are for building trust with end-users ( Belle and Papantonis, 2021 ), their contribution should also be evaluated in the context of their specific application ( Doshi-Velez and Kim, 2017 ). A lack of domain-specific annotated data is detrimental to developing explainable models for high-stake sectors such as the legal, medical and humanitarian domains ( Jacovi and Goldberg, 2021 ; Mendez et al., 2022 ). As mentioned before, current evaluation methods lack interactivity ( Carton et al., 2020 ). End users or domain experts cannot contest rationales or ask the models to explain them differently, which makes them impossible to validate and deploy in real-world applications. Even though it is beyond the scope of our survey, work needs to be done to develop clear, concise and user-friendly ways of presenting rationales as part of explainable NLP systems ( Hartmann and Sonntag, 2022 ; Tan, 2022 ). Effectively communicated rationales boost user trust and confidence in the system and facilitate a deeper comprehension of the model's decision-making process, leading to more informed and effective use of NLP models.
6 Conclusions
Developing understandable and trustworthy systems becomes paramount as NLP and text classification applications continue to integrate into critical and sensitive applications. The present survey article aimed to examine rationalization approaches and their evaluation metrics for explainable text classification, providing a comprehensive entry point for new researchers and practitioners in the field.
The contrast between extractive and abstractive rationalization highlights distinct strengths and limitations. On the one hand, extractive rationalization approaches link to original data, ensuring reliability and ease of validation. However, they may lack the context or comprehensive insight needed for decision-making. On the other hand, abstractive rationalization models offer the flexibility to produce more intuitive and human-like explanations, which enhance user usability and trust. Nevertheless, they face challenges such as the potential for generating non-factual explanations and the complexity of maintaining plausibility in the decision-making process. Choosing between extractive and abstractive models depends on application-specific needs: extractive models are preferable where direct traceability is crucial, such as legal applications. In contrast, abstractive models are suited for situations requiring broader contextual interpretations.
Despite its challenging nature, the emerging work on rationalization for explainable text classification is promising. Nevertheless, several questions remain to be answered. Further research is required to better understand human rationales, establish procedures for collecting them, and develop accurate and feasible methods for generating and evaluating rationales in real-world applications. We have identified possible directions for future research, which will hopefully extend the work achieved so far.
Author contributions
EM: Conceptualization, Investigation, Methodology, Validation, Visualization, Writing – original draft, Writing – review & editing. VS: Conceptualization, Supervision, Writing – review & editing. RB-N: Conceptualization, Supervision, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was supported by the Chilean National Agency for Research and Development (Scholarship ID 720210003), whose contribution was essential in conducting this research.
Conflict of interest
VS was employed at ASUS Intelligent Cloud Services.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Aggarwal, C. C., and Zhai, C. (2012). “A survey of text classification algorithms,” in Mining Text Data (Boston, MA: Springer), 163–222. doi: 10.1007/978-1-4614-3223-4_6
Crossref Full Text | Google Scholar
Amershi, S., Cakmak, M., Knox, W. B., and Kulesza, T. (2014). Power to the people: the role of humans in interactive machine learning. Ai Mag . 35, 105–120. doi: 10.1609/aimag.v35i4.2513
Ananthram, A., Winn, O., and Muresan, S. (2023). Feelingblue: a corpus for understanding the emotional connotation of color in context. Trans. Assoc. Comput. Linguist . 11, 176–190. doi: 10.1162/tacl_a_00540
Arous, I., Dolamic, L., Yang, J., Bhardwaj, A., Cuccu, G., and Cudré-Mauroux, P. (2021). “Marta: leveraging human rationales for explainable text classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35 (Burnaby, BC: PKP PS), 5868–5876.
Google Scholar
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., et al. (2020). Explainable artificial intelligence (XAI): concepts, taxonomies, opportunities and challenges toward responsible AI. Inform. Fus . 58, 82–115. doi: 10.1016/j.inffus.2019.12.012
Atanasova, P., Camburu, O. M., Lioma, C., Lukasiewicz, T., Simonsen, J. G., and Augenstein, I. (2023). “Faithfulness tests for natural language explanations,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (Toronto, ON: Association for Computational Linguistics), 283–294.
Atanasova, P., Simonsen, J. G., Lioma, C., and Augenstein, I. (2020). “Generating fact checking explanations,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Springer Nature Switzerland), 7352–7364.
Atanasova, P., Simonsen, J. G., Lioma, C., and Augenstein, I. (2024). “A diagnostic study of explainability techniques for text classification,” in Accountable and Explainable Methods for Complex Reasoning over Text (Springer Nature Switzerland), 155–187.
PubMed Abstract | Google Scholar
Bahdanau, D., Cho, K., and Bengio, Y. (2015). “Neural machine translation by jointly learning to align and translate,” in 3rd International Conference on Learning Representations, ICLR 2015 .
Bao, Y., Chang, S., Yu, M., and Barzilay, R. (2018). “Deriving machine attention from human rationales,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (Brussels: Association for Computational Linguistics), 1903–1913.
Bashier, H. K., Kim, M. Y., and Goebel, R. (2020). “RANCC: rationalizing neural networks via concept clustering,” in Proceedings of the 28th International Conference on Computational Linguistics (Barcelona: International Committee on Computational Linguistics), 3214–3224.
Bastings, J., Aziz, W., and Titov, I. (2019). “Interpretable neural predictions with differentiable binary variables,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Florence: ACL Anthology), 2963–2977.
Bastings, J., and Filippova, K. (2020). “The elephant in the interpretability room: why use attention as explanation when we have saliency methods?,” in Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP (Association for Computational Linguistics), 149–155.
Belle, V., and Papantonis, I. (2021). Principles and practice of explainable machine learning. Front. Big Data 4:688969. doi: 10.3389/fdata.2021.688969
PubMed Abstract | Crossref Full Text | Google Scholar
Bhat, M. M., Sordoni, A., and Mukherjee, S. (2021). Self-training with few-shot rationalization: teacher explanations aid student in few-shot NLU. arXiv preprint arXiv:2109.08259 . doi: 10.48550/arXiv.2109.08259
Bibal, A., Lognoul, M., De Streel, A., and Frénay, B. (2021). Legal requirements on explainability in machine learning. Artif. Intell. Law 29, 149–169. doi: 10.1007/s10506-020-09270-4
Blitzer, J., Dredze, M., and Pereira, F. (2007). “Biographies, bollywood, boom-boxes and blenders: domain adaptation for sentiment classification,” in Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics (Prague: Association for Computational Linguistics), 440–447.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., et al. (2020). Language models are few-shot learners. Adv. Neural Inform. Process. Syst . 33, 1877–1901. doi: 10.48550/arXiv.2005.14165
Burkart, N., and Huber, M. F. (2021). A survey on the explainability of supervised machine learning. J. Artif. Intell. Res . 70, 245–317. doi: 10.48550/arXiv.2011.07876
Camburu, O.-M., Rocktäschel, T., Lukasiewicz, T., and Blunsom, P. (2018). e-SNLI: natural language inference with natural language explanations. Adv. Neural Inform. Process. Syst . 31:1193. doi: 10.48550/arXiv.1812.01193
Camburu, O. M., Shillingford, B., Minervini, P., Lukasiewicz, T., and Blunsom, P. (2020). “Make up your mind! adversarial generation of inconsistent natural language explanations,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics), 4157–4165.
Carton, S., Mei, Q., and Resnick, P. (2018). “Extractive adversarial networks: high-recall explanations for identifying personal attacks in social media posts,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (Brussels: Association for Computational Linguistics), 3497–3507.
Carton, S., Rathore, A., and Tan, C. (2020). “Evaluating and characterizing human rationales,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Association for Computational Linguistics), 9294–9307.
Chan, A., Sanjabi, M., Mathias, L., Tan, L., Nie, S., Peng, X., et al. (2022). “UNIREX: a unified learning framework for language model rationale extraction,” in International Conference on Machine Learning (Baltimore, MD: PMLR), 2867–2889.
Chang, S., Zhang, Y., Yu, M., and Jaakkola, T. (2019). A game theoretic approach to class-wise selective rationalization. Adv. Neural Inform. Process. Syst . 32:12853. doi: 10.48550/arXiv.1910.12853
Chen, H., He, J., Narasimhan, K., and Chen, D. (2022). “Can rationalization improve robustness?,” in 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022 (Seattle, WA: Association for Computational Linguistics (ACL)), 3792–3805.
Chen, H., Zheng, G., and Ji, Y. (2020). “Generating hierarchical explanations on text classification via feature interaction detection,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 5578–5593.
Chen, S., and Zhao, Q. (2022). “REX: reasoning-aware and grounded explanation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (New Orleans, LA: IEEE), 15586–15595.
Chen, W. L., Yen, A. Z., Huang, H. H., Wu, C. K., and Chen, H. H. (2023). “ZARA: improving few-shot self-rationalization for small language models,” in Findings of the Association for Computational Linguistics: EMNLP 2023 (Singapore: Association for Computational Linguistics), 4682–4693.
Chrysostomou, G., and Aletras, N. (2022). “Flexible instance-specific rationalization of NLP models,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36 (Burnaby, BC: PKP PS), 10545–10553.
Danilevsky, M., Qian, K., Aharonov, R., Katsis, Y., Kawas, B., and Sen, P. (2020). “A survey of the state of explainable AI for natural language processing,” in Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing (Suzhou: Association for Computational Linguistics), 447–459.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT (Minneapolis, MN: Association for Computational Linguistics), 4171–4186.
DeYoung, J., Jain, S., Rajani, N. F., Lehman, E., Xiong, C., Socher, R., et al. (2020). “ERASER: a benchmark to evaluate rationalized NLP models,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics), 4443–4458.
Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., et al. (2019). Unified language model pre-training for natural language understanding and generation. Adv. Neural Inform. Process. Syst . 32:3197. doi: 10.48550/arXiv.1905.03197
Doshi-Velez, F., and Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608 . doi: 10.48550/arXiv.1702.08608
Ehsan, U., Tambwekar, P., Chan, L., Harrison, B., and Riedl, M. O. (2019). “Automated rationale generation: a technique for explainable AI and its effects on human perceptions,” in Proceedings of the 24th International Conference on Intelligent User Interfaces (Association for Computing Machinery), 263–274.
Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., and Kagal, L. (2018). “Explaining explanations: an overview of interpretability of machine learning,” in 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA) (Turin: IEEE), 80–89.
Guerreiro, N. M., and Martins, A. F. (2021). “SECTRA: sparse structured text rationalization,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Punta Cana: Association for Computational Linguistics), 6534–6550.
Gunning, D., Stefik, M., Choi, J., Miller, T., Stumpf, S., and Yang, G.-Z. (2019). Xai–explainable artificial intelligence. Sci. Robot . 4:37. doi: 10.1126/scirobotics.aay7120
Gurrapu, S., Huang, L., and Batarseh, F. A. (2022). “EXCLAIM: explainable neural claim verification using rationalization,” in 2022 IEEE 29th Annual Software Technology Conference (STC) (IEEE), 19–26.
Gurrapu, S., Kulkarni, A., Huang, L., Lourentzou, I., and Batarseh, F. A. (2023). Rationalization for explainable NLP: a survey. Front. Artif. Intell . 6:1225093. doi: 10.3389/frai.2023.1225093
Guyon, I., Cawley, G. C., Dror, G., and Lemaire, V. (2011). “Results of the active learning challenge,” in Active Learning and Experimental Design Workshop in Conjunction With AISTATS 2010. JMLR Workshop and Conference Proceedings (Sardinia), 19–45.
Hanselowski, A., Stab, C., Schulz, C., Li, Z., and Gurevych, I. (2019). “A richly annotated corpus for different tasks in automated fact-checking,” in Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL) (Hong Kong: Association for Computational Linguistics), 493–503.
Hartmann, M., and Sonntag, D. (2022). “A survey on improving NLP models with human explanations,” in ACL Workshop on Learning with Natural Language Supervision (Dublin: Association for Computational Linguistics).
Hase, P., and Bansal, M. (2020). “Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior?” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics), 5540–5552.
Hase, P., and Bansal, M. (2022). “When can models learn from explanations? A formal framework for understanding the roles of explanation data,” in Proceedings of the First Workshop on Learning with Natural Language Supervision (Dublin: Association for Computational Linguistics), 29–39.
Hase, P., Zhang, S., Xie, H., and Bansal, M. (2020). “Leakage-adjusted simulatability: can models generate non-trivial explanations of their behavior in natural language?” in Findings of the Association for Computational Linguistics: EMNLP 2020 (Association for Computational Linguistics), 4351–4367.
Hayati, S. A., Kang, D., and Ungar, L. (2021). “Does bert learn as humans perceive? Understanding linguistic styles through lexica,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Punta Cana: Association for Computational Linguistics), 6323–6331.
He, P., Liu, X., Gao, J., and Chen, W. (2020). “DEBERTA: decoding-enhanced bert with disentangled attention,” in International Conference on Learning Representations (Vienna: ICLR).
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput . 9, 1735–1780.
Jacovi, A., and Goldberg, Y. (2021). Aligning faithful interpretations with their social attribution. Trans. Assoc. Comput. Linguist . 9, 294–310. doi: 10.48550/arXiv.2006.01067
Jain, S., and Wallace, B. C. (2019). “Attention is not explanation,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (Minneapolis, MN: Association for Computational Linguistics), 3543–3556.
Jain, S., Wiegreffe, S., Pinter, Y., and Wallace, B. C. (2020). “Learning to faithfully rationalize by construction,” in 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020 (Association for Computational Linguistics), 4459–4473.
Jakobsen, T. S. T., Cabello, L., and Søgaard, A. (2023). “Being right for whose right reasons?” in The 61st Annual Meeting Of The Association For Computational Linguistics (Toronto, ON: Association for Computational Linguistics).
Jang, M., and Lukasiewicz, T. (2021). Are training resources insufficient? Predict first then explain! arXiv preprint arXiv:2110.02056 . doi: 10.48550/arXiv.2110.02056
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., et al. (2023). Survey of hallucination in natural language generation. ACM Comput. Surv . 55, 1–38. doi: 10.1145/3571730
Jiang, H., Duan, J., Qu, Z., and Wang, J. (2023). You only forward once: prediction and rationalization in a single forward pass. arXiv preprint arXiv:2311.02344 . doi: 10.48550/arXiv.2311.02344
Jiang, X., Ye, H., Luo, Z., Chao, W., and Ma, W. (2018). “Interpretable rationale augmented charge prediction system,” in Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations (Santa Fe: Association for Computational Linguistics), 146–151.
Joshi, B., Liu, Z., Ramnath, S., Chan, A., Tong, Z., Nie, S., et al. (2023). “Are machine rationales (not) useful to humans? Measuring and improving human utility of free-text rationales,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Toronto, ON: Association for Computational Linguistics), 7103–7128.
Kanchinadam, T., Westpfahl, K., You, Q., and Fung, G. (2020). “Rationale-based human-in-the-loop via supervised attention,” in DaSH@ KDD (Association for Computing Machinery).
Kandul, S., Micheli, V., Beck, J., Kneer, M., Burri, T., Fleuret, F., et al. (2023). Explainable AI: A Review of the Empirical Literature . SSRN.
Kowsari, K., Jafari Meimandi, K., Heidarysafa, M., Mendu, S., Barnes, L., and Brown, D. (2019). Text classification algorithms: a survey. Information 10:150. doi: 10.48550/arXiv.1904.08067
Kumar, S., and Talukdar, P. (2020). “NILE : natural language inference with faithful natural language explanations,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 8730–8742.
Kung, P. N., Yang, T. H., Chen, Y. C., Yin, S. S., and Chen, Y. N. (2020). “Zero-shot rationalization by multi-task transfer learning from question answering,” in Findings of the Association for Computational Linguistics: EMNLP 2020 (Association for Computational Linguistics), 2187–2197.
Kunz, J., Jirenius, M., Holmström, O., and Kuhlmann, M. (2022). “Human ratings do not reflect downstream utility: a study of free-text explanations for model predictions,” in Proceedings of the Fifth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP (Abu Dhabi: Association for Computational Linguistics), 164–177.
Lai, S., Xu, L., Liu, K., and Zhao, J. (2015). “Recurrent convolutional neural networks for text classification,” in Twenty-Ninth AAAI Conference on Artificial Intelligence (Burnaby, BC: PKP PS).
Lakhotia, K., Paranjape, B., Ghoshal, A., Yih, W. T., Mehdad, Y., and Iyer, S. (2021). “FID-EX: improving sequence-to-sequence models for extractive rationale generation,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Association for Computational Linguistics), 3712–3727.
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., and Soricut, R. (2019). “ALBERT: a lite bert for self-supervised learning of language representations,” in International Conference on Learning Representations (Addis Ababa: ICLR).
Lei, T. (2017). Interpretable Neural Models for Natural Language Processing (Ph.D. thesis). Massachusetts Institute of Technology, Cambridge, MA, United States.
Lei, T., Barzilay, R., and Jaakkola, T. (2016). “Rationalizing neural predictions,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (Austin, TX: Association for Computational Linguistics), 107–117.
Lertvittayakumjorn, P., and Toni, F. (2019). “Human-grounded evaluations of explanation methods for text classification,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (Hong Kong: Association for Computational Linguistics), 5195–5205.
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., et al. (2020). “BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 7871–7880.
Li, D., Tao, J., Chen, Q., and Hu, B. (2021). You can do better! If you elaborate the reason when making prediction. arXiv preprint arXiv:2103.14919 . doi: 10.48550/arXiv.2103.14919
Liang, H., He, E., Zhao, Y., Jia, Z., and Li, H. (2022). Adversarial attack and defense: a survey. Electronics 11:1283. doi: 10.48550/arXiv.1810.00069
Liu, H., Yin, Q., and Wang, W. Y. (2019a). “Towards explainable NLP: a generative explanation framework for text classification,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , 5570–5581.
Liu, W., Wang, H., Wang, J., Li, R., Li, X., Zhang, Y., et al. (2023). “MGR: multi-generator based rationalization,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Toronto, ON: Association for Computational Linguistics), 12771–12787.
Liu, W., Wang, H., Wang, J., Li, R., Yue, C., and Zhang, Y. (2022). FR: folded rationalization with a unified encoder. Adv. Neural Inform. Process. Syst . 35, 6954–6966. doi: 10.48550/arXiv.2209.08285
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., et al. (2019b). RoBERTa: a robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 . doi: 10.48550/arXiv.1907.11692
Lundberg, S. M., and Lee, S. I. (2017). A unified approach to interpreting model predictions. Adv. Neural Inform. Process. Syst . 30:7874. doi: 10.48550/arXiv.1705.07874
Lyu, Q., Apidianaki, M., and Callison-Burch, C. (2024). Towards faithful model explanation in NLP: a survey. Comput. Linguist . 2024, 1–70. doi: 10.48550/arXiv.2209.11326
Lyu, Q., Zhang, H., Sulem, E., and Roth, D. (2021). “Zero-shot event extraction via transfer learning: challenges and insights,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) (Association for Computational Linguistics), 322–332.
Maas, A., Daly, R. E., Pham, P. T., Huang, D., Ng, A. Y., and Potts, C. (2011). “Learning word vectors for sentiment analysis,” in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (Portland: Association for Computational Linguistics), 142–150.
Madani, M. R. G., and Minervini, P. (2023). “REFER: an end-to-end rationale extraction framework for explanation regularization,” in Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) (Singapore: Association for Computational Linguistics), 587–602.
Madsen, A., Reddy, S., and Chandar, S. (2022). Post-hoc interpretability for neural NLP: a survey. ACM Comput. Surv . 55, 1–42. doi: 10.1145/3546577
Mahoney, C., Gronvall, P., Huber-Fliflet, N., and Zhang, J. (2022). “Explainable text classification techniques in legal document review: locating rationales without using human annotated training text snippets,” in 2022 IEEE International Conference on Big Data (Big Data) (Osaka: IEEE), 2044–2051.
Majumder, B. P., Camburu, O., Lukasiewicz, T., and Mcauley, J. (2022). “Knowledge-grounded self-rationalization via extractive and natural language explanations,” in International Conference on Machine Learning (Baltimore, MD: PMLR), 14786–14801.
Marasović, A., Beltagy, I., Downey, D., and Peters, M. E. (2022). “Few-shot self-rationalization with natural language prompts,” in Findings of the Association for Computational Linguistics: NAACL 2022 (Seattle, WA: Association for Computational Linguistics), 410–424.
Marasović, A., Bhagavatula, C., Park, J. S., Bras, R. L., Smith, N. A., and Choi, Y. (2020). “Natural Language Rationales With Full-Stack Visual Reasoning: From Pixels to Semantic Frames to Commonsense Graphs,” in Findings of the Association for Computational Linguistics: EMNLP 2020 (Association for Computational Linguistics), 2810–2829.
Mathew, B., Saha, P., Yimam, S. M., Biemann, C., Goyal, P., and Mukherjee, A. (2021). HateXplain: a benchmark dataset for explainable hate speech detection. arXiv . 35, 14867–14875. doi: 10.48550/arXiv.2012.10289
McAuley, J., Leskovec, J., and Jurafsky, D. (2012). “Learning attitudes and attributes from multi-aspect reviews,” in 2012 IEEE 12th International Conference on Data Mining (Brussels: IEEE), 1020–1025.
Mendez, E., Schlegel, V., and Batista-Navarro, R. (2022). “RaFoLa: a rationale-annotated corpus for detecting indicators of forced labour,” in Proceedings of the Thirteenth Language Resources and Evaluation Conference , eds. N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, et al. (Marseille: European Language Resources Association), 3610–3625.
Meng, Y., Huang, J., Zhang, Y., and Han, J. (2022). Generating training data with language models: towards zero-shot language understanding. Adv. Neural Inform. Process. Syst . 35, 462–477. doi: 10.48550/arXiv.2202.04538
Miller, T. (2019). Explanation in artificial intelligence: insights from the social sciences. Artif. Intell . 267, 1–38. doi: 10.1016/j.artint.2018.07.007
Minervini, P., Franceschi, L., and Niepert, M. (2023). “Adaptive perturbation-based gradient estimation for discrete latent variable models,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37 (Burnaby, BC: PKP PS), 9200–9208.
Mohseni, S., Block, J. E., and Ragan, E. D. (2018). A human-grounded evaluation benchmark for local explanations of machine learning. arXiv preprint arXiv:1801.05075 . doi: 10.48550/arXiv.1801.05075
Mukherjee, S. (2019). General information bottleneck objectives and their applications to machine learning. arXiv preprint arXiv:1912.06248 . doi: 10.48550/arXiv.1912.06248
Narang, S., Raffel, C., Lee, K., Roberts, A., Fiedel, N., and Malkan, K. (2020). WT5?! training text-to-text models to explain their predictions. arXiv preprint arXiv:2004.14546 . doi: 10.48550/arXiv.2004.14546
Niculae, V., and Martins, A. (2020). LP-SparseMAP: differentiable relaxed optimization for sparse structured prediction. In International Conference on Machine Learning (Baltimore, MD: PMLR), 7348–7359.
Niu, Z., Zhong, G., and Yu, H. (2021). A review on the attention mechanism of deep learning. Neurocomputing 452, 48–62. doi: 10.1016/j.neucom.2021.03.091
Otter, D. W., Medina, J. R., and Kalita, J. K. (2020). A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst . 32, 604–624. doi: 10.1109/TNNLS.2020.2979670
Palmer, J., Kreutz-Delgado, K., Rao, B., and Wipf, D. (2005). Variational em algorithms for non-gaussian latent variable models. Adv. Neural Inform. Process. Syst . 2005:18.
Paranjape, B., Joshi, M., Thickstun, J., Hajishirzi, H., and Zettlemoyer, L. (2020). “An information bottleneck approach for controlling conciseness in rationale extraction,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Association for Computational Linguistics).
Park, D. H., Hendricks, L. A., Akata, Z., Rohrbach, A., Schiele, B., Darrell, T., et al. (2018). “Multimodal explanations: Justifying decisions and pointing to the evidence,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Salt Lake City, UT: IEEE), 8779–8788.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. (2019). Language models are unsupervised multitask learners. OpenAI Blog 1:9.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res . 21, 1–67. doi: 10.48550/arXiv.1910.10683
Rajani, N. F., McCann, B., Xiong, C., and Socher, R. (2019). “Explain yourself! leveraging language models for commonsense reasoning,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Florence: Association for Computational Linguistics), 4932–4942.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016a). “Why should i trust you?” explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY: Association for Computing Machinery), 1135–1144.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016b). Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386 . doi: 10.48550/arXiv.1606.05386
Ross, A., Peters, M. E., and Marasović, A. (2022). “Does self-rationalization improve robustness to spurious correlations?” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (Florence: Association for Computational Linguistics), 7403–7416.
Sen, C., Hartvigsen, T., Yin, B., Kong, X., and Rundensteiner, E. (2020). “Human attention maps for text classification: do humans and neural networks focus on the same words?” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics), 4596–4608.
Simonyan, K., Vedaldi, A., and Zisserman, A. (2014). “Deep inside convolutional networks: visualising image classification models and saliency maps,” in Proceedings of the International Conference on Learning Representations (ICLR) (Banff, AB: ICLR).
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., et al. (2013). “Recursive deep models for semantic compositionality over a sentiment treebank,” in Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (Seattle, WA: Association for Computational Linguistics), 1631–1642.
Strout, J., Zhang, Y., and Mooney, R. J. (2019). “Do human rationales improve machine explanations?” in Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP (Florence: Association for Computational Linguistics), 56–62.
Sundararajan, M., Taly, A., and Yan, Q. (2017). “Axiomatic attribution for deep networks,” in International Conference on Machine Learning (Sydney, NSW: PMLR), 3319–3328.
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to sequence learning with neural networks. Adv. Neural Inform. Process. Syst . 27:3215. doi: 10.48550/arXiv.1409.3215
Tan, C. (2022). “On the diversity and limits of human explanations,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Seattle, WA: Association for Computational Linguistics).
Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mittal, A. (2018). “Fever: a large-scale dataset for fact extraction and verification,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (New Orleans, LA: Association for Computational Linguistics), 809–819.
Tjoa, E., and Guan, C. (2020). A survey on explainable artificial intelligence (XAI): toward medical XAI. IEEE Trans. Neural Netw. Learn. Syst . 32, 4793–4813. doi: 10.48550/arXiv.1907.07374
Tornqvist, M., Mahamud, M., Guzman, E. M., and Farazouli, A. (2023). “EXASAG: explainable framework for automatic short answer grading,” in Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) (Toronto, ON: Association for Computational Linguistics), 361–371.
Vashishth, S., Upadhyay, S., Tomar, G. S., and Faruqui, M. (2019). Attention interpretability across NLP tasks. arXiv preprint arXiv:1909.11218 . doi: 10.48550/arXiv.1909.11218
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. Adv. Neural Inform. Process. Syst . 30:3762. doi: 10.48550/arXiv.1706.03762
Vijayan, V. K., Bindu, K., and Parameswaran, L. (2017). “A comprehensive study of text classification algorithms,” in 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI) (Udupi: IEEE), 1109–1113.
Wang, H., and Dou, Y. (2022). “Recent development on extractive rationale for model interpretability: a survey,” in 2022 International Conference on Cloud Computing, Big Data and Internet of Things (3CBIT) (Wuhan: IEEE), 354–358.
Wang, H., Lu, Y., and Zhai, C. (2010). “Latent aspect rating analysis on review text data: a rating regression approach,” in Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 783–792.
Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., et al. (2021). “Finetuned language models are zero-shot learners,” in International Conference on Learning Representations (ICLR).
Wiegreffe, S., and Marasović, A. (2021). “Teach me to explain: a review of datasets for explainable natural language processing,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) (NeurIPS).
Wiegreffe, S., Marasović, A., and Smith, N. A. (2021). “Measuring association between labels and free-text rationales,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Punta Cana: Association for Computational Linguistics), 10266–10284.
Wiegreffe, S., and Pinter, Y. (2019). “Attention is not explanation,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (Hong Kong: Association for Computational Linguistics), 11–20.
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learn . 8, 229–256.
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., et al. (2021). “MT5: a massively multilingual pre-trained text-to-text transformer,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Association for Computational Linguistics), 483–498.
Yao, B., Sen, P., Popa, L., Hendler, J., and Wang, D. (2023). “Are human explanations always helpful? Towards objective evaluation of human natural language explanations,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Toronto, ON: Association for Computational Linguistics), 14698–14713.
Yu, M., Chang, S., Zhang, Y., and Jaakkola, T. S. (2019). “Rethinking cooperative rationalization: introspective extraction and complement control,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , 4094–4103.
Yuan, J., Sun, S., Omeiza, D., Zhao, B., Newman, P., Kunze, L., et al. (2024). RAG-Driver: generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model. arXiv preprint arXiv:2402.10828 . doi: 10.48550/arXiv.2402.10828
Zaidan, O., Eisner, J., and Piatko, C. (2007). “Using “annotator rationales” to improve machine learning for text categorization,” in Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference (Rochester, NY: Association for Computational Linguistics), 260–267.
Zeiler, M. D., and Fergus, R. (2014). “Visualizing and understanding convolutional networks,” in European Conference on Computer Vision (Berlin: Springer), 818–833.
Zhang, D., Sen, C., Thadajarassiri, J., Hartvigsen, T., Kong, X., and Rundensteiner, E. (2021a). “Human-like explanation for text classification with limited attention supervision,” in 2021 IEEE International Conference on Big Data (Orlando, FL: IEEE), 957–967.
Zhang, J., Kim, J., O'Donoghue, B., and Boyd, S. (2021b). “Sample efficient reinforcement learning with reinforce,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35 , 10887–10895.
Zhang, J., Zheng, L., Guo, D., and Wang, M. (2024). Training a small emotional vision language model for visual art comprehension. arXiv preprint arXiv:2403.11150 . doi: 10.48550/arXiv.2403.11150
Zhang, W. E., Sheng, Q. Z., Alhazmi, A., and Li, C. (2020). Adversarial attacks on deep-learning models in natural language processing: a survey. ACM Trans. Intell. Syst. Technol . 11, 1–41. doi: 10.1145/3374217
Zhang, Y., Marshall, I., and Wallace, B. C. (2016). “Rationale-augmented convolutional neural networks for text classification,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, Vol. 2016 (NIH Public Access), 795.
Zhao, H., Chen, H., Yang, F., Liu, N., Deng, H., Cai, H., et al. (2023). Explainability for large language models: a survey. ACM Trans. Intell. Syst. Technol . 2023:1029. doi: 10.48550/arXiv.2309.01029
Zhao, X., and Vydiswaran, V. V. (2021). “LIREX: augmenting language inference with relevant explanations,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35 , 14532–14539.
Zhou, W., Hu, J., Zhang, H., Liang, X., Sun, M., Xiong, C., et al. (2020). Towards interpretable natural language understanding with explanations as latent variables. Adv. Neural Inform. Process. Syst . 33, 6803–6814. doi: 10.48550/arXiv.2011.05268
Zhou, Y., Zhang, Y., and Tan, C. (2023). “FLAME: few-shot learning from natural language explanations,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Toronto, ON: Association for Computational Linguistics), 6743–6763.
Zini, J. E., and Awad, M. (2022). On the explainability of natural language processing deep models. ACM Comput. Surv . 55, 1–31. doi: 10.1145/3529755
Performance of rationalization approaches
Table A1 presents the breakdown results for rationalization approaches according to what has been reported for each author on the MovieReviews ( Zaidan et al., 2007 ), SST ( Socher et al., 2013 ), and the FEVER ( Thorne et al., 2018 ) datasets. The predictive performance is evaluated using the F1 Score (F1), and the quality of the produced rationales is assessed using Sufficiency (Suff) and Comprehensiveness (Comp).

Table A1 . Performance of different rationalization approaches on the MovieReviews, SST, and FEVER datasets.
Keywords: Natural Language Processing, text classification, Explainable Artificial Intelligence, rationalization, language explanations
Citation: Mendez Guzman E, Schlegel V and Batista-Navarro R (2024) From outputs to insights: a survey of rationalization approaches for explainable text classification. Front. Artif. Intell. 7:1363531. doi: 10.3389/frai.2024.1363531
Received: 30 December 2023; Accepted: 02 July 2024; Published: 23 July 2024.
Reviewed by:
Copyright © 2024 Mendez Guzman, Schlegel and Batista-Navarro. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Erick Mendez Guzman, erick.mendezguzman@manchester.ac.uk
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Grab your spot at the free arXiv Accessibility Forum
Help | Advanced Search
Computer Science > Artificial Intelligence
Title: the dangers in algorithms learning humans' values and irrationalities.
Abstract: For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and then optimising for these irrationalities. Simply learning human values still carries risks: AI learning them will inevitably also gain information on human irrationalities and human behaviour/policy. Both of these can be dangerous: knowing human policy allows an AI to become generically more powerful (whether it is partially aligned or not aligned at all), while learning human irrationalities allows it to exploit humans without needing to provide value in return. This paper analyses the danger in developing artificial intelligence that learns about human irrationalities and human policy, and constructs a model recommendation system with various levels of information about human biases, human policy, and human values. It concludes that, whatever the power and knowledge of the AI, it is more dangerous for it to know human irrationalities than human values. Thus it is better for the AI to learn human values directly, rather than learning human biases and then deducing values from behaviour.
| Subjects: | Artificial Intelligence (cs.AI) |
| Cite as: | [cs.AI] |
| (or [cs.AI] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite |
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
ChatGPT as an automated essay scoring tool in the writing classrooms: how it compares with human scoring
- Published: 13 July 2024
Cite this article

- Ngoc My Bui 1 &
- Jessie S. Barrot ORCID: orcid.org/0000-0001-8517-4058 1 , 2
241 Accesses
8 Altmetric
Explore all metrics
With the generative artificial intelligence (AI) tool’s remarkable capabilities in understanding and generating meaningful content, intriguing questions have been raised about its potential as an automated essay scoring (AES) system. One such tool is ChatGPT, which is capable of scoring any written work based on predefined criteria. However, limited information is available about the reliability of this tool in scoring the different dimensions of writing quality. Thus, this study examines the relationship between the scores assigned by ChatGPT and a human rater and how consistent ChatGPT-assigned scores are when taken at multiple time points. This study employed a cross-sectional quantitative approach in analyzing 50 argumentative essays from each proficiency level (A2_0, B1_1, B1_2, and B2_0), totaling 200. These essays were rated by ChatGPT and an experienced human rater. Using correlational analysis, the results reveal that ChatGPT’s scoring did not align closely with an experienced human rater (i.e., weak to moderate relationships) and failed to establish consistency after two rounds of scoring (i.e., low intraclass correlation coefficient values). These results were primarily attributed to ChatGPT’s scoring algorithm, training data, model updates, and inherent randomness. Implications for writing assessment and future studies are discussed.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or Ebook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

A large-scale comparison of human-written versus ChatGPT-generated essays

Exploratory study on the potential of ChatGPT as a rater of second language writing

ChatGPT-3.5 as writing assistance in students’ essays
Data availability.
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Almusharraf, N., & Alotaibi, H. (2023). An error-analysis study from an EFL writing context: Human and automated essay scoring approaches. Technology Knowledge and Learning, 28 (3), 1015–1031.
Article Google Scholar
An, X., Chai, C. S., Li, Y., Zhou, Y., & Yang, B. (2023). Modeling students’ perceptions of artificial intelligence assisted language learning. Computer Assisted Language Learning . https://doi.org/10.1080/09588221.2023.2246519 . Advance online publication.
Athanassopoulos, S., Manoli, P., Gouvi, M., Lavidas, K., & Komis, V. (2023). The use of ChatGPT as a learning tool to improve foreign language writing in a multilingual and multicultural classroom. Advances in Mobile Learning Educational Research, 3 (2), 818–824.
Barrot, J. S. (2023). Using ChatGPT for second language writing: Pitfalls and potentials. Assessing Writing, 57 , 100745.
Barrot, J. S. (2024a). Trends in automated writing evaluation systems research for teaching, learning, and assessment: A bibliometric analysis. Education and Information Technologies, 29 (6), 7155–7179.
Barrot, J. S. (2024b). ChatGPT as a language learning tool: An emerging technology report. Technology, Knowledge and Learning, 29 , 1151–1156.
Beseiso, M., Alzubi, O. A., & Rashaideh, H. (2021). A novel automated essay scoring approach for reliable higher educational assessments. Journal of Computing in Higher Education, 33 , 727–746.
Dergaa, I., Chamari, K., Zmijewski, P., & Saad, H. B. (2023). From human writing to artificial intelligence generated text: Examining the prospects and potential threats of ChatGPT in academic writing. Biology of Sport, 40 (2), 615–622.
Dikli, S., & Bleyle, S. (2014). Automated essay scoring feedback for second language writers: How does it compare to instructor feedback? Assessing Writing, 22 , 1–17.
Gonzalez Torres, A. P., & Sawhney, N. (2023). Role of regulatory sandboxes and MLOps for AI-enabled public sector services. The Review of Socionetwork Strategies, 17 , 297–318.
Guo, K., & Wang, D. (2024). To resist it or to embrace it? Examining ChatGPT’s potential to support teacher feedback in EFL writing. Education and Information Technologies, 29 , 8435–8463.
Han, T., & Sari, E. (2024). An investigation on the use of automated feedback in Turkish EFL students’ writing classes. Computer Assisted Language Learning, 37 (4), 961–985.
Higgins, D., & Heilman, M. (2014). Managing what we can measure: Quantifying the susceptibility of automated scoring systems to gaming behavior. Educational Measurement: Issues and Practice, 33 (3), 36–46.
Hussein, M. A., Hassan, H., & Nassef, M. (2019). Automated language essay scoring systems: A literature review. PeerJ Computer Science, 5 , e208.
Ishikawa, S. (2013). The ICNALE and sophisticated contrastive interlanguage analysis of Asian learners of English. Learner Corpus Studies in Asia and the World, 1 , 91–118.
Google Scholar
Javier, D. R. C., & Moorhouse, B. L. (2023). Developing secondary school English language learners’ productive and critical use of ChatGPT. TESOL Journal, (e755), 1–9.
Lee, A. V. Y., Luco, A. C., & Tan, S. C. (2023). A human-centric automated essay scoring and feedback system for the development of ethical reasoning. Educational Technology & Society, 26 (1), 147–159.
Liljequist, D., Elfving, B., & Skavberg Roaldsen, K. (2019). Intraclass correlation–A discussion and demonstration of basic features. PloS One, 14 (7), e0219854.
Marzuki, Widiati, U., Rusdin, D., Darwin, & Indrawati, I. (2023). The impact of AI writing tools on the content and organization of students’ writing: EFL teachers’ perspective. Cogent Education , 10 (2), 2236469.
Mizumoto, A., & Eguchi, M. (2023). Exploring the potential of using an AI language model for automated essay scoring. Research Methods in Applied Linguistics, 2 (2), 100050.
OpenAI (2023). ChatGPT: Optimizing language models for dialogue . Retrieved October 10, 2023, from https://openai.com/blog/chatgpt/
Ouyang, F., Zheng, L., & Jiao, P. (2022). Artificial intelligence in online higher education: A systematic review of empirical research from 2011 to 2020. Education and Information Technologies, 27 (6), 7893–7925.
Parker, J. L., Becker, K., & Carroca, C. (2023). ChatGPT for automated writing evaluation in scholarly writing instruction. Journal of Nursing Education, 62 (12), 721–727.
Powers, D. E., Escoffery, D. S., & Duchnowski, M. P. (2015). Validating automated essay scoring: A (modest) refinement of the gold standard. Applied Measurement in Education, 28 (2), 130–142.
Ramesh, D., & Sanampudi, S. K. (2022). An automated essay scoring systems: A systematic literature review. Artificial Intelligence Review, 55 (3), 2495–2527.
Ramineni, C. (2013). Validating automated essay scoring for online writing placement. Assessing Writing, 18 (1), 40–61.
Ramineni, C., & Williamson, D. M. (2013). Automated essay scoring: Psychometric guidelines and practices. Assessing Writing, 18 (1), 25–39.
Ray, P. P. (2023). ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 3 , 121–154.
Schade, M. (2023). How ChatGPT and our language models are developed . Retrieved October 28, 2023, from https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-language-models-are-developed
Schmidt-Fajlik, R. (2023). ChatGPT as a grammar checker for Japanese English language learners: A comparison with Grammarly and ProWritingAid. AsiaCALL Online Journal, 14 (1), 105–119.
Schober, P., Boer, C., & Schwarte, L. A. (2018). Correlation coefficients: Appropriate use and interpretation. Anesthesia & Analgesia, 126 (5), 1763–1768.
Shermis, M. D. (2014). State-of-the-art automated essay scoring: Competition, results, and future directions from a United States demonstration. Assessing Writing, 20 , 53–76.
Shermis, M. D., Koch, C. M., Page, E. B., Keith, T. Z., & Harrington, S. (2002). Trait ratings for automated essay grading. Educational and Psychological Measurement, 62 (1), 5–18.
Article MathSciNet Google Scholar
Su, Y., Lin, Y., & Lai, C. (2023). Collaborating with ChatGPT in argumentative writing classrooms. Assessing Writing, 57 , 100752.
Suppadungsuk, S., Thongprayoon, C., Miao, J., Krisanapan, P., Qureshi, F., Kashani, K., & Cheungpasitporn, W. (2023). Exploring the potential of chatbots in critical care nephrology. Medicines, 10 (10), 58.
Vo, Y., Rickels, H., Welch, C., & Dunbar, S. (2023). Human scoring versus automated scoring for English learners in a statewide evidence-based writing assessment. Assessing Writing, 56 , 100719.
Wang, J., & Brown, M. S. (2008). Automated essay scoring versus human scoring: A correlational study. Contemporary Issues in Technology and Teacher Education, 8 (4), 310–325.
Weigle, S. C. (2013). English language learners and automated scoring of essays: Critical considerations. Assessing Writing, 18 (1), 85–99.
Wilson, J., Chen, D., Sandbank, M. P., & Hebert, M. (2019). Generalizability of automated scores of writing quality in grades 3–5. Journal of Educational Psychology, 111 (4), 619–640. https://doi.org/10.1037/edu0000311
Yancey, K. P., Laflair, G., Verardi, A., & Burstein, J. (2023). Rating short L2 essays on the CEFR scale with GPT-4. In E. Kochmar, J. Burstein, A. Horbach, R. Laarmann-Quante, N. Madnani, A. Tack, V. Yaneva, Z. Yuan, & T. Zesch (Eds.), Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (pp. 576–584). Retrieved November 19, 2023, from https://aclanthology.org/2023.bea-1.49
Zawacki-Richter, O., Marín, V. I., Bond, M., & Gouverneur, F. (2019). Systematic review of research on artificial intelligence applications in higher education–where are the educators? International Journal of Educational Technology in Higher Education, 16 (1), 1–27.
Download references
This research is funded by the University of Economics Ho Chi Minh City, Vietnam.
Author information
Authors and affiliations.
School of Foreign Languages, University of Economics Ho Chi Minh City, Ho Chi Minh, Vietnam
Ngoc My Bui & Jessie S. Barrot
College of Education, Arts and Sciences, National University, Manila, Philippines
Jessie S. Barrot
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Jessie S. Barrot .
Ethics declarations
Ethics approval.
The study has undergone appropriate ethics protocol.
Consent to participate
Informed consent was sought from the participants.
Consent for publication
Authors consented the publication. Participants consented to publication as long as confidentiality is observed.
Competing interests
Additional information, publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Bui, N.M., Barrot, J.S. ChatGPT as an automated essay scoring tool in the writing classrooms: how it compares with human scoring. Educ Inf Technol (2024). https://doi.org/10.1007/s10639-024-12891-w
Download citation
Received : 10 January 2024
Accepted : 28 June 2024
Published : 13 July 2024
DOI : https://doi.org/10.1007/s10639-024-12891-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Generative AI
- Automated essay scoring
- Automated writing evaluation
- Argumentative essays
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
Artificial Intelligence (AI) must be directed at humane ends. The development of AI has produced great uncertainties of ensuring AI alignment with human values (AI value alignment) through AI operations from design to use. For the purposes of addressing this problem, we adopt the phenomenological theories of material values and technological mediation to be that beginning step. In this paper ...
Artificial Intelligence Will Change Human Value (s) Near-term AI advances ultimately will lead to a major societal shift. By Robert K. Ackerman. Mar 01, 2019. Peshkova/Shuttertock. The changes that artificial intelligence will bring to the technology landscape could pale in comparison to what it wreaks on global society.
The latter involves aligning artificial intelligence with the correct or best scheme of human values on a society-wide or global basis. While the minimalist view starts with the sound observation that optimizing exclusively for almost any metric could create bad outcomes for human beings, we may ultimately need to move beyond minimalist ...
Reboot AI with human values. A former head of the European Research Council urges critical thinking about the algorithms that shape our lives and societies. A security staff member wears augmented ...
Medical Artificial Intelligence and Human Values. ... that can be prompted to craft persuasive essays, 1 pass ... Dataset shift 62 refers to changes in the data characteristics that can undermine ...
These questions shed light on the role played by principles - the foundational values that drive decisions big and small in AI. For humans, principles help shape the way we live our lives and our sense of right and wrong. For AI, they shape its approach to a range of decisions involving trade-offs, such as the choice between prioritising ...
Artificial Intelligence (AI) must be directed at humane ends. The development of AI has produced great uncertainties of ensuring AI alignment with human values (AI value alignment) through AI ...
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but it remains unclear how to apply this to language models in practice. We split the problem of "aligning to human values" into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually ...
2022 Tanner Lecture on Artificial Intelligence and Human Values. Fei-Fei Li of Stanford University will deliver the 2022 Tanner Lecture on Human Values and Artificial Intelligence this fall at the Whitney Humanities Center.The lecture, "What We See and What We Value: AI with a Human Perspective," presents a series of AI projects—from work on ambient intelligence in healthcare to ...
Generative AI: A form of AI designed to produce new and original data outputs, including those that re-semble human-made content, with a range of out-put types that span text, code, images, audio ...
In an economy where data is changing how companies create value — and compete — experts predict that using artificial intelligence (AI) at a larger scale will add as much as $15.7 trillion to ...
Progress in the development of artificial intelligence (AI) opens up new opportunities for supporting and fostering autonomy, but it simultaneously poses significant risks. Recent incidents of AI ...
In 2020, the Center for AI and Digital Policy published the first worldwide assessment of AI policies and practices.Artificial Intelligence and Democratic Values rated and ranked 30 countries, based on a rigorous methodology and 12 metrics established to assess alignment with democratic values.. The 2021 Report expands the global coverage from 30 countries to 50 countries, acknowledges the ...
Researchers predict that AI will outperform humans in translating languages by 2024, writing high-school essays by 2026, driving a truck by 2027, or working as a surgeon by 2053; they believe there is a 50 per cent chance of AI outperforming humans in all tasks within 45 years and of automating all human jobs in 120 years (Grace et al., 2018 ...
Value Alignment. Today, we start with the Value Alignment principle. Value Alignment: Highly autonomous AI systems should be designed so that their goals and behaviors can be assured to align with human values throughout their operation. Stuart Russell, who helped pioneer the idea of value alignment, likes to compare this to the King Midas story.
The rapid development of artificial intelligence (AI) poses exciting possibilities as well as ethical challenges. As AI systems become more sophisticated and integrated into our lives, ensuring they align with human values and interests becomes imperative. But how can we achieve this goal? Alignment refers to developing AI that behaves in accordance with the preferences,
Modelling Human Values for AI Reasoning. Nardine Osman, Mark d'Inverno. One of today's most significant societal challenges is building AI systems whose behaviour, or the behaviour it enables within communities of interacting agents (human and artificial), aligns with human values. To address this challenge, we detail a formal model of human ...
Tartu 50090, Estonia. Email: [email protected]. Abstract: As arti cial intelligence (AI) systems are becoming increasingly. autonomous and will soon be able to make decisions on their own about ...
1 Sheila Jasanoff, The Ethics of Invention: Technology and the Human Future (WW Norton & Company, 1st edn 2016) 7 ('New technologies such as gene modification, artificial intelligence and robotics have the potential to infringe on human dignity and compromise core values of being human.').
In artificial intelligence (AI), the "alignment problem" refers to the challenges caused by the fact that machines simply do not have the same values as us. In fact, when it comes to values ...
Researchers at the University of Cambridge's Leverhulme Centre for the Future of Intelligence (LCFI) have been awarded nearly €2m to build a better understanding of how AI can undermine "core human values".
Abstract. Artificial intelligence (AI) is increasingly affecting our lives in smaller or greater ways. In order to ensure that systems will uphold human values, design methods are needed that incorporate ethical principles and address societal concerns. In this paper, we explore the impact of AI in the case of the expected effects on the ...
Artificial Intelligence (232) Competition (39) Cybersecurity (4) Data Governance (282) Democracy (438) Digital Economy (85) Digital Governance (6) Digital Rights (2) Financial Governance (634) Foreign Interference (4) Freedom of Thought (1) G20/G7 (315) Gender (118) Geopolitics (438) Global Cooperation (4) Human Rights (132) Intellectual ...
As a result, Explainable Artificial Intelligence (XAI) has emerged as a relevant research field aiming to develop methods and techniques that allow stakeholders to understand the inner workings and outcome of deep learning-based systems (Gunning et al., 2019; Arrieta et al., 2020).
In this essay, I argue that explicit ethical machines, whose moral principles are inferred through a bottom-up approach, are unable to replicate human-like moral reasoning and cannot be considered moral agents. By utilizing Alan Turing's theory of computation, I demonstrate that moral reasoning is computationally intractable by these machines due to the halting problem. I address the frontiers ...
The dangers in algorithms learning humans' values and irrationalities. Rebecca Gorman, Stuart Armstrong. For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and ...
Recent developments in artificial intelligence (AI) and natural language processing (NLP) have given rise to state-of-the-art systems that are revolutionizing teaching, learning, and assessment (An et al., 2023; Ouyang et al., 2022; Weigle, 2013).Among these advancements is automated essay scoring (AES), which involves the process of assigning scores to student essays without human ...